Slab LayerAllocating and freeing data structures is one of the most common operations inside any kernel. To facilitate frequent allocations and deallocations of data, programmers often introduce free lists. A free list contains a block of available, already allocated, data structures. When code requires a new instance of a data structure, it can grab one of the structures off the free list rather than allocate the sufficient amount of memory and set it up for the data structure. Later on, when the data structure is no longer needed, it is returned to the free list instead of deallocated. In this sense, the free list acts as an object cache, caching a frequently used type of object. One of the main problems with free lists in the kernel is that there exists no global control. When available memory is low, there is no way for the kernel to communicate to every free list that it should shrink the sizes of its cache to free up memory. In fact, the kernel has no understanding of the random free lists at all. To remedy this, and to consolidate code, the Linux kernel provides the slab layer (also called the slab allocator). The slab layer acts as a generic data structure-caching layer. The concept of a slab allocator was first implemented in Sun Microsystem's SunOS 5.4 operating system[5]. The Linux data structurecaching layer shares the same name and basic design.
The slab layer attempts to leverage several basic tenets:
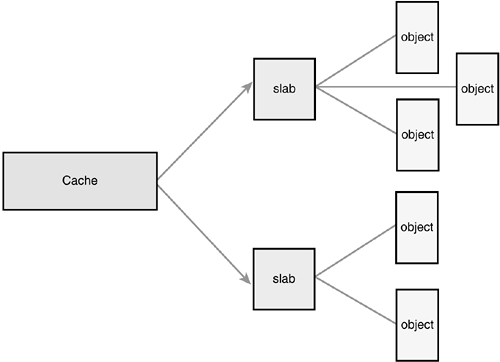
The slab layer in Linux was designed and implemented with these premises in mind. Design of the Slab LayerThe slab layer divides different objects into groups called caches, each of which stores a different type of object. There is one cache per object type. For example, one cache is for process descriptors (a free list of task_struct structures), whereas another cache is for inode objects (struct inode). Interestingly, the kmalloc() interface is built on top of the slab layer, using a family of general purpose caches. The caches are then divided into slabs (hence the name of this subsystem). The slabs are composed of one or more physically contiguous pages. Typically, slabs are composed of only a single page. Each cache may consist of multiple slabs. Each slab contains some number of objects, which are the data structures being cached. Each slab is in one of three states: full, partial, or empty. A full slab has no free objects (all objects in the slab are allocated). An empty slab has no allocated objects (all objects in the slab are free). A partial slab has some allocated objects and some free objects. When some part of the kernel requests a new object, the request is satisfied from a partial slab, if one exists. Otherwise, the request is satisfied from an empty slab. If there exists no empty slab, one is created. Obviously, a full slab can never satisfy a request because it does not have any free objects. This strategy reduces fragmentation. Let's look at the inode structure as an example, which is the in-memory representation of a disk inode (see Chapter 12). These structures are frequently created and destroyed, so it makes sense to manage them via the slab allocator. Thus, struct inode is allocated from the inode_cachep cache (such a naming convention is standard). This cache is made up of one or more slabsprobably a lot of slabs because there are a lot of objects. Each slab contains as many struct inode objects as possible. When the kernel requests a new inode structure, the kernel returns a pointer to an already allocated, but unused structure from a partial slab or, if there is no partial slab, an empty slab. When the kernel is done using the inode object, the slab allocator marks the object as free. Figure 11.1 diagrams the relationship between caches, slabs, and objects. Figure 11.1. The relationship between caches, slabs, and objects.
Each cache is represented by a kmem_cache_s structure. This structure contains three listsslabs_full, slabs_partial, and slabs_emptystored inside a kmem_list3 structure. These lists contain all the slabs associated with the cache. A slab descriptor, struct slab, represents each slab:
struct slab {
struct list_head list; /* full, partial, or empty list */
unsigned long colouroff; /* offset for the slab coloring */
void *s_mem; /* first object in the slab */
unsigned int inuse; /* allocated objects in the slab */
kmem_bufctl_t free; /* first free object, if any */
};
Slab descriptors are allocated either outside the slab in a general cache or inside the slab itself, at the beginning. The descriptor is stored inside the slab if the total size of the slab is sufficiently small, or if internal slack space is sufficient to hold the descriptor. The slab allocator creates new slabs by interfacing with the low-level kernel page allocator via __get_free_pages():
static void *kmem_getpages(kmem_cache_t *cachep, int flags, int nodeid)
{
struct page *page;
void *addr;
int i;
flags |= cachep->gfpflags;
if (likely(nodeid == -1)) {
addr = (void*)__get_free_pages(flags, cachep->gfporder);
if (!addr)
return NULL;
page = virt_to_page(addr);
} else {
page = alloc_pages_node(nodeid, flags, cachep->gfporder);
if (!page)
return NULL;
addr = page_address(page);
}
i = (1 << cachep->gfporder);
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
atomic_add(i, &slab_reclaim_pages);
add_page_state(nr_slab, i);
while (i--) {
SetPageSlab(page);
page++;
}
return addr;
}
This function uses __get_free_pages() to allocate memory sufficient to hold the cache. The first parameter to this function points to the specific cache that needs more pages. The second parameter points to the flags given to __get_free_pages(). Note how this value is binary OR'ed against another value. This adds default flags that the cache requires to the flags parameter. The power-of-two size of the allocation is stored in cachep->gfporder. The previous function is a bit more complicated than one might expect because code that makes the allocator NUMA-aware. When nodeid is not negative one, the allocator attempts to fulfill the allocation from the same memory node that requested the allocation. This provides better performance on NUMA systems, where accessing memory outside your node results in a performance penalty. For educational purposes, we can ignore the NUMA-aware code and write a simple kmem_getpages():
static inline void * kmem_getpages(kmem_cache_t *cachep, unsigned long flags)
{
void *addr;
flags |= cachep->gfpflags;
addr = (void*) __get_free_pages(flags, cachep->gfporder);
return addr;
}
Memory is then freed by kmem_freepages(), which calls free_pages() on the given cache's pages. Of course, the point of the slab layer is to refrain from allocating and freeing pages. In turn, the slab layer invokes the page allocation function only when there does not exist any partial or empty slabs in a given cache. The freeing function is called only when available memory grows low and the system is attempting to free memory, or when a cache is explicitly destroyed. The slab layer is managed on a per-cache basis through a simple interface, which is exported to the entire kernel. The interface allows the creation and destruction of new caches and the allocation and freeing of objects within the caches. The sophisticated management of caches and the slabs within is entirely handled by the internals of the slab layer. After you create a cache, the slab layer works just like a specialized allocator for the specific type of object. |