Work QueuesWork queues are a different form of deferring work from what we have looked at so far. Work queues defer work into a kernel threadthis bottom half always runs in process context. Thus, code deferred to a work queue has all the usual benefits of process context. Most importantly, work queues are schedulable and can therefore sleep. Normally, it is easy to decide between using work queues and softirqs/tasklets. If the deferred work needs to sleep, work queues are used. If the deferred work need not sleep, softirqs or tasklets are used. Indeed, the usual alternative to work queues is kernel threads. Because the kernel developers frown upon creating a new kernel thread (and, in some locales, it is a punishable offense), work queues are strongly preferred. They are really easy to use, too. If you need a schedulable entity to perform your bottom-half processing, you need work queues. They are the only bottom-half mechanisms that run in process context, and thus, the only ones that can sleep. This means they are useful for situations where you need to allocate a lot of memory, obtain a semaphore, or perform block I/O. If you do not need a kernel thread to handle your deferred work, consider a tasklet instead. Implementation of Work QueuesIn its most basic form, the work queue subsystem is an interface for creating kernel threads to handle work that is queued from elsewhere. These kernel threads are called worker threads. Work queues let your driver create a special worker thread to handle deferred work. The work queue subsystem, however, implements and provides a default worker thread for handling work. Therefore, in its most common form, a work queue is a simple interface for deferring work to a generic kernel thread. The default worker threads are called events/n where n is the processor number; there is one per processor. For example, on a uniprocessor system there is one thread, events/0. A dual processor system would additionally have an events/1 tHRead. The default worker thread handles deferred work from multiple locations. Many drivers in the kernel defer their bottom-half work to the default thread. Unless a driver or subsystem has a strong requirement for creating its own thread, the default thread is preferred. Nothing stops code from creating its own worker thread, however. This might be advantageous if you are performing large amounts of processing in the worker thread. Processor-intense and performance-critical work might benefit from its own thread. This also lightens the load on the default threads, which prevents starving the rest of the queued work. Data Structures Representing the ThreadsThe worker threads are represented by the workqueue_struct structure:
/*
* The externally visible workqueue abstraction is an array of
* per-CPU workqueues:
*/
struct workqueue_struct {
struct cpu_workqueue_struct cpu_wq[NR_CPUS];
const char *name;
struct list_head list;
};
This structure, defined in kernel/workqueue.c, contains an array of struct cpu_workqueue_struct, one per possible processor on the system. Because the worker threads exist on each processor in the system, there is one of these structures per worker thread, per processor, on a given machine. The cpu_workqueue_struct is the core data structure and is also defined in kernel/workqueue.c:
struct cpu_workqueue_struct {
spinlock_t lock; /* lock protecting this structure */
long remove_sequence; /* least-recently added (next to run) */
long insert_sequence; /* next to add */
struct list_head worklist; /* list of work */
wait_queue_head_t more_work;
wait_queue_head_t work_done;
struct workqueue_struct *wq; /* associated workqueue_struct */
task_t *thread; /* associated thread */
int run_depth; /* run_workqueue() recursion depth */
};
Note that each type of worker thread has one workqueue_struct associated to it. Inside, there is one cpu_workqueue_struct for every thread and, thus, every processor, because there is one worker thread on each processor. Data Structures Representing the WorkAll worker threads are implemented as normal kernel threads running the worker_thread()function. After initial setup, this function enters an infinite loop and goes to sleep. When work is queued, the thread is awakened and processes the work. When there is no work left to process, it goes back to sleep. The work is represented by the work_struct structure, defined in <linux/workqueue.h>:
struct work_struct {
unsigned long pending; /* is this work pending? */
struct list_head entry; /* link list of all work */
void (*func)(void *); /* handler function */
void *data; /* argument to handler */
void *wq_data; /* used internally */
struct timer_list timer; /* timer used by delayed work queues */
};
These structures are strung into a linked list, one for each type of queue on each processor. For example, there is one list of deferred work for the generic thread, per processor. When a worker thread wakes up, it runs any work in its list. As it completes work, it removes the corresponding work_struct enTRies from the linked list. When the list is empty, it goes back to sleep. Let's look at the heart of worker_thread(), simplified:
for (;;) {
set_task_state(current, TASK_INTERRUPTIBLE);
add_wait_queue(&cwq->more_work, &wait);
if (list_empty(&cwq->worklist))
schedule();
else
set_task_state(current, TASK_RUNNING);
remove_wait_queue(&cwq->more_work, &wait);
if (!list_empty(&cwq->worklist))
run_workqueue(cwq);
}
This function performs the following functions, in an infinite loop:
run_workqueue()The function run_workqueue(), in turn, actually performs the deferred work:
while (!list_empty(&cwq->worklist)) {
struct work_struct *work;
void (*f)(void *);
void *data;
work = list_entry(cwq->worklist.next, struct work_struct, entry);
f = work->func;
data = work->data;
list_del_init(cwq->worklist.next);
clear_bit(0, &work->pending);
f(data);
}
This function loops over each entry in the linked list of pending work and executes the func member of the workqueue_struct for each entry in the linked list:
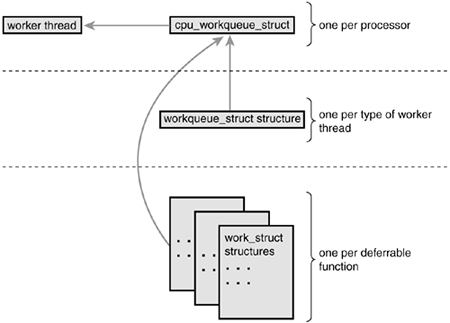
Excuse Me?The relationship between the different data structures is admittedly a bit convoluted. Figure 7.1 provides a graphical example, which should bring it all together. Figure 7.1. The relationship between work, work queues, and the worker threads.
At the highest level, there are worker threads. There can be multiple types of worker threads. There is one worker thread per processor of a given type. Parts of the kernel can create worker threads as needed. By default, there is the events worker thread. Each worker thread is represented by the cpu_workqueue_struct structure. The workqueue_struct structure represents all the worker threads of a given type. For example, assume that in addition to the generic events worker type, I also create a falcon worker type. Also, assume I have a four-processor computer. Then there are four events threads (and thus four cpu_workqueue_struct structures) and four falcon threads (and thus another four cpu_workqueue_struct structures). There is one workqueue_struct for the events type and one for the falcon type. Now, let's approach from the lowest level, which starts with work. Your driver creates work, which it wants to defer to later. The work_struct structure represents this work. Among other things, this structure contains a pointer to the function that will handle the deferred work. The work is submitted to a specific worker threadin this case, a specific falcon thread. The worker thread then wakes up and performs the queued work. Most drivers use the existing default worker threads, named events. They are easy and simple. Some more serious situations, however, demand their own worker threads. The XFS file system, for example, creates two new types of worker threads. Using Work QueuesUsing work queues is easy. We cover the default events queue first, and then look at creating new worker threads. Creating WorkThe first step is actually creating some work to defer. To create the structure statically at run-time, use DECLARE_WORK: DECLARE_WORK(name, void (*func)(void *), void *data); This statically creates a work_struct structure named name with handler function func and argument data. Alternatively, you can create work at run-time via a pointer: INIT_WORK(struct work_struct *work, void (*func)(void *), void *data); This dynamically initializes the work queue pointed to by work with handler function func and argument data. Your Work Queue HandlerThe prototype for the work queue handler is void work_handler(void *data) A worker thread executes this function, and thus, the function runs in process context. By default, interrupts are enabled and no locks are held. If needed, the function can sleep. Note that, despite running in process context, the work handlers cannot access user-space memory because there is no associated user-space memory map for kernel threads. The kernel can access user memory only when running on behalf of a user-space process, such as when executing a system call. Only then is user memory mapped in. Locking between work queues or other parts of the kernel is handled just as with any other process context code. This makes writing work handlers much easier. The next two chapters cover locking. Scheduling WorkNow that the work is created, we can schedule it. To queue a given work's handler function with the default events worker threads, simply call schedule_work(&work); The work is scheduled immediately and is run as soon as the events worker thread on the current processor wakes up. Sometimes you do not want the work to execute immediately, but instead after some delay. In those cases, you can schedule work to execute at a given time in the future: schedule_delayed_work(&work, delay); In this case, the work_struct represented by &work will not execute for at least delay timer ticks into the future. Using ticks as a unit of time is covered in Chapter 10. Flushing WorkQueued work is executed when the worker thread next wakes up. Sometimes, you need to ensure that a given batch of work has completed before continuing. This is especially important for modules, which almost certainly want to call this function before unloading. Other places in the kernel also might need to make certain no work is pending, to prevent race conditions. For these needs, there is a function to flush a given work queue: void flush_scheduled_work(void); This function waits until all entries in the queue are executed before returning. While waiting for any pending work to execute, the function sleeps. Therefore, you can call it only from process context. Note that this function does not cancel any delayed work. That is, any work that was scheduled via schedule_delayed_work(), and whose delay is not yet up, is not flushed via flush_scheduled_work(). To cancel delayed work, call int cancel_delayed_work(struct work_struct *work); This function cancels the pending work, if any, associated with the given work_struct. Creating New Work QueuesIf the default queue is insufficient for your needs, you can create a new work queue and corresponding worker threads. Because this creates one worker thread per processor, you should create unique work queues only if your code really needs the performance of a unique set of threads. You create a new work queue and the associated worker threads via a simple function: struct workqueue_struct *create_workqueue(const char *name); The parameter name is used to name the kernel threads. For example, the default events queue is created via
struct workqueue_struct *keventd_wq;
keventd_wq = create_workqueue("events");
This function creates all the worker threads (one for each processor in the system) and prepares them to handle work. Creating work is handled in the same manner regardless of the queue type. After the work is created, the following functions are analogous to schedule_work() and schedule_delayed_work(), except that they work on the given work queue and not the default events queue.
int queue_work(struct workqueue_struct *wq, struct work_struct *work)
int queue_delayed_work(struct workqueue_struct *wq,
struct work_struct *work,
unsigned long delay)
Finally, you can flush a wait queue via a call to the function flush_workqueue(struct workqueue_struct *wq) As previously discussed, this function works identically to flush_scheduled_work(), except that it waits for the given queue to empty before returning. The Old Task Queue MechanismLike the BH interface, which gave way to softirqs and tasklets, the work queue interface grew out of shortcomings in the task queue interface. The task queue interface (often called simply tq in the kernel), like tasklets, also has nothing to do with tasks in the process sense[7]. The users of the task queue interface were ripped in half during the 2.5 development kernel. Half of the users were converted to tasklets, whereas the other half continued using the task queue interface. What was left of the task queue interface then became the work queue interface. Briefly looking at task queues, which were around for some time, is a useful historical exercise. Task queues work by defining a bunch of queues. The queues have names, such as the scheduler queue, the immediate queue, or the timer queue. Each queue is run at a specific point in the kernel. A kernel thread, keventd, ran the work associated with the scheduler queue. This was the precursor to the full work queue interface. The timer queue was run at each tick of the system timer and the immediate queue was run in a handful of different places to ensure it was run "immediately" (hack!). There were other queues, too. Additionally, you could dynamically create new queues. All this might sound useful, but the reality is that the task queue interface was a mess. All the queues were essentially arbitrary abstractions, scattered about the kernel as if thrown in the air and kept where they landed. The only meaningful queue was the scheduler queue, which provided the only way to defer work to process context. The other good thing about task queues was the brain-dead simple interface. Despite the myriad of queues and the arbitrary rules about when they ran, the interface was as simple as possible. But that's about itthe rest of task queues needed to go. The various task queue users were converted to other bottom-half mechanisms. Most of them switched to tasklets. The scheduler queue users stuck around. Finally, the keventd code was generalized into the excellent work queue mechanism we have today and task queues were finally ripped out of the kernel. |