9.1. The Scaling MythScaling and scalability have been hot topics for web application developers for a long time. When people started building web applications to service a huge number of people, scaling became an issue: how do we support one hundred users? One thousand? One million? One hundred million? Despite being a hot topic for so long, scaling is poorly understood. Before we can talk about how to design scalable application, we need to define what we mean by "scalable." 9.1.1. What Is Scalability?Scalability is sometimes defined as "the ease with which a system or component can be modified to fit the problem area." That definition is sufficiently vague to confuse everyone. Scalability is, in fact, very simple to define. A scalable system has three simple characteristics:
Before we go into each of these in detail, we should dispel some of the falsehoods so common in contemporary web development literature by talking about what scalability isn't. Scalability is not raw speed. Performance and scalability are quite separate issues; you can easily have a high-performing system that doesn't scale, although the reverse is not so often trueif a system can scale, you can usually increase performance by scaling it out. Just because a system is blindingly fast for 1,000 users and 1 GB of data, it's not scalable unless it can maintain that speed for 10 times the data with 10 times as many users. Scalability is not about using Java. A system built in any language using any tools can be made to scale, although the relative difficulty is an issue, of course. Java has lately become so synonymous with scalability that a lot of people think they are one and the same. Let's just repeat that againyou can build a scalable application without Java. Similarly, you don't need to be using a compiled language to design a scalable system. Native code, JITs, and compiled byte code VMs can be nice and fast, but that's a performance issue, not a scalability one. This isn't a Java-bashing session, however. It's perfectly possible to create a scalable application using Java; the implementation language has little bearing on the scalability of a system. In fact, scalability isn't about using any particular technology at all. Another common misconception is that XML is core to scalability. This is complete bunk. XML is useful for interoperability, but this is not the same thing. You can have a scalable application that neither reads nor writes XML. Scalable systems were around long before James Clark thought up that particular acronym. Scalability is sometimes described as the separation of page logic from business logic, which we discussed in Chapter 2. While this is certainly a noble aim and can help make systems more maintainable, it's not a required separation. We can create a scalable system in PHP that contains only one tier, no XML, no Java, and isn't even very fast: <?php sleep(1); echo "Hello world!"; ?> Our example "system" is not fastit will always take over a second to respond. However, it meets our three scalability criteria nicely. We can accommodate traffic growth by adding more web servers; nothing in the code needs to be changed. We can accommodate dataset growth because we don't have any stored data. Our code is also very maintainable; there's not a trained programmer out there who couldn't figure out how to maintain itfor instance, if we needed to change it to say "Hello there". 9.1.2. Scaling a Hardware PlatformWhen we talk about the two main strategies for scaling an architecture, we're talking about ways to expand capacity from a hardware point of view. While hardware appears expensive at the beginning of any project, as time goes on, the cost of software becomes much more expensive (up to a certain point, when the two cross back over for huge applications). Because of this, the tendency is to build our application to grow such that it requires little to no software work to scale; it is better to just buy and rack more hardware. The question then is "Do we build our application to scale vertically or horizontally?" The two terms are sometimes interchanged, so it's worth defining our reference points here. In a nutshell, a system that scales vertically needs a more powerful version of the same hardware to grow (throwing away the original hardware), while a horizontally scaling system needs an exact duplicate of the current hardware to grow. In practice, only one of these is practical and cost-effective for large applications. 9.1.3. Vertical ScalingThe principle of vertical scaling is simple. We start out with a very basic setupperhaps a web server and a database server. As each machine runs out of capacity, we replace it with a more powerful box. When that one runs out of capacity, we replace it with another box. When that runs out, we buy an even bigger box. And so on and so on. The problem with this model is that the cost doesn't scale linearly. Going with a single vendor, here's a price comparison for increasing the number of processors, amount of RAM, and disk capacity in a system, going either the route of buying a bigger and bigger box, or buying multiple smaller boxes, shown in Figure 9-1. Figure 9-1. Scaling with small servers and larger servers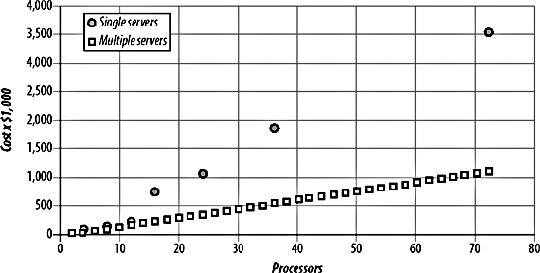 With this growth model, we'll hit a limit at some point; the price growth for vertical scaling is exponential and will eventually diverge too far from the funds we have available. Even if we have a huge pile of cash to burn through, at some point we hit the limit of easily available commercial servers. Sun's current largest big iron, the Sun Fire E25K, supports up to 72 processors and can handle 576 GB of memory, but once you hit that limit, you're out of luck. It's worth noting that existing large web application providers aren't running large SGI Altix clusters. The cost model just doesn't make sense. The appealing thing about vertical scaling is that it's really easy to design for. We can build our software on our local machines and get it functionally working. Once it's ready, we just stick it on a bigger box and release it. Every time we need more capacity, we just upgrade the hardware. The software engineers (that would be us) don't have to ever touch it again. Up to a certain size of application, this can be quite appealing. If you're certain of the ceiling for your application's usage, then vertical scaling can be a nice fast alternative to building a truly scalable system. 9.1.4. Horizontal ScalingThe principle behind horizontal scaling is similar to the vertical modeljust keep adding more hardware. The way in which this differs from the vertical scaling model is that we don't need a super powerful machine as we grow, but just many regular machines. We start with a regular single box and add a second when we run out of capacity. Then we add a third, a fourth, and so on, until we have tens of thousands of servers (as the current largest applications do). One of the tricks with buying hardware for a horizontally scaled system is deciding which hardware we want to buy. We could buy a couple of thousand Mac ministhey're fairly cheap and have CPU and RAM. The problem with the approach of buying the smallest and cheapest hardware is that we need to consider the TCO of each machine. Every machine has fairly fixed maintenance costswhether we're dealing with a Mac mini or a simple Dell rack mount box, we're still going to need to rack and cable it, install an operating system, and perform basic setup. The box will take up space and power and need extra room for cooling, depending on the physical design. While you can put a full 42 1U Dell rack servers in a single rack, the Mac mini isn't designed to keep cool when stacked in a grid. We need to find the TCO and computing power sweet spotthe point at which we're getting maximum performance for our moneyand buy those servers. As time goes by, this price point drifts (nearly always getting more powerful) so our ideal hardware changes over time. It's worth remembering this and building for it from the start. An application that requires identical servers is going to become expensive or impossible to scale over time, while an application that can mix and match whatever's cheapest is going to remain cheap. At the same time, the Google model of buying the cheapest possible hardware is dangerous for anyone but the huge GYM (Google, Yahoo!, and Microsoft) companies. The increased cost in replacing dead hardware can start to eat away at your cost savings and waste a lot of time. Depending on the design of your system, adding and removing boxes might be easy, but not trivial. Spending hours every day dealing with hardware additions and failures soon gets tiresome and expensive. So we've already seen one of the big issues with a horizontally scaled system: increased administration costs. If we have 10 1-processor boxes instead of 1 10-processor box, we'll have 10 times the administrative tasks to perform. Luckily, systems administration doesn't scale in cost linearly, since 10 identical boxes (identical in terms of software, if not hardware) make for parallelizable administration tasks. As we add more boxes, the installation and setup becomes rote as we hit the same issues over and over again, while with a single large box we wouldn't generally perform the same action again and again. One of our assumptions was that the software on the boxes is identical. If we don't keep each node in a cluster (such as the web server cluster) the same, then we'll end up with a system that's very complex for us to manage. In a system where all nodes are identical, we can simply clone new boxes as needed. Nothing special needs to be done to each one and any work on one is directly transferable to another. By using applications such as System Imager and System Configurator (http://www.systemimager.org/) or Red Hat's KickStart, we can quickly set up new boxes when we need to add hardware. An often overlooked fact is that we can also "re-jump" boxes when anything goes wrong. If we're having problems with one of our 10 web servers, we can just wipe it, and reinstall everything in a matter of a few minutes, avoiding the wasted time spent messing about with configuration issues. The increased number of machines has additional cost impact beyond the basic cost of hardware and administration time. Every box has its own power supply, which needs to draw a fixed amount of current. For a full rack of boxes, this can easily hit a hundred amps, and power is never cheap. A full rack of boxes is also going to need a full rack of spacethe more boxes you have, the more rack space you'll need to rent. While the larger boxes you'd need to scale vertically are large, they can save a lot space since they share many components. A 40U server doesn't require 40 power supplies. Every box you rack will need to be connected to your network. Beyond the trivial cost of network cabling (unless you're using fiber, which is both expensive and fragile), you'll need to have a switch port (or two) and an IP address (or two) for each box. For every rack of machines, you'll then typically need one to two Us of networking gear. All of these things need to be factored into the total cost for each machine. One of the big perceived problems with scaling horizontally, beyond administration costs, is that of underutilized hardware. When we run out of disk I/O or memory, we add another box. After doing this a few times, we have many boxes underutilizing their CPU. The trick here is to make sure we buy machines with the right performance characteristics to begin with. If we know we'll need a lot of disk I/O, then we buy 3U boxes with six internal disks. If we know we need a lot of RAM, we buy 1U Opteron boxes with 16 GB of memory and one mediocre processor. It's important to realize that even though we are buying many small boxes, we need to pay attention to the specifications to get the right balance of each characteristic. We touched on the issue of linear scalability earlier with the vertical model. For horizontally scaled systems, while the hardware will scale linearly, the performance of the software we run on top might not. Software that needs to aggregate results from all nodes in a cluster, or swap message among all of its peers, won't scale linearly but will rather give us diminishing returns; as we add each server, the amount of extra capacity decreases. With a system like this, it's important to figure out at what point it becomes too expensive to add more hardware. At some point, we'll hit a wall, and adding hardware won't add capacityworst case scenario, it might actually decrease total capacity. Ideally, we'd be able to design software in such a way that we always linearly scaled, but that's not always practical. Where we're not linear, we need to identify the situation and take careful note of when adding more hardware will start to get too expensive from a cost/benefit point of view. At that point, we can start to go vertical and replace existing nodes in the cluster with more powerful machines. This marriage of horizontal and vertical wins us some of the benefits of both: we can more easily design software, but we don't have to buy the most expensive servers available. 9.1.5. Ongoing WorkOnce we have a horizontally scalable architecture, the only infrastructure work left is fairly rote and methodical. We'll need to continue increasing system capacity inline with expected activity and dataset growth by adding more production hardware before we run out of capacity. Capacity planning is a fairly exact science that can span several sizable books; a good place to start is the seminal work Performance by Design: Computer Capacity Planning by Example (Prentice Hall). In addition to capacity planning, we'll need to deal with ongoing "events" such as component- and machine-level failures (and perhaps even a DC-level failure). As we deal more and more with each of these issue, they become more and more rote. A set of crisis management documents is a good deliverable for the end of the architectural design cycle. A good set of crisis management and failure scenario documents should include a simple step-by-step guide to recovering from any conceivable failurewhat should we do when a disk fails? When a disk fills? When a machine fails? When a database index corrupts? When a machine reaches its I/O throughput limit, and so on. The goal of a good set of documentation should be to make all of the common problems trivial to deal with, while making the esoteric issues manageable. Considering and writing this documentation during the design of your application will help determine what can go wrong and how your system can cope with it. 9.1.6. RedundancyWhether we scale horizontally or vertically, machines can fail. Various Google presentations have stated that, out of every 10,000 machines, they expect one to die each day. They're not talking about disk failure either, but full system failure. Whatever hardware you have, it can and will fail, given enough time. Your design will need to be able to cope with every component failing, possibly all at the same time. Whatever hardware you're using, the only way to ensure service in the case of a failure is to have multiple copies of that hardware. Depending on the hardware and your design, the spare pieces you have may be cold, warm, or hot. A cold standby might be used for something like a network switch. In the case when a switch fails, we need to grab the spare one, plug everything into it, duplicate the configuration, and light it up. This is a cold spare because it requires setup and configuration (either physical or in software; in this case both) before it can take over for the failed component. A warm spare is then a piece of hardware that is all configured for use and just needs to be flipped on (again, either physically or in software) to start using it. A typical example might be a MySQL system with a production master and a backup slave. We don't use the slave in production, but if the master dies we can redirect all traffic to the slave. The slave is setup and ready to go; it's been duplicating data from the master all along and is constantly ready to take over. The third and most preferable mode of redundancy is to have hot spare components. When one component fails, the others automatically take over from it. The dead component is detected, and the transition happens without any user intervention. This is clearly preferable as users see no drop in serviceeverything just continues working, leaving you to fix the broken component at your leisure. For example, two load balancers might be configured in an active/passive pair. The active balancer is taking all traffic, talking to the backup balancer via a monitoring protocol. The active load balancer fails, and the passive load balancer stops getting a heartbeat from it. It immediately knows to take over and starts receiving and processing the traffic. One issue with hot standby systems is what's known as flapping . In some configurations, components may appear dead due to some software issues, so the backup takes over. Once traffic is removed from the dead component, it appears to start working again, so traffic moves back to it. The traffic causes it to fail (or appear to fail) again, so traffic moves to the spare. This process is called "flapping" because the traffic flaps between one component and another. This is prevalent with Border Gateway Protocol (BGP) routing on the Internet. A misconfigured router may not align with its neighbor correctly, so its neighbor removes it from its routing table, promoting another route above it. Traffic moves from the "broken" router, causing it to come to life again, so the routing table in the other router is updated, with a lower metric for the newly established link. Traffic flows through the first route again and the process repeats. For the second router, CPU usage spikes as the routing tables are constantly updated, all while traffic flows across the router, possibly causing requests and replies to arrive out of order as some take one route and some take another. To avoid flapping in BGP, various damping algorithms are used to delay the second routing change. In our own systems we can avoid flapping in different ways because our components don't necessarily work the same way as BGP's routing metrics. When we have an active/passive pair, the active component is chosen not because it has the lowest metric, but arbitrarily insteadeither of the two components would be as good as the other. Because of this, once we've failed over to the passive node, we can stick with it. Once the previously active node comes back online, it becomes the passive node. The only flapping that can then occur is when both (or all) nodes in the cluster have the same issue and fail when traffic is pushed onto them. For this scenario, we might want to add damping, or alternatively just monitor for the situation and fix it manually. Damping can be dangerous in many situations because if the component has really failed, then we don't want to delay switching away from it to the backup. A distinction needs to be made between active/passive redundant pairs, and active/active pairs or clusters. In an active/passive pair, we have one online production device and one hot backup not being used. In an active/active pair, we use both devices simultaneously, moving all traffic to a single device when the other fails. For two devices the distinction isn't so important, but once we go above two and into a cluster, it becomes a little more interesting. For example, imagine we have a cluster of 10 database slaves. We can read from all 10 at once, putting one-tenth of the read traffic onto each. When one box fails, we simply move all read traffic to the remaining 9. At this point we need to make a calculation based on the failure rate of machines, the time it takes to replace dead machines and the number of needed machines to service the users. We might decide that we can't do with just one spare since it takes a couple of days to replace a box, so we need to keep two spare boxes at all times. Our application needs at least five boxes to perform acceptably. We'll need to then allocate seven boxes to the cluster. When all machines are in use, we have a little bit of spare capacity and all machines are being well utilized. When one or two machines die, we still have enough capacity to serve our users. By using active/active clusters, we avoid having hardware that sits idle, which is undesirable for a few reasons. First, it's an issue of perceptionmachines that take up rack space and draw power but don't contribute anything to the running of the application seem like a waste. When machines lie idle, there's more chance that something will fail when they come to be used. When a machine is having its disk pounded by reads and writes, it'll fail fairly quickly if the disk is bad. In a batch of 100 disks, 1 or 2 will usually fail within the first couple of days of intensive use, while some will underperform because of constant soft errors. The time to find out you need new disks is early on when you have the hot spares running, not down the line when other machines have failed and you need to start using the spares that have been laying idle. We've already mentioned it, but it's important that you figure out how much capacity you need and add to that the amount of failover you want. For example, imagine we have two disk appliances to handle all of our reads and writes. We write to both appliances at once so that we always have two consistent copies of our data (we'll talk about why and how to do this shortly). We use the hardware in an active/active pair, reading from bothwe're doing a lot more reads than writes, so we'll run out of read capacity long before writing. If one of the appliances dies, we move all reading to the second appliance. In this case, it's essential that one appliance by itself is able to handle all of the production traffic. If 1.5 appliances were needed to fulfill the read quota, then we'd need at least 3 mirrored appliances in our setup. We can then allow one to die, while the other two manage the production load. If we needed to handle more than one dying at once, we'd need even more. In this model, we would benefit from smaller servers. If a server with half the capacity existed for half the cost, then we could spend less. We'd need three of these servers to manage the production load, with an additional active spare (assuming they had the same failure rate and replacement service-level agreement (SLA)). We're then spending two-thirds of the previous raw cost (but a little more in TCO). This cost saving comes from two placesgranularity and reduced redundancy. Because the capacity of each box is reduced, we can more accurately figure out how many boxes we need to support production traffic, leaving less overhead on the last box. This can account for a certain amount, but the real saving comes in reducing the amount of spare capacity we carry. If we had machines with one-tenth the capacity at one-tenth the cost, we would be spending one-tenth as much on hot spares (since we'd still need only one). To meet a minimum level of redundancy, we want to avoid having any single point failures without having at least one cold spare. This can be fairly expensive when starting out (especially if you use expensive load-balancing appliances), so when allocating a limited budget, you'll want to make sure the most commonly failing components are properly redundant first. For equipment you don't have a hot, warm, or cold spare for, you should find out the lead time for replacement, should you need to quickly obtain another. Keeping a document of vendors and lead times for each component in your system is not a bad idea. The one element that usually sits outside this guideline is spare disks. Disks fail so often and so consistently that you'll need to always have spares in stock. The number of spares you'll need varies depending on the number of disks you have spinning at any one time, the MTBF of the specific disks you use, and the environment they're in (hot disks tend to fail a lot faster). If you can avoid using too many varieties of disk, then you can reduce the number you need to keep on hand. Replacing disks with similar disks is extremely important in I/O-bound RAID configurations, as the disk throughput will be bound by the slowest disk. While we've touched on a few areas of redundancy and failover, we're still within a single DC. We haven't talked at all about cross-DC redundancy and failover. We'll cover the failover semantics briefly when we talk about load balancing, but as for redundancy, all the same rules apply inter-DC as they do intra-DC. We need to have enough capacity to be able to lose one DC and carry on operating, or we're not redundant. For a simple two DC setup, that means we need full capacity in both, with completely mirrored data. As with any component, when we have three DCs our costs dropif we're only protecting ourselves from one DC failure at a time, we only need each DC to handle half our capacity. Any data need only be replicated to two of the three DCs. This cuts our spare hardware overhead in half, and it continues to drop as we add more DCs. It will also give us better latency, which we'll discuss shortly. |