Hack 42. Spider the Web with Firefox
Save lots and lots of web pages to your local disk without hassle. If a web page is precious, a simple bookmark might not be enough. You might want to keep a copy of the page locally. This hack explains how to save lots of things at once with Firefox. Usually this kind of thing is done by a web spider. A web spider is any program that poses as a user and navigates through pages, following links. For heavy-duty web site spidering done separately from Firefox, Free Download Manager (http://www.freedownloadmanager.org) for Windows and wget(1) for Unix/Linux (usually preinstalled) are recommended. 4.11.1. Save One Complete PageThe days of HTML-only page capture are long gone. It's easy to capture a whole web page now. 4.11.1.1 Saving using Web Page CompleteTo save a whole web page, choose File
4.11.1.2 Saving using PrintOne problem with saved web pages is that the copy is just a snapshot in time. It's difficult to tell from a plain HTML document when it was captured. A common technique that solves this problem and keeps all the HTML content together is to use Acrobat Distiller, which comes with the commercial (nonfree) version of Acrobat Reader. When Distiller is installed, it also installs two printer drivers. The important one is called Acrobat PDFWriter. It can convert an HTML page to a single date-stamped PDF file. Although such PDF files are large and occasionally imperfect, the process of capturing web pages this way is addictive in its simplicity, and the files are easy to view later with the free (or full) Reader. The only drawback is that PDF files can be quite large compared to HTML. To save web pages as PDF files, choose File 4.11.2. Save Lots of PagesTo save lots of Web pages, use an extension. The Download Tools category at http://update.mozilla.org lists a number of likely candidates. Here are a few of them. 4.11.2.1 Down Them AllThe Down Them All extension (http://downthemall.mozdev.org), invoked from the context menu, skims the current page for foreign information and saves everything it finds to local disk. It effectively acts as a two-tier spider. It saves all images linked from the current page, as well as all pages linked to from the current page. It doesn't save stylesheets or images embedded in linked-to pages. Two of the advantages of Down Them All are that it can be stopped partway through, and download progress is obvious while it is underway. 4.11.2.2 MagpieThe Magpie extension (http://www.bengoodger.com/software/tabloader/) provides a minimal interface that takes a little getting used to. For spidering purposes, the context menu items that Magpie adds are not so useful. The special keystroke Ctrl-Shift-S, special URLs, and the Magpie configuration dialog box are the key spidering features. To find the Magpie configuration system, choose
Tools Figure 4-21. Magpie configuration window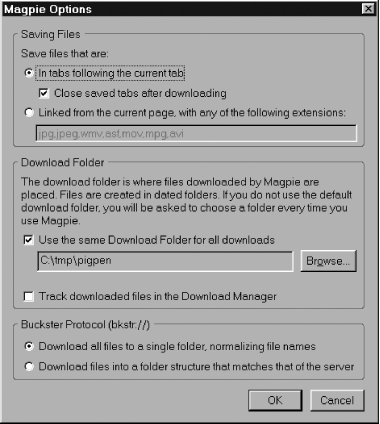 Using this dialog box, you can set one of two options for Ctrl-Shift-S (detailed in the radio group at the top). Everything else in this window has to do with folder names to be used on local disk. The first time you press Ctrl-Shift-S, Firefox asks you for the name of an existing folder in which to put all the Magpie downloads. After that, it never asks again. By default, Ctrl-Shift-S saves all tabs to the right of the current one and then closes those tabs. That is one-tier spidering of one or more web pages, plus two-tier spidering for any linked images in the displayed pages. If the "Linked from the current page..." option is selected instead, then Magpie acts like Down Them All, scraping all images (or other specified content) linked from the current page. In both cases, Magpie generates a file with the name YYYY-MM-DD HH-MM-SS (a datestamp) in the target directory and stuffs all the spidered content in there. The other use of Magpie is to download collections of URLs that have similar names. This is like specifying a keyword bookmark, except that only numbers can be used as parameters and they must be hand specified as ranges. For example, suppose these URLs are required: http://www.example.com/section1/page3.html http://www.example.com/section1/page4.html http://www.example.com/section2/page3.html http://www.example.com/section2/page4.html Using the special bkstr: URL scheme (an unofficial convenience implemented by Magpie), these four URLs can be condensed down to a single URL that indicates the ranges required: bkstr://ww.example.com/section{1-2}/page{3-4}.htmlRetrieving this URL retrieves the four pages listed directly to disk, with no display. This process is also a one-tier spidering technology, so retrieved pages will not be filled with any images to which they might refer. This technique is most useful for retrieving a set of images from a photo album or a set of documents (chapters, minutes, diary entries) from an index page. 4.11.2.3 SloggerRather than saving page content on demand, the Slogger extension (http://www.kenschutte.com/firefoxext/) saves every page you ever display. After the initial install, the extension does nothing immediately. It's only when you highlight it in the Extensions Manager, click the Options box, and choose a default folder for the logged content that it starts to fill the disk. The configuration options are numerous, and Perl-like syntax options make both the names of the logged files and the content of the log audit trail highly customizable. Since Slogger saves only what you see, how well it spiders depends on how deeply you navigate through a web site's hierarchy. Note that Mozilla's history mechanism works the same way as Slogger, except that it stores downloaded web pages unreadably in the disk cache (if that's turned on), and that disk cache can be flushed or overwritten if it fills up. 4.11.3. Learning from the MasterBob Clary's CSpider JavaScript library and XUL Spider application are the best free tools available for automating web page navigation from inside web pages. You can read about them here: http://www.bclary.com/2004/07/10/mozilla-spiders. These tools are aimed at web programmers with a systematic mindset. They are the basis of a suite of web page compatibility and correctness tests. These tools won't let you save anything to disk; instead, they represent a useful starting point for any spidering code that you might want to create yourself. |
 Save Page As... and
make sure that "Save as type:" is
set to Web Page Complete. If you change this option, that change will
become the future default only if you complete the save action while
you're there. If you back out without saving, the
change will be lost. When the page is saved, an HTML document and a
folder are created in the target directory. The folder contains all
the ancillary information about the page, and the
page's content is adjusted so that image, frame, and
stylesheet URLs are relative to that folder. So, the saved page is
not a perfect copy of the original HTML. There are two small oddities
to watch out for:
Save Page As... and
make sure that "Save as type:" is
set to Web Page Complete. If you change this option, that change will
become the future default only if you complete the save action while
you're there. If you back out without saving, the
change will be lost. When the page is saved, an HTML document and a
folder are created in the target directory. The folder contains all
the ancillary information about the page, and the
page's content is adjusted so that image, frame, and
stylesheet URLs are relative to that folder. So, the saved page is
not a perfect copy of the original HTML. There are two small oddities
to watch out for: