9.5. Network DesignA well-designed network is the basis for all other security efforts. Though we are dealing with Apache security here, our main subject alone is insufficient. Your goal is to implement a switched, modular network where services of different risk are isolated into different network segments. Figure 9-1 illustrates a classic demilitarized zone (DMZ) network architecture. Figure 9-1. Classic DMZ architecture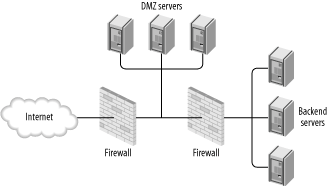 This architecture assumes you have a collection of backend servers to protect and also assumes danger comes from one direction only, which is the Internet. A third zone, DMZ, is created to work as an intermediary between the danger outside and the assets inside. Ideally, each service should be isolated onto its own server. When circumstances make this impossible (e.g., financial reasons), try not to combine services of different risk levels. For example, combining a public email server with an internal web server is a bad idea. If a service is not meant to be used directly from the outside, moving it to a separate server would allow you to move the service out of the DMZ and into the internal LAN. For complex installations, it may be justifiable to create classes of users. For example, a typical business system will operate with:
With proper planning, each of these user classes can have its own DMZ, and each DMZ will have different privileges with regards to access to the internal LAN. Multiple DMZs allow different classes of users to access the system via different means. To participate in high-risk systems, partners may be required to access the network via a virtual private network (VPN). To continue to refine the network design, there are four paths from here:
9.5.1. Reverse Proxy PatternsSo far I have discussed the mechanics of reverse proxy operation. I am now going to describe usage patterns to illustrate how and why you might use the various types of reverse proxies on your network. Reverse proxies are among the most useful tools in HTTP network design. None of their benefits are HTTP-specificit is just that HTTP is what we are interested in. Other protocols benefit from the same patterns I am about to describe. The nature of patterns is to isolate one way of doing things. In real life, you may have all four patterns discussed below combined onto the same physical server. For additional coverage of this topic, consider the following resources:
9.5.1.1 Front doorThe front door reverse proxy pattern should be used when there is a need to implement a centralized access policy. Instead of allowing external users to access web servers directly, they are directed through a proxy. The front-door pattern is illustrated in Figure 9-2. Figure 9-2. Front door reverse proxy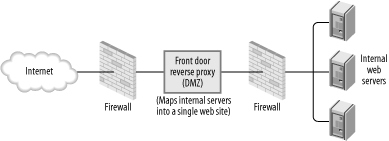 This pattern has two benefits:
The front door reverse pattern is most useful in loose environments; for example, those of software development companies where developers have control over development servers. Allowing clients to access the applications as they are being developed is often necessary. Firewalls often do not offer enough granularity for giving privileges, and having an unknown number of servers running on a network is very bad for security. 9.5.1.2 Integration reverse proxyThe configuration of an integration reverse proxy, illustrated in Figure 9-3, is similar to that of a front door pattern, but the purpose is completely different. The purpose of the integration reverse proxy is to integrate multiple application parts (often on different servers) into one unique application space. There are many reasons for doing this:
Figure 9-3. Integration reverse proxy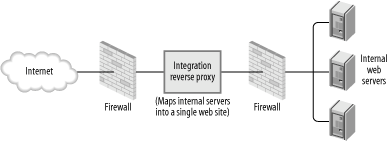 Basically, this pattern allows a messy configuration that no one wants to touch to be transformed into a well-organized, secured, and easy-to-maintain system. There are two ways to use this pattern. The obvious way is to hide the internal workings of a system and present clients with a single server. But there is also a great benefit of having a special internal integration proxy to sort out the mess inside. In recent years there has been a lot of talk about web services. Systems are increasingly using port 80 and the HTTP protocol for internal communication as a new implementation of remote procedure calling (RPC). Technologies such as REST, XML-RPC, and SOAP (given in the ascending level of complexity) belong to this category. Allowing internal systems to communicate directly results in a system where interaction is not controlled, logged, or monitored. The integration reverse proxy pattern brings order. 9.5.1.3 Protection reverse proxyA protection reverse proxy, illustrated in Figure 9-4, greatly enhances the security of a system:
Figure 9-4. Protection reverse proxy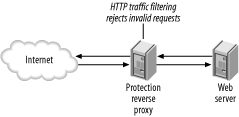 The protection reverse proxy is useful when you must maintain an insecure, proprietary, or legacy system. Direct exposure to the outside world could lead to a compromise, but putting such systems behind a reverse proxy would extend their lifetime and allow secure operation. A protection reverse proxy can also actually be useful for all types of web applications since they can benefit from having an HTTP firewall in place, combined with full traffic logging for auditing purposes. 9.5.1.4 Performance reverse proxyFinally, you have a good reason to introduce a reverse proxy to increase overall system performance. With little effort and no changes to the actual web server, a reverse proxy can be added to perform the following operations (as seen in Figure 9-5):
Figure 9-5. Performance reverse proxy Moving these operations to the separate server frees the resources on the web server to process requests. Moreover, the web server (or the application) may not be able to support these operations. Because the reverse proxy operates on the HTTP level, the additional functionality can be introduced in front of a web server of any type. 9.5.2. Advanced ArchitecturesThere are three reasons why you would concern yourself with advanced HTTP architectures:
It would be beneficial to define relevant terms first (this is where Wikipedia, http://www.wikipedia.org, becomes useful):
We will cover the advanced architectures as a journey from a single-server system to a scalable and highly available system. The application part of the system should be considered during the network design phase. There are too many application-dependent issues to leave them out of this phase. Consult the following for more information about application issues related to scalability and availability:
The following sections describe various advanced architectures. 9.5.2.1 No load balancing, no high availabilityAt the bottom of the scale we have a single-server system. It is great if such a system works for you. Introducing scalability and increasing availability of a system involves hard work, and it is usually done under pressure and with (financial) constraints. So, if you are having problems with that server, you should first look into ways to enhance the system without changing it too much:
If you have done all of this and you are still on the edge of the server's capabilities, then look into replacing the server with a more powerful machine. This is an easy step because hardware continues to improve and drop in price. The approach I have just described is not very scalable but is adequate for many installations that will never grow to require more than one machine. There remains a problem with availabilitynone of this will increase the availability of the system. 9.5.2.2 High availabilityA simple solution to increase availability is to introduce resource redundancy by way of a server mirror (illustrated in Figure 9-6). Create an exact copy of the system and install software to monitor the operations of the original. If the original breaks down for any reason, the mirrored copy becomes active and takes over. The High-Availability Linux Project (http://linux-ha.org) describes how this can be done on Linux. Figure 9-6. Two web servers in a high availability configuration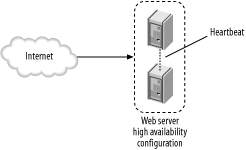 A simple solution such as this has its drawbacks:
9.5.2.3 Manual load balancingSuppose you have determined that a single server is not enough to cope with the load. Before you jump to creating a cluster of servers, you should consider several crude but often successful techniques that are referred to as manual load balancing. There are many sites happily working like this. Here are three techniques you can use:
So, we can handle a load increase up to a certain point this way but we are worse off from the availability point of view. More machines in a system translate into more points of failure. Still, if some downtime is acceptable, then standardizing on the hardware and keeping a spare machine at all times should keep you going. 9.5.2.4 DNS Round Robin (DNSRR) load balancingA cluster of servers (see Figure 9-7) provides scalability, high availability, and efficient resource utilization (load balancing). First, we need to create a cluster. An ideal cluster consists of N identical servers, called (cluster) nodes. Each node is capable of serving a request equally well. To create consistency at the storage level, one of the following strategies can be used:
Figure 9-7. DNS Round Robin cluster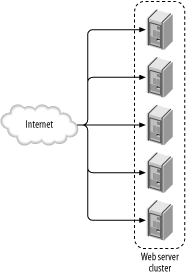 After creating a cluster, we need to distribute requests among cluster nodes. The simplest approach is to use a feature called DNS Round Robin (DNSRR). Each node is given a real IP address, and all IP addresses are associated with the same domain name. Before a client can make a request, it must resolve the domain name of the cluster to an IP address. The following query illustrates what happens during the resolution process. This query returns all IP addresses associated with the specified domain name: $ dig www.cnn.com ; <<>> DiG 9.2.1 <<>> www.cnn.com ;; global options: printcmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 38792 ;; flags: qr rd ra; QUERY: 1, ANSWER: 9, AUTHORITY: 4, ADDITIONAL: 4 ;; QUESTION SECTION: ;www.cnn.com. IN A ;; ANSWER SECTION: www.cnn.com. 285 IN CNAME cnn.com. cnn.com. 285 IN A 64.236.16.20 cnn.com. 285 IN A 64.236.16.52 cnn.com. 285 IN A 64.236.16.84 cnn.com. 285 IN A 64.236.16.116 cnn.com. 285 IN A 64.236.24.4 cnn.com. 285 IN A 64.236.24.12 cnn.com. 285 IN A 64.236.24.20 cnn.com. 285 IN A 64.236.24.28 Here you can see the domain name www.cnn.com resolves to eight different IP addresses. If you repeat the query several times, you will notice the order in which the IP addresses appear changes every time. Hence the name "round robin." Similarly, during domain name resolution, each client gets a "random" IP address from the list. This leads to the total system load being distributed evenly across all cluster nodes. But what happens when a cluster node fails? The clients working with the node have already resolved the name, and they will not repeat the process. For them, the site appears to be down though other nodes in the cluster are working. One solution for this problem is to dynamically modify the list of IP addresses in short intervals, while simultaneously shortening the time-to-live (TTL, the period during which DNS query results are to be considered valid). If you look at the results of the query for www.cnn.com, the TTL is set to 285 seconds. In fact, CNN domain name servers regenerate the list every five minutes. When a node fails, its IP address will not appear on the list until it recovers. In that case, one portion of all clients will experience a downtime of a couple of minutes. This process can be automated with the help of Lbnamed, a load-balancing name server written in Perl (http://www.stanford.edu/~schemers/docs/lbnamed/lbnamed.html). Another solution is to keep the DNS static but implement a fault-tolerant cluster of nodes using Wackamole (http://www.backhand.org/wackamole/). Wackamole works in a peer-to-peer fashion and ensures that all IP addresses in a cluster remain active. When a node breaks down, Wackamole detects the event and instructs one of the remaining nodes to assume the lost IP address. The DNSRR clustering architecture works quite well, especially when Wackamole is used. However, a serious drawback is that there is no place to put the central security reverse proxy to work as an application gateway. 9.5.2.5 Management node clustersA different approach to solving the DNSRR node failure problem is to introduce a central management node to the cluster (Figure 9-8). In this configuration, cluster nodes are given private addresses. The system as a whole has only one IP address, which is assigned to the management node. The management node will do the following:
Figure 9-8. Classic load balancing architecture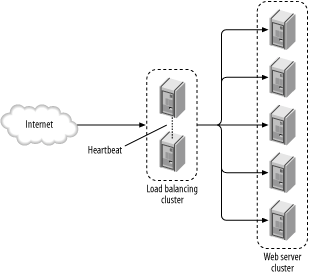 To avoid a central point of failure, the management node itself is clustered, usually in a failover mode with an identical copy of itself (though you can use a DNSRR solution with an IP address for each management node). This is a classic high-availability/load-balancing architecture. Distribution is often performed on the TCP/IP level so the cluster can work for any protocol, including HTTP (though all solutions offer various HTTP extensions). It is easy, well understood, and widely deployed. The management nodes are usually off-the-shelf products, often quite expensive but quite capable, too. These products include:
An open source alternative for Linux is the Linux Virtual Server project (http://www.linuxvirtualserver.org). It provides tools to create a high availability cluster (or management node) out of cheap commodity hardware.
9.5.2.6 Reverse proxy clustersReverse proxy clusters are the same in principle as management node clusters except that they work on the HTTP level and, therefore, only for the HTTP protocol. This type of proxy is of great interest to us because it is the only architecture that allows HTTP firewalling. Commercial solutions that work as proxies are available, but here we will discuss an open source solution based around Apache. Ralf S. Engelschall, the man behind mod_rewrite, was the first to describe how reverse proxy load balancing can be achieved using mod_rewrite:
First, create a script that will create a list of available cluster nodes and store it in a file servers.txt: # a list of servers to load balance www www1|www2|www3|www4 The script should be executed every few minutes to regenerate the list. Then configure mod_rewrite to use the list to redirect incoming requests through the internal proxy: RewriteMap servers rnd:/usr/local/apache/conf/servers.txt
RewriteRule ^/(.+)$ ${servers:www} [P,L]In this configuration, mod_rewrite is smart enough to detect when the file servers.txt changes and to reload the list. You can configure mod_rewrite to start an external daemon script and communicate with it in real time (which would allow us to use a better algorithm for load distribution). With only a couple of additional lines added to the httpd.conf configuration file, we have created a reverse proxy. We can proceed to add features to it by adding other modules (mod_ssl, mod_deflate, mod_cache, mod_security) to the mix. The reverse proxy itself must be highly available, using one of the two methods we have described. Wackamole peer-to-peer clustering is a good choice because it allows the reverse proxy cluster to consist of any number of nodes. An alternative to using mod_rewrite for load balancing, but only for the Apache 1.x branch, is to use mod_backhand (http://www.backhand.org/mod_backhand/). While load balancing in mod_rewrite is a hack, mod_backhand was specifically written with this purpose in mind. This module does essentially the same thing as mod_rewrite, but it also automates the load balancing part. An instance of mod_backhand runs on every backend server and communicates with other mod_backhand instances. This allows the reverse proxy to make an educated judgment as to which of the backend servers should be handed the request to process. With mod_backhand, you can easily have a cluster of very different machines. Only a few changes to the Apache configuration are required. To configure a mod_backhand instance to send status to other instances, add the following (replacing the specified IP addresses with ones suitable for your situation): # the folder for interprocess communication UnixSocketDir /usr/local/apache/backhand # multicast data to the local network MulticastStats 192.168.1.255:4445 # accept resource information from all hosts in the local network AcceptStatus 192.168.1.0/24 To configure the reverse proxy to send requests to backend servers, you need to feed mod_backhand a list of candidacy functions. Candidacy functions process the server list in an attempt to determine which one server is the best candidate for the job: # byAge eliminates servers that have not # reported in the last 20 seconds Backhand byAge # byLoad reorders the server list from the # least loaded to the most loaded Backhand byLoad Finally, on the proxy, you can configure a handler to access the mod_backhand status page: <Location /backhand/>
SetHandler backhand-handler
</Location> |
