There are several methods to analyze a malware sample, and a common differentiation is between code and behavior binary analysis.
By analyzing the code of a malware sample, all possible control flows can be examined. Thus, all functions and even hidden actions that will only be triggered under certain conditions can be found. The easiest way would be to examine the source code itself, but this is often not possible, since the source code of malware is commonly not available. Even if the source code is available, one could never be sure that no modifications of the binary executable happened, which were not documented by the source. Therefore, the code analysis is normally performed at the machine code level. The sample is disassembled and then inspected manually (static analysis). Sometimes even a decompilation is possible, resulting in a higher-level program that could be understood easier and analyzed faster. This is, however, the exception with malware samples, since they use code-obfuscation techniques like compression or encryption to evade decompilation. Code analysis requires a lot of expert knowledge and is very time consuming. Obfuscation techniques like self-modifying code make code analysis even harder. Since the aim of CWSandbox lies on automated analysis of malware binaries, code analysis is not an option.
Often a complete inspection of the code is not necessary. There is also some additional information, which could be extracted from the binary in very short time:
The ASCII and UNICODE strings that are contained in a binary often disclose some of its functionality. There are several tools for extracting them, one of which is Strings from the Sysinternals website (http://www.microsoft.com/technet/sysinternals/utilities/strings.mspx).
The imported libraries and functions also often disclose a lot of the included functionality.
The MD5 or SHA-512 hash can be used for an unique identification of the malware.
This information could be used to identify the malware or to learn what operations may be performed during its execution. If you would, for example, find the string mymalware.example.org in the list of referenced strings, it would be very probable that a server with this dynamic name should be contacted. Or if the library function RegOpenKey is imported, you could be sure that there is registry access. There exist several new approaches, which use patterns of malicious operations or instruction semantics for automatic malware detection.
However, code analysis also has some severe drawbacks: Most malware binaries in the wild are obfuscated with the help of different binary packers or crypters. These tools try to obfuscate the binary as much as possible — for example, by compressing the binary and then unpacking it during runtime. Packers are a severe problem, since they can make reverse engineering much harder. It can be very time consuming to at first unpack a given binary before the actual analysis can start. In addition, packers also try to fool common dissassemblers, so code analysis can be made much harder with the help of these tools.
In contrast to code analysis, behavior analysis handles the malware binary as a black box and only analyzes its behavior, as can be seen from the outside during its execution (dynamic analysis).
Dynamic analysis means to observe one or more behaviors of a software artifact to analyse its properties by executing the software itself. We have already argued that dynamic analysis is preferable to static (code) analysis when it comes to malware. There are two different approaches to dynamic malware analysis with different result granularity and quality:
It is evident that the first option is easier to implement but delivers more coarse-grained results, which sometimes, however, are sufficient. This approach can only analyze the cumulative effects and does not take dynamic changes into account. If, for example, a file is generated during the malware's execution, and this file is deleted before the malware terminates, the first approach will not be able to observe this behavior. The second approach is harder to implement, but it delivers much more detailed results, and this approach is used in CWSandbox.
Please note that behavior analysis has two main drawbacks. First, the execution of the malware sample involves risks as malicious code is executed. Similar to a normal honeypot, you allow malicious actions to happen, and thus some precautions are necessary. Second, the result is not necessarily complete, since only one execution path is examined — that is, functions that are only triggered under certain conditions that do not hold during the execution will stay undiscovered. Nevertheless, behavior analysis often leads to sufficient results in practice. Since it brings the enormous advantage of a completely automated process, it is a powerful weapon in the fight against malware. In practice, the behavior analysis can be used as a preprocessing step to get a summarized report about a given malware sample. If you need more information about the malware binary, you can perform a manual code analysis afterward.
In the following, we introduce the different building blocks to implement a behavior-based analysis system to monitor all actions of a given malware sample.
The Windows API is a programmer's interface that can be used to access the Windows resources — for example, files, processes, network, registry, and all other major parts of Windows. User applications use the API instead of making direct system calls, so this offers a possibility for behavior analysis. We get a dynamic analysis if we monitor all relevant API calls and their parameters. The API itself consists of several DLL files that are contained in the Windows System Directory. Some of the most important files are kernel32.dll, advapi32.dll, ws2_32.dll, and user32.dll. Nearly all API functions do not call the system directly but are only wrappers to the so-called Native API, which is implemented in the file ntdll.dll. With the native API, Microsoft introduces an additional API layer. With that, Microsoft increases the portability of Windows applications. The implementation of native API functions often changes from one Windows version to another, but the implementation and the interface of the regular Windows API functions is almost constant.
The native API is not the end of the execution chain that is performed when an API function is executed. Like other operating systems, the running process has to switch from usermode (Ring 3) to kernelmode (Ring 0) to perform operations on the system resources. This is mostly done in the ntdll.dll, although some Windows API functions can switch to kernelmode by themselves. The transfer to kernelmode is performed by initiating a software interrupt, Windows uses int 0x2e for that purpose, or by using processor specific commands — that is, sysenter for Intel processors or syscall for AMD processors. Control is then transfered to ntoskrnl.exe, which is the core of the Windows operating system.
To observe the control flow from a given malware sample, we need to somehow get access to these different API functions. A possible way to achieve this is hooking. Hooking of a function means the interception of any call to it. When a hooked function should be executed, control is delegated to a different location, where customized code resides: the hook or hook function. The hook can then perform its own operations and later transfer control back to the original API function or prevent its execution completely. If hooking is done properly, it is hard for the calling application to detect that the API function was hooked and that the hook function was called instead of the original one. However, the malware application could try to detect the hooking function, and thus we need to carefully implement it and try to hide as much as possible the analysis environment from the malware process.
There are several methods that allow the interception of system calls during their way from a potentially malicious user application to the ultimate kernel code [42]. One can intercept the execution chain either inside the user process itself, in one or multiple parts of the Windows API or inside the Windows kernel by modifying the Interrupt Descriptor Table (IDT) or the System Service Dispatch Table (SSDT). All of them have different advantages, disadvantages, and complexities. CWSandbox uses the technique of inline code overwriting, since it is one of the most effective and efficient methods.
With inline code overwriting, the code of the API functions, which is contained in the DLLs loaded into the process memory, is overwritten directly. Therefore, all calls to these APIs are rerouted to the hook function, no matter at what time they occur or if they are linked implicitly or explicitly. The overwriting is performed with the following steps:
1. | The target application is created in suspended mode. This means that the Windows loader loads and initializes the application and all implicitly linked DLLs, but it does not start the main thread, so no single operation of the application is performed. |
2. | When all the initialization work is done, every function to be hooked is looked up in the Export Address Table of the containing DLL and their code entry points are retrieved. |
3. | As the original code of each hooked API function will be overwritten, the overwritten bytes must be saved in advance, since we later want to reconstruct the original API function. |
4. | The first few instructions of each API function are overwritten with a JMP (or a CALL) instruction leading to the hook function. |
5. | To make this method complete, the API functions that allow the explicit binding of DLLs (LoadLibrary and LoadLibraryEx) also need to be hooked. If a DLL is loaded dynamically at runtime, the same procedure as the previous one is performed to overwrite the function entry points before control is delegated back to the calling application. |
In Figure 12.1, a simplified schema of this method is shown. The upper function block shows the original function code for the API function CreateFileA that is located in the DLL kernel32.dll. For a better understanding, the instructions are logically split into two blocks. The first block marks the instructions that will be overwritten by the JMP to the hook function. The second block includes the instructions that will be untouched by the API hook. In the lower part of the figure, the situation is shown after the installation of the hook:
The first block of the API function is overwritten with the JMP instruction that transfers control (1) to the hook function, whenever the API function is called.
The second block of the API function remains untouched.
The hook function performs the desired operations and then calls the saved stub of the original API function (2).
The saved stub performs all the overwritten instructions and then branches to the unmodified part of the original API function (3).
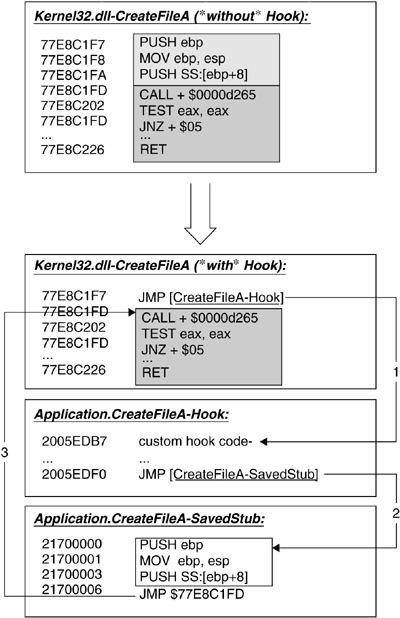
Of course, the hook function does not need to call the original API function. Also, there is no need to call it with a JMP. The hook function can call the original API with a CALL operation and get back control when the RET is performed in the called API function. The hook function can then analyze the result and modify it, if this is necessary.
One of the most popular and detailed descriptions of this approach is given by a hacker called Holy Father [24]. Hunt et al. introduced Detours, a library for instrumenting arbitrary Windows functions [38]. With the help of this library, it is possible to implement an automated approach for malware analysis. An overview of many different techniques for intercepting arbitrary functions on different platforms is given in a paper by Myers and Bazinet [58].
For completeness reasons, we also mention System Service Hooking. This technique performs hooking at a lower level within the Windows operating system and is thus not considered API hooking. There are two additional possibilities for rerouting API calls. On the one hand, an entry in the IDT can be modified, such that interrupt int 0x2e, which performs the transition from usermode to kernelmode, points to the hooking routine. On the other hand, the entries in the SSDT can be manipulated, such that the system calls can be intercepted, depending on the service IDs. CWSandbox does not use these techniques for now, since API hooking has proven to deliver accurate results in practice.
API hooking with inline code overwriting makes it necessary to patch the application after it has been loaded into memory. To be successful, we have to do the following:
Copy the hook functions into the target application's address space, such that these can be called from within the target; this is the actual code injection.
Bootstrap and set up the API hooks in the target application's address space, using a specialized thread in the malware's memory.
How can we implant the hook functions into the process running the malware sample? For installing the hooks, the performed actions depend on the hooking method used. In any case, the memory of the target process has to be manipulated — for example, by changing the IAT of the application itself, changing the EAT of the loaded DLLs, or directly overwriting the API function code. Windows offers functions to perform both of the necessary tasks for implanting and installing API hook functions: accessing another process's virtual memory and executing code in a different process's context.
Accessing anothers process's virtual memory is possible under Windows: kernel32.dll offers the API functions ReadProcessMemory and WriteProcessMemory, which allow the reading and writing of an arbitrary process's virtual memory. Of course, the reader and writer needs appropriate security privileges. If he holds them, he even can allocate new memory or change the protection of an already allocated memory region by using VirtualAllocEx and VirtualProtectEx.
How can we now execute code in another process's context? This is possible in Windows in at least two ways.
Both techniques can be implemented with appropriate API functions. With those building blocks it is now possible to inject code into another process.
The most popular technique for code injection is the so-called DLL injection. All custom code is put into a DLL, called the injected DLL, and the target process is directed to load this DLL into its memory. Thus, both requirements for API hooking are fulfilled. The custom hook functions are loaded into the targets address space, and the API hooks can be installed in the DLL's initialization routine, which is called automatically by the Windows loader.
The explicit linking of a DLL is performed by the API functions LoadLibrary or LoadLibraryEx, from which the latter one simply allows some more options. The signature of the first function is very simple; the only parameter needed is a pointer to the name of the DLL.
The trick is to create a new thread in the target's process context using the function CreateRemoteThread and then setting the code address of the API function LoadLibrary as the starting address of this newly created thread. So when the new thread is executed, the function LoadLibrary is called automatically inside the targets context. Since we know the kernel32.dll's location (always loaded at the same memory address) from our starter application and we also know the code location for the LoadLibrary function, we can use these values also for the target application.