 | Programming the Perl DBI |  |

Issuing Simple Queries
Executing Non-SELECT Statements
Binding Parameters to Statements
Binding Output Columns
do( ) Versus prepare( )
Atomic and Batch Fetching
In our journey through the DBI so far, we have discussed ways in which you can connect and disconnect from databases of various types within Perl programs. We have also discussed ways in which you can detect and rectify errors when calling DBI methods.
What we haven't discussed yet is how to manipulate data within your databases: that is, retrieving, updating, and deleting information (amongst other activities). This chapter discusses how to perform these activities with the DBI and how to use Perl's powerful data manipulation functionality to efficiently manipulate your data.
Recall the discussion in Chapter 4, "Programming with the DBI " about the architecture of DBI -- specifically, the topic of statement handles. These handles, and the methods associated with them, provide the functionality to manipulate data within your databases.
The most common interaction between a program and a database is retrieving or fetching data. In standard SQL, this process is performed with the SELECT keyword. With Perl and the DBI, we have far more control over the way in which data is retrieved from the database. We also have far more control over how to post-process the fetched data.
Retrieving data from a database using DBI is essentially a four-stage cycle:
The prepare stage parses an SQL statement, validates that statement, and returns a statement handle representing that statement within the database.
Providing the prepare stage has returned a valid statement handle, the next stage is to execute that statement within the database. This actually performs the query and begins to populate data structures within the database with the queried data. At this stage, however, your Perl program does not have access to the queried data.
The third stage is known as the fetch stage, in which the actual data is fetched from the database using the statement handle. The fetch stage pulls the queried data, row by row, into Perl data structures, such as scalars or hashes, which can then be manipulated and post-processed by your program.
The fetch stage ends once all the data has been fetched, or it can be terminated early using the finish() method.
If you'll need to re-execute() your query later, possibly with different parameters, then you can just keep your statement handle, re-execute() it, and so jump back to stage 2.
The final stage in the data retrieval cycle is the deallocation stage. This is essentially an automatic internal cleanup exercise in which the DBI and driver deallocate the statement handle and associated information. For some drivers, that process may also involve talking to the database to tell it to deallocate any information it may hold related to the statement.
All this is done for you automatically, triggered by Perl's own garbage collection mechanism.
This cycle occurs for every SQL SELECT statement executed. For other SQL statements, such as INSERT, UPDATE, and DELETE, the fetch is skipped and only the prepare, execute, and deallocation stages apply (as we'll discuss later in this chapter).
To understand how this four-stage data fetch cycle fits into your programs, we'll take a closer look at each stage individually.
The first stage of the cycle to retrieve data from your database is to prepare the statement handle from an SQL statement. This stage generally corresponds to the parse stage that occurs internally within your database engine.
What typically occurs is that the SQL statement is sent as a string of characters via a valid database handle to the database. This string is then parsed by the database itself to ensure that it is valid SQL, both in terms of syntax and also in terms of entities referred to within the database (e.g., to make sure you aren't referring to tables that don't exist and that you have permission to refer to those that do).
Provided that the database swallows this statement without any complaints, it will return some sort of database-specific data structure that encapsulates that parsed statement. It is this database-specific data structure that the DBI further encapsulates as a statement handle. Figure 5-1 shows this process more clearly.
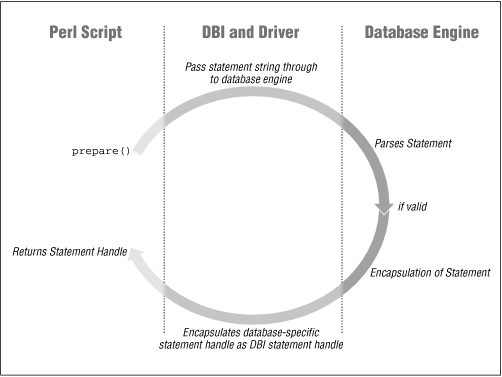
It is through this DBI statement handle that you perform the remainder of the data-fetching cycle.
In DBI terms, the way to prepare a statement is to use the prepare() method, which is executed via a database handle. For example, a simple DBI program that creates a statement handle can be written as follows:
#!/usr/bin/perl -w # # ch05/prepare/ex1: Simply creates a database handle and a statement handle use DBI; ### The database handle my $dbh = DBI->connect( "dbi:Oracle:archaeo", "username", "password" ); ### The statement handle my $sth = $dbh->prepare( "SELECT id, name FROM megaliths" ); exit;
This, of course, assumes that all goes well with the parsing of the statement. It is possible that you made a mistake when typing in your SQL statement, or that the database failed to parse the statement for any number of other reasons. If this occurs, a value of undef is returned from the prepare() call, signifying that the parse has failed.
In addition to this return value, the DBI would also print out an error message because the PrintError attribute is enabled by default on database handles from DBI->connect(). See Chapter 4, "Programming with the DBI " for more about PrintError.
Finally, there's an important twist to preparing statements, in that drivers are allowed to defer actually doing the prepare stage of the cycle until execute() is called. That's because some databases don't provide any other way of doing it. So everything that's been said about prepare() -- what it does and why it may fail -- may actually not apply until execute() is called.
It is also possible to construct ``on-the-fly'' SQL statements using Perl's built-in string handling capabilities, which can then be passed to prepare( ). A good example of this functionality can be demonstrated using DBI to integrate databases and web sites.
Suppose you had your megalith database available on the Web for easy online browsing. When a user types in the name of a site, it gets passed into a CGI script in the form of a string. This string is then used in an SQL statement to retrieve the appropriate information on the site from the database.
Therefore, to be able to accomplish this sort of interactivity, you need to be able to custom-build SQL statements, and using Perl's string handling is one way to do it.[45] The following code illustrates the principle:
[45]A frequently better way is to use bind values, which we'll discuss later in this chapter.
### This variable is populated from the online form, somehow...
my $siteNameToQuery = $CGI->param( "SITE_NAME" );
### Take care to correctly quote it for use in an SQL statement
my $siteNameToQuery_quoted = $dbh->quote( $siteNameToQuery );
### Now interpolate the variable into the double-quoted SQL statement
$sth = $dbh->prepare( "
SELECT meg.name, st.site_type, meg.location, meg.mapref
FROM megaliths meg, site_types st
WHERE name = $siteNameToQuery_quoted
AND meg.site_type_id = st.id
" );
$sth->execute( );
@row = $sth->fetchrow_array( );
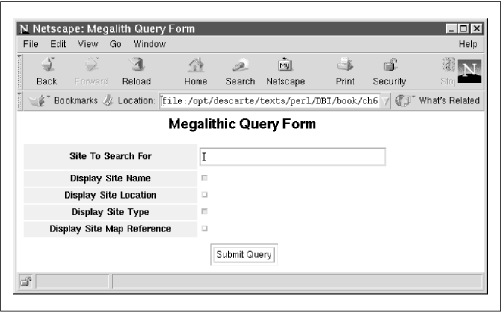
...Furthermore, any part of this query can be constructed on the fly since the SQL statement is, at this stage, simply a Perl string. Another neat trick is to adaptively query columns from the database depending on which fields the online browser wants to display. Figure 5-1 shows the web page from which the user selects his or her desired columns.
The code required to drive this form of SQL generation can be written neatly as:
### Collect the selected field names
@fields = ();
### Work out which checkboxes have been selected
push @fields, "name" if $nameCheckbox eq "CHECKED";
push @fields, "location" if $locationCheckbox eq "CHECKED";
push @fields, "type" if $typeCheckbox eq "CHECKED";
push @fields, "mapref" if $maprefCheckbox eq "CHECKED";
### Sanity-check that *something* was selected
die "No fields were selected for querying!\n"
unless @fields;
### Now build the SQL statement
$statement = sprintf "SELECT %s FROM megaliths WHERE name = %s",
join(", ", @fields), $dbh->quote($siteNameToQuery);
### Perform the query
$sth = $dbh->prepare( $statement );
$sth->execute();
@row = $sth->fetchrow_array();
...That is, the entire SQL query, from the columns to fetch to the conditions under which the data is fetched, has been constructed dynamically and passed to the database for processing.
The web page that was displayed on the user's browser after executing this query can be seen in Figure 5-2.
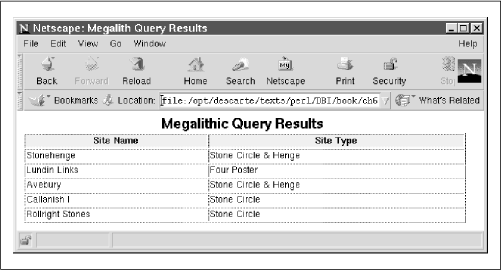
Therefore, by using Perl's string handling to build SQL statements based on input from the user, DBI can be used to drive quite complex web forms in a very simple and flexible manner.
The second stage of the data fetch cycle is to inform the database to go ahead and execute the SQL statement that you have prepared. This execution stage will actually tell the database to perform the query and begin to collect the result set of data.
Performing the execution of the SQL statement occurs via a valid statement handle created when the prepare() method successfully completes. For example, execution of an SQL statement can be expressed as simply as:
### Create the statement handle my $sth = $dbh->prepare( "SELECT id, name FROM megaliths" ); ### Execute the statement handle $sth->execute();
Assuming that all goes well with the execution of your statement, a true value will be returned from the execute() call. Otherwise, a value of undef is returned, signifying that the execution has failed.
As with most DBI methods, if PrintError is enabled, then an error message will be generated via warn() . Alternatively, if RaiseError is enabled, an exception will be generated via die() . However you choose to do it, it is always a good idea to check for errors.[46]
[46]We sometimes don't explicitly check for errors in the fragments of code we use as examples. In these cases, you can safely assume that we're strapped into our RaiseError ejector seat.
After execute() returns successfully, the database has not necessarily completed the execution of the SELECT statement; it may have only just started. Imagine that megaliths are very common, and our megaliths table has ten million rows. In response to the execute() earlier, the database may do no more than set a pointer, known as a cursor, to just above the first row of the table.
So, after successful execution, the database and driver are ready to return the results, but those results will not have been returned to your Perl program yet. This is an important point to remember. To extract the results data from the database, you need to explicitly fetch them. This is the third stage in the cycle.
Fetching data is the main object of issuing queries to the database. It's fine to exercise a database by executing queries, but unless you actually retrieve that data, your program will never be able to make use of it.
The data retrieved by your SQL query is known as a result set (so called because of the mathematical set theory on which relational databases are based). The result set is fetched into your Perl program by iterating through each record, or row, in the set and bringing the values for that row into your program. This form of fetching result set data on a row-by-row basis is generally termed a cursor .
Cursors are used for sequential fetching operations: records are fetched in the order in which they are stored within the result set. Currently, records cannot be skipped over or randomly accessed. Furthermore, once a row addressed by a cursor has been fetched, it is ``forgotten'' by the cursor. That is, cursors cannot step backwards through a result set.
Therefore, the general way in which we fetch data from the database's result set is to loop through the records returned via the statement handle, processing each row until no rows are left to fetch. This can be expressed by the following pseudo-code.
while ( records to fetch from $sth ) {
### Fetch the current row from the cursor
@columns = get the column values;
### Print it out...
print "Fetched Row: @columns\n";
}The DBI simplifies this process even further by combining the check for more data and the fetching of that data into a single method call.
There are several ways in which rows can be retrieved from the result set using different Perl datatypes. For example, you can fetch a row in the form of a simple list of values, a reference to an array of values, or a reference to a hash of field-name/value pairs. All essentially retrieve the current row from the cursor, but return the data to your Perl program in different formats.
The simplest form of data fetching is to use the fetchrow_array() method, which returns an array, or rather a list, containing the fields of the row. Let's say that we wanted to fetch the name of a megalithic site and what sort of site it is from our megaliths database. Therefore, to fetch this data from the table, we would write:
### Prepare the SQL statement ( assuming $dbh exists )
$sth = $dbh->prepare( "
SELECT meg.name, st.site_type
FROM megaliths meg, site_types st
WHERE meg.site_type_id = st.id
" );
### Execute the SQL statement and generate a result set
$sth->execute();
### Fetch each row of result data from the database as a list
while ( ( $name, $type ) = $sth->fetchrow_array ) {
### Print out a wee message....
print "Megalithic site $name is a $type\n";
}You could also fetch the data via fetchrow_array() into an array variable instead of a list of scalar variables by writing:
while ( @row = $sth->fetchrow_array ) {
### Print out a wee message
print "Megalith site $row[0] is a $row[1]\n";
}which is functionally identical.
The fundamentally important thing to remember is that the fields in the result set are in the order in which you asked for the columns in the SQL statement. Therefore, in the example code listed above, the name field was requested before the site_type field. This ensured that the first element of the array or scalar list was the value of the name field, followed by the values of the site_type field.
The while loop keeps looping until the expression in parentheses evaluates to false. Naturally, we want to stop looping when there's no more data to fetch, and the fetchrow_array() method arranges that for us. It returns an empty list when there's no more data. Perl treats that as a false value, thus stopping the loop.
An important point to remember about fetch loops is that the fetch methods return the same value for both the no-more-data condition and an error condition. So an error during fetching will cause the loop to exit as if all the data had been fetched. When not using RaiseError, it's therefore good practice to check for the occurrence of errors immediately after every loop exits. The example below demonstrates this.[47]
[47]Other fetch loop examples in the book assume that RaiseError is enabled.
Another way in which you can fetch the data from the database is to use the fetchrow_arrayref() method, which returns a reference to an array rather than an array itself. This method has a performance benefit over fetchrow_array(), as the returned data is not copied into a new array for each row fetched. For example:
### Fetch the rows of result data from the database
### as an array ref....
while ( $array_ref = $sth->fetchrow_arrayref ) {
### Print out a wee message....
print "Megalithic site $arrayref->[0] is a $array_ref->[1]\n";
}
die "Fetch failed due to $DBI::errstr" if $DBI::err;An important thing to watch out for is that currently the same array reference is used for all rows fetched from the database for the current statement handle. This is of utmost importance if you are storing the row data somewhere for future reference. For example, the following code was written to stash the returned megalith data in a persistent store for future reference after fetching:
### The stash for rows...
my @stash;
### Fetch the row references and stash 'em!
while ( $array_ref = $sth->fetchrow_arrayref ) {
push @stash, $array_ref; # XXX WRONG!
}
### Dump the stash contents!
foreach $array_ref ( @stash ) {
print "Row: @$array_ref\n";
}Something very strange happens here. All the rows printed out from the stash are identical instead of being different. This is because you've stored the reference to the row data instead of the row data itself, and since DBI reuses the same reference for each row, you don't quite get the results you expect. Be sure to store a copy of the values that the array reference points to rather than the reference itself, as this example shows:
### The stash for rows...
my @stash;
### Fetch the row references and stash 'em!
while ( $array_ref = $sth->fetchrow_arrayref ) {
push @stash, [ @$array_ref ]; # Copy the array contents
}
### Dump the stash contents!
foreach $array_ref ( @stash ) {
print "Row: @$array_ref\n";
}The fetchrow_arrayref() method is used especially in conjunction with column binding, which we shall discuss later in this chapter.
The final cursor-based way to fetch the rows of your result set data from the database is to grab it as a hash reference. This functionality is implemented via the fetchrow_hashref() method, which is used in the same way as fetchrow_arrayref(). For example:
### Fetch the current row into a hash reference
while ( $hash_ref = $sth->fetchrow_hashref ) {
...The hash pointed to by the reference has the names of the fetched fields as the keys to the hash, and the values of those fields are stored as the hash values. Thus, if we fetched the name and site_type fields from the database, we could address the hash elements like this:
### Fetch rows into a hash reference
while ( $hash_ref = $sth->fetchrow_hashref ) {
print "Megalithic site $hash_ref->{name} is a $hash_ref->{site_type}\n";
}There are, as you might expect, a few caveats to using this particular method. The most important thing to watch out for is the actual name of the field that you've fetched. Some databases will do strange things to the field name, such as convert it to all uppercase or all lowercase characters, which could cause you to access the wrong hash key. You can avoid this problem by telling fetchrow_hashref() the name of the attribute to use to supply the field names. That is, you could use NAME as the default; NAME_uc to force field names to be uppercase; and NAME_lc to force them to be lowercase. For example, a portable way to use hash references can be written as:
### Fetch rows into a hash reference with lowercase field names
while ( $hash_ref = $sth->fetchrow_hashref('NAME_lc') {
print "Megalithic site $hash_ref->{name} is a $hash_ref->{site_type}\n";
}Specifying NAME_uc or NAME_lc is recommended, and doesn't have any impact on performance.
There are a couple more caveats with fetchrow_hashref() that we should discuss. If your SELECT statement uses a fully qualified field name, such as:
SELECT megaliths.id, ...
then most databases will still return only the string id as the name of the field. That's not usually a problem but can trip you up if you have selected more than one field with the same name, for example:
SELECT megaliths.id, media.id ...
Since the hash returned by fetchrow_hashref() can have only one id key, you can't get values for both fields. You can't even be sure which of the two id field values you've got. Your only options here are to either use a different method to fetch the rows or to alias the column names. Aliasing the columns is similar to aliasing the table names, which we discussed in Chapter 3, "SQL and Relational Databases ". You can put an alias name after the column expression:
SELECT megaliths.id meg_id, media.id med_id ...
though some databases require the slightly more verbose form:
SELECT megaliths.id AS meg_id, media.id AS med_id ...
This alias technique is also very handy when selecting expressions such as:
SELECT megaliths.id + 1 ...
because databases differ in how they name columns containing expressions. Using aliases not only makes it easier to refer to the columns but also makes your application more portable.
When discussing fetchrow_arrayref(), we pointed out that it currently returns the same array reference for each row. Well, fetchrow_hashref() currently doesn't return the same hash reference for each row but definitely will in a future release. (This change will also make it faster, as it's a little slower than we'd like at the moment.)
There are other techniques for fetching data from the database, but these deal with either batch fetching or atomic fetching and are discussed later in this chapter.
The DBI supports a utility method called dump_results( ) for fetching all of the rows in a statement handle's result set and printing them out. This method is invoked via a prepared and executed statement handle, and proceeds to fetch and print all the rows in the result set from the database. As each line is fetched, it is formatted according either to default rules or to rules specified by you in your program. Once dump_results( ) has finished executing, it prints the number of rows fetched from the database and any error message. It then returns with the number of rows fetched.
For example, to quickly display the results of a query, you can write:
$sth = $dbh->prepare( "
SELECT name, mapref, location
FROM megaliths
" );
$sth->execute( );
$rows = $sth->dump_results( );which would display the following results:
'Balbirnie', 'NO 285 029', 'Balbirnie Park, Markinch, Fife' 'Castlerigg', 'NY 291 236', 'Near Keswick, Cumbria, England' 'Sunhoney', 'NJ 716 058', 'Near Insch, Aberdeenshire' 'Avebury', 'SU 103 700', 'Avebury, Wiltshire, England' 4 rows
You can customize the way in which this output is formatted by specifying the maximum length of each field within the row, the characters separating each field within the row, and the characters separating each row. You can also supply a Perl filehandle to which the output is written.
The default settings for these parameters are:
1: Maximum Field Length - 35 2: Line Separator - "\n" 3: Field Separator - "," 4: Output file handle - STDOUT
Therefore, to generate output with 80 character fields separated by colons to a file, you can write:
### Prepare and execute the query
$sth = $dbh->prepare( "
SELECT name, location, mapref
FROM megaliths
" );
$sth->execute( );
### Open the output file
open FILE, ">results.lis" or die "Can't open results.lis: $!";
### Dump the formatted results to the file
$rows = $sth->dump_results( 80, '\n', ':', \*FILE );
### Close the output file
close FILE or die "Error closing result file: $!\n";dump_results( ) internally uses the neat_list( ) utility function (described in the previous chapter) for the actual formatting operation. Because of this, you should not use the output of dump_results( ) for any data transfer or data processing activity. It's only meant for human consumption.
When a statement handle for a SELECT statement has been successfully executed, it is said to be active. There's even a boolean statement handle attribute called Active that you can read. Being active simply means that there's something actively going on within the database server on behalf of this handle.
When you call a fetch method again, after fetching the last row of data, the driver automatically finishes whatever is actively going on within the database server on behalf of this execute() and resets the Active attribute. Most drivers don't actually have to do anything in this particular case because the server knows that the driver has fetched the last row. So the server has automatically freed up any resources it was using to store that result set.
Since this finishing-up is done automatically when a fetch method returns an end-of-data status, there's usually no need to be aware of it. However, there are two types of situations where it's appropriate to take matters into your own hands by calling the finish() method on the statement handle. (Keep in mind that finish() doesn't "finish" the statement handle itself -- it finishes only the current execution of it. You can still call execute() on the handle again later.)
The first situation is a little obscure and relates to being a good database-citizen. If the database server is using a significant amount of temporary disk space to hold your result set, and you haven't fetched all the records, and you won't be destroying or re-executing the statement handle soon, then it's appropriate to call finish(). That way, the server can free up the temporary disk space it's holding for your results.[48]
[48]A classic example is SELECT dialled_number, count(*) FROM calls WHERE subscriber = ? GROUP BY dialled_number ORDER BY count(*) DESC when you only want to fetch the first few rows out of the thousands that the database has stored in temporary buffer space and sorted for you.
The second type of situation is less obscure, mainly because the DBI nags you about it by issuing warnings like this one from disconnect( ):
disconnect invalidates 1 active statement handle (either destroy statement handles or call finish on them before disconnecting)
What's happening here is that the DBI is warning you that an active statement handle, that may still have data to be fetched from it, is being invalidated (i.e., made unusable) by disconnecting from the database.
Why does the DBI bother to warn you? The idea is to help you spot cases where you have not caught and dealt with an error from a fetch method that has terminated a fetch loop before all the data has been retrieved. Some row fetch errors, such as a transaction being aborted, mean that it's not possible for more rows to be fetched from that statement handle. In those cases, the driver resets the Active flag. For others though, such as a divide-by-zero in a column expression, or a long field value being truncated, further rows can be fetched, so the driver leaves the Active flag set.
In practice, there are other situations apart from fetch loops that can leave you with active statement handles both in the normal flow of events and due to exceptional circumstances.
The most humble is the common desire to fetch only n rows because you know there are only n rows to be fetched. Most drivers can't tell that you've fetched the last row, so they can't reset the Active flag. This is similar to the "good database-citizen" situation we discussed earlier. The following example shows the finish( ) method being called after fetching the one and only row of interest:
sub select_one_row {
my $sth = shift;
$sth->execute(@_) or return;
my @row = $sth->fetchrow_array( );
$sth->finish( );
return @row;
}A more exceptional situation is often related to using RaiseError . When an exception is thrown, such as when the DBI detects an error on a handle with RaiseError set, or when any other code calls die( ) , then the flow of control within your script takes a sudden leap from where it was up to the nearest enclosing eval block. It's quite possible that this process may leave handles with unfinished data.
The warning from disconnect( ) , and most other DBI warnings, can be silenced for a given handle by resetting the Warn attribute of that handle. This practice is generally frowned upon, but if you must, you can.
Remember that calling finish( ) is never essential, does not destroy the Perl statement handle object itself, is not required to avoid leaks, and does not stop execute( ) being called again on the handle. All of those are common misconceptions, often perpetuated in other books. We'll discuss how statement handles actually do get destroyed in the next section.
When a statement is prepared, the returned statement handle is associated with allocated memory resources within both your Perl script and the database server you're connected to. When you no longer need a statement handle, you should destroy it. That sounds drastic, but all it really means is letting go.
Statement handles are actually represented by Perl objects and, as such, are subject to the machinations of Perl's garbage collector. This implies that when no references to a statement handle remain (for example, the handle variable has gone out of scope or has been overwritten with a new value), Perl itself will destroy the object and reclaim the resources used by it.
Here's an example of a short-lived statement handle:
if ($fetch_new_data) {
my $sth = $dbh->prepare( ... );
$sth->execute( );
$data = $sth->fetchall_arrayref( );
}Notice that we don't have to make any explicit steps to free or deallocate the statement handle. Perl is doing that for us. The my $sth variable holds the only reference to that particular statement handle object. When the $sth variable ceases to exist at the end of the block, the last reference is removed and Perl's garbage collector swings into action. Similarly, when the script exits, all global variables cease to exist and any objects they refer to are deallocated in the same way.
Here's a slightly different example:
### Issue SQL statements to select sites by type
foreach ( 'Stone Circle', 'Monolith', 'Henge' ) {
my $sth = $dbh->prepare( ... $_ ... );
$sth->execute( );
$sth->dump_results( );
}The second and subsequent itterations of the loop assign a new statement handle reference to the $sth variable, which deletes the reference it previously held. So once again, since that was the only reference to the handle and it's now been deleted, the handle gets deallocated.
You might have an application that prepares, uses, and discards thousands (or hundreds of thousands) of statement handles throughout its lifetime. If the database resources for the statements were not freed until the database connection was closed, you could easily exhaust the database resources in a short amount of time.
In practice, the only time that you might overload the database is when you're storing the statement handles in arrays or hashes. If you're not careful to delete or overwrite old values, then handles can accumulate.
To keep track of how many statement handles are allocated for a database handle (for example, to help spot leaks), you can use the Kids and ActiveKids database handle attributes. Both of these will return integer counts. The first counts all statement handles; the second counts only those that have their Active attribute set.
|  | |
| 4.6. Utility Methods and Functions |  | 5.2. Executing Non-SELECT Statements |

Copyright © 2001 O'Reilly & Associates. All rights reserved.
| This HTML Help has been published using the chm2web software. |