11.1. Data FeedsOn the read-only push side of things, there are interesting ways in which we can keep users updated with the latest pertinent data, funneling them back to the Web for interactivity. Other than email, a method of data push that is becoming increasing fashionable is to offer data in the form of XML-based feeds. A feed in its simplest form offers a chronological list of dated data items. Each item can contain things like an author, a title, a textual or HTML body, a timestamp, a persistent URL, and enclosures. The feed itself can have a title, description, author, update timestamp, and a whole host of bells and whistles, depending on the format. Feed files typically contain between 10 and 20 of the latest items, with 15 being the standard. In all cases, feeds use no transport protocol beyond simple file-oriented HTTP. Each feed, although often dynamically generated, is comprised of an XML file on a web server. Feed reader software then fetches the feed from a given URL, parses it, and displays it to the user in a pleasing manner, usually keeping track of what the user has and hasn't seen. The user can then be presented with an item "inbox" and in this way feeds can be thought of as a read-only email. The key difference is that there's no feedback mechanism at allitems are never deleted from a feed by the user, but drop off the bottom of the item list as they become older. Each item has some kind of GUID (often a URL) to allow the feed reader to uniquely identify it and remember what it's already seen. By refetching the feed periodically (once an hour is common), the feed reader can find new items as they appear and add them to the list of "new" items for the user to read. Like any good Internet technology from the last 10 years, there are multiple mutually exclusive formats for organizing and presenting this data, all of which have different required and optional fields and need different software to read them. We'll cover the most important three first. 11.1.1. RSSThe history of RSS is a little confusing. The most confusing element of the RSS story is that there are at least 10 different standards all called RSS, all of which are subtly or wildly incompatible. Also, confusingly, RSS has three different acronyms and can also be used as a word. To confound the matter further, there are two standards with the same nameRSS 0.91 and RSS 0.91: can you tell the difference? RSS was first created in 1999 by Dan Libby at Netscape as a method of disseminating news from my.netscape.com. It then branched into two forks that haven't yet converged: UserLand Software's RSS 0.91 branch is based on XML, while the RSS-DEV working group's RSS 1.0 branch is based on RDF. An incomplete list (complicated by the fact that many versions were released multiple times with subtle changes but no version number increase) is shown in Table 11-1.
The 1.0 RDF branch will be discussed in the next section, so for now we'll focus on the 0.91 branch, which culminated in the 2.0x specifications. In the example below, we use RSS 2.0 to create a feed of my latest photographs:
<?xml version="1.0" encoding="utf-8"?>
<rss version="2.0">
<channel>
<title>Cal's Photos</title>
<link>http://www.flickr.com/photos/bees/</link>
<description>A feed of Cal's Photos</description>
<pubDate>Mon, 14 Nov 2005 19:22:41 -0800</pubDate>
<lastBuildDate>Mon, 14 Nov 2005 19:22:41 -0800</lastBuildDate>
<generator>http://www.flickr.com/</generator>
<image>
<url>http://static.flickr.com/33/buddyicons/12037949754@N01
.jpg</url>
<title>Cal's Photos</title>
<link>http://www.flickr.com/photos/bees/</link>
</image>
<item>
<title>Andy in a meeting</title>
<link>http://www.flickr.com/photos/bees/63434898/</link>
<description> ... &html; content here ... </description>
<pubDate>Mon, 14 Nov 2005 19:22:41 -0800</pubDate>
<author>nobody@flickr.com (Cal)</author>
<guid isPermaLink="false">tag:flickr.com,2004:/photo/
63434898</guid>
</item>
<item> ... </item>
</channel>
</rss>
RSS 2.0 has some difficulties (such as requiring an email address in the author field), but on the whole is simple and self-explanatory. Nearly all feed-reading software supports both RSS branches (as well as the upstart, Atom), so offering RSS 2.0 is a good catchall that will satisfy nearly all of your users (at least from a practical, if not ideological, point of view). With the recent popularity of podcasting and video blogging, people wanted to find a way to embed media in their feeds such that it could be automatically detected and downloaded in the background by their feed reader software. The enclosures format came out of this desire, and allows linking to simple media resources for each item by including an optional <enclosure> tag:
<enclosure url="{url}" type="{mime-type}" size="{size}" />
Before long, this format was widely adopted, but it still lacked the flexibility that some people wanted for indexing media content, so in December 2004 Yahoo! created the Media RSS specification, which has been revised several times since. Media RSS uses a separate XML namespace (http://search.yahoo.com/mrss) for defining its elements and attributes, with the namespace being aliased to media by convention. Media RSS allows for fairly rich marking up of media files, including support for linking to multiple versions of the same resource, adding complex credits, licensing, and so on. An example from the specification shows how to link to multiple versions of a resource (in this case an MP3) to allow the client to select which version is most appropriate, as well as marking up the media with author and categorization information.
<item>
<title>Cool song by an artist</title>
<link>http://www.foo.com/item1.htm</link>
<media:group>
<media:content url="http://www.foo.com/song64kbps.mp3"
fileSize="1000" bitrate="64" type="audio/mpeg"
isDefault="true" expression="full"/>
<media:content url="http://www.foo.com/song128kbps.mp3"
fileSize="2000" bitrate="128" type="audio/mpeg"
expression="full"/>
<media:content url="http://www.foo.com/song256kbps.mp3"
fileSize="4000" bitrate="256" type="audio/mpeg"
expression="full"/>
<media:content url="http://www.foo.com/song512kbps.mp3.torrent"
fileSize="8000" type="application/
x-bittorrent;enclosed=audio/mpeg"
expression="full"/>
<media:content url="http://www.foo.com/song.wav"
fileSize="16000" type="audio/x-wav" expression="full"/>
<media:credit role="musician">band member 1</media:credit>
<media:credit role="musician">band member 2</media:credit>
<media:category>music/artist name/album/song</media:category>
<media:rating>nonadult</media:rating>
</media:group>
</item>
Because of its XML basis, RSS can be arbitrarily extended with namespaces to support any needed feature. Because of its widespread adoption, RSS probably isn't going to disappear any time soon and is a good choice if you want to support a single-feed format. 11.1.2. RDFRDF, the Resource Description Format, is a scheme for describing relational data using triples consisting of a subject, predicate, and object. How exactly this relates to the RDF feed format is fairly hazy, but the format exists and is very well specified. Created by the RSS-DEV working group, led by Rael Dornfest, the RDF feed branch was based on Netscape's original RSS 0.9 specification and Dan Libby's subsequent "Futures Document." RDF feeds can be tricky to parse because they are constructed using multiple namespaces (RSS, RDF, and usually Dublin Core at a minimum), which work together to describe the feed. The structure is essentially the same as the other RSS branch, with a single outer element containing a list of zero or more items, each with some relevant metadata. The Dublin Core namespace is usually used to markup dates and authors. An example will describe it most clearly:
<?xml version="1.0" encoding="utf-8"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:admin="http://webns.net/mvcb/"
xmlns="http://purl.org/rss/1.0/"
>
<channel rdf:about="http://www.flickr.com/photos/bees/">
<title>Cal's Photos</title>
<link>http://www.flickr.com/photos/bees/</link>
<description>A feed of Cal's Photos</description>
<dc:date>2005-11-14T19:22:41-08:00</dc:date>
<admin:generatorAgent rdf:resource="http://www.flickr.com/" />
<image rdf:resource="http://static.flickr.com/33/buddyicons/12037949754@N01.
jpg" />
<items>
<rdf:Seq>
<rdf:li rdf:resource="http://www.flickr.com/photos/bees/63434898/" />
...
</rdf:Seq>
</items>
</channel>
<item rdf:about="http://www.flickr.com/photos/bees/63434898/">
<title>Andy in a meeting</title>
<link>http://www.flickr.com/photos/bees/63434898/</link>
<description> ... content here ... </description>
<dc:date>2005-11-14T19:22:41-08:00</dc:date>
<dc:creator>Cal (http://www.flickr.com/people/bees/)</dc:creator>
</item>
<item> ... </item>
</rdf:RDF>
RDF feeds are simple to generate, if not to parse, so adding support into a feed generation layer is fairly trivial. There tends to be little point in offering links to RDF feeds from applications at the moment, unless for political reasons or because of a larger framework based on RDF. Nonetheless, exposing this for third-party developers can show a little goodwill and make your data easier to work with for people who already have RDF-based systems. 11.1.3. AtomThe RSS/RDF fork caused a lot of argument among the data syndication crowd as people released incompatible standards over each other, none of which really built on the previous versions or moved the formats forward. As a result, the Atom specification (originally named Pie, then Echo or Necho) was developed by a community with an open RFC process, allowing anybody to contribute. Atom 1.0 was released in July 2005 after just over two years of design process and was submitted to the IETF standards body. The Atom specification goes beyond simple data feeds into the full catalog of data manipulation tasks. Atom was designed to be a replacement for both the RSS/RDF feed formats as well as the Blogger/MT publishing formats, which we'll discuss shortly. For around two years, Atom languished in an unreleased state at version 0.3. However, this didn't stop widespread adoption, so when the specification was finally published in July 2005, there was already support for it in all major feed reader software and weblog publishing tools. Atom 1.0 varies quite a lot from the 0.3 draft, but mostly in its stylistic renaming of elements and attributes. Atom uses a single namespace, making it simple to write and parse, but very easy to extend. The example RSS feed marked up as Atom looks like this:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<feed xmlns="http://www.w3.org/2005/Atom">
<title>Cal's Photos</title>
<link rel="self" href="http://www.flickr.com/photos/bees/feed/" />
<link rel="alternate" type="text/html" href="http://www.flickr.com/photos/bees/"/>
<id>tag:flickr.com,2005:/photos/public/12037949754@N01</id>
<icon>http://static.flickr.com/33/buddyicons/12037949754@N01.jpg</icon>
<subtitle>A feed of Cal's Photos</subtitle>
<updated>2005-11-15T17:24:54Z</updated>
<generator uri="http://www.flickr.com/">Flickr</generator>
<entry>
<title>Andy in a meeting</title>
<link rel="alternate" type="text/html" href="http://www.flickr.com/photos/bees/
63434898/"/>
<id>tag:flickr.com,2005:/photo/63434898</id>
<published>2005-11-15T03:22:41Z</published>
<updated>2005-11-15T03:22:41Z</updated>
<content type="html"> ... content ... </content>
<author>
<name>Cal</name>
<uri>http://www.flickr.com/people/bees/</uri>
</author>
</entry>
<entry> ... </entry>
</feed>
The main difference between RSS and Atom is the inclusion of GUIDs in Atom feeds for both the feed itself and each item. This allows feed readers to avoid displaying the same entry twice if it appears in multiple feeds. This GUID, stored in <id> elements, must be expressed as an IRI, or Internationalized Resource Identifier. The convention is to use the tag scheme defined in RFC 4151. Atom is seeing widespread adoption, with some large feed generators (such as Blogger) using it as their default offering. Because of its support for creating and modifying content, Atom may emerge at the single de facto standard in the future, but for the moment, all three formats get a reasonable amount of usage. 11.1.4. The OthersIt's worth pointing our that RSS, RDF, and Atom aren't the only formats of this kind. There were a few precursors to Netscape's RSS as well as a few other competing formats and parodies since. We'll briefly summarize the important ones. It probably all started in December 1996 with the design of the Meta Content Framework (MCF) by Ramanathan V. Guha at Apple. MCF didn't originally use XML (it used a simple ASCII format instead) but was designed to create data feeds. On March 10, 1997, Microsoft submitted its specification for CDF, the channel definition format, to the W3C. CDF was the basis for "Active Channels" in Internet Explorer 4, but never really caught on as a format and was dropped by the W3C. In June of 1997, the MCF format was updated by Guha (then at Netscape) to use XML. In December of 1997, Dave Winer created the ScriptingNews syndication format, apparently based on MCF, to syndicate his weblog. A year and half later, Netscape created RSS 0.9. 11.1.5. Feed Auto-DiscoveryAt some point somebody had the sense to hide the confusing mechanisms behind RSS from users. Mozilla (and by extension, Firefox) allows users to subscribe to site feeds without having to know what they are by presenting an RSS button in the browser chrome, as shown in Figure 11-1. Users can click this button to add the feed straight to the built-in reader, never having to look at an ounce of XML or a feed URL. Figure 11-1. The RSS button in Firefox They do this by looking into the page's source HTML and searching for link elements in the header pointing to feed URLs. We can specify as many as we want for each page, with each consisting of a mime-type, a title, and the URL:
<link rel="alternate" type="application/rss+xml"
title="My RSS feed" href="{rss-url}" />
<link rel="alternate" type="application/atom+xml"
title="My Atom feed" href="{atom-url}" />
This is pretty simple, effective, and self-explanatory. Adding them to your feed-providing application should give a reasonable return for minimum effort. 11.1.6. Feed TemplatingSo what format should we be exposing our data in? If we pick one, then users whose readers don't support it won't be able to use our data. This is becoming less of an issue as the standards settle and congeal. RSS 2.0 is supported by nearly every reader and is expressive enough for most purposes (media RSS, enclosures, etc.). Still, with good autodiscovery, we can offer a couple of different feed formats without having to have the user choose which they want. The question then is how do we offer several formats without duplicating work for every additional feed and format we want to support? As with so many components of our application, we can achieve this easily by abstracting the output of feeds into a logical layer. We can easily slide this layer, shown in Figure 11-2, in between our existing infrastructure. Figure 11-2. Adding a syndication layer to existing applications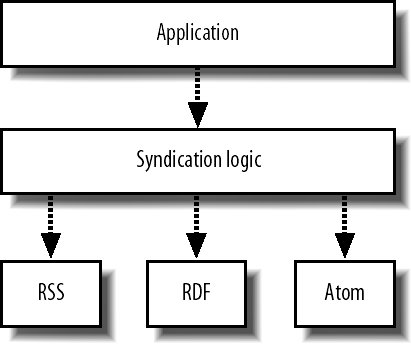 Instead of outputting feeds directly from our interaction logic layer, we create a templating "markup" layer through which all of our feed data flows. In exactly the same way we interact with our web page templating layer, we need only present the necessary structured data to the templating layer, which can then munge it into the particular feed the user asked for. All we need to do is abstract the various formats and figure out what data is needed to satisfy them all. This turns out to be fairly simple. Aside from the data items, each feed has the following properties:
Once we've satisfied those requirements, we need to create one or more data items (in fact, zero is fine, but useless). The data required to satisfy nearly all formats is comprised of only a few fields:
Once we have this information, we can pass it to our syndication layer to render into a feed. Because all feed formats use the same data structure, we can implement caching in the application layer to cache a feed regardless of its output format. By caching a serialized version of the feed data, we can use the data cached when building an RSS feed to build another RSS feed, an RDF feed, or whatever our users request. In fact, we don't have to limit ourselves to the usual XML-based data formats. We can easily build in support for additional formats to help external application developers quickly leverage our data and we can do it all without having to add code in multiple locations; we only modify the output-rendering code in the syndication layer. For general purpose application building, we can export generalized and easy to parse formats like CSV and TSV. For the scripting languages, we can output either source code to be executed directly (Perl, PHP, Python, Ruby, or JavaScript source code) or native serialized object data (PHP's serialize format, or Perl's Storable.pm format). If we wanted to get a little cutting edge, we could offer feeds in JSON. The point is that this layered abstraction makes it trivial to add any format we might need. 11.1.7. OPMLThe outline processor markup language standard (OPML) provides a metainterface to our already meta-heavy feeds. Although originally designed as a multipurpose outliner document format, OPML has been adopted as a format for exchanging lists of RSS feeds. If you offer multiple feeds for your usersfeeds of multiple data types or feeds for each of something the user is subscribed to (such as a feed for each of their groups)then you can combine all of the feeds you offer to each user in a single OPML document to allow them to easily subscribe to all their feeds in one go. An OPML list of RSS feeds looks a little like this:
<?xml version="1.0" encoding="utf-8"?>
<opml version="1.0">
<head>
<title>My feeds</title>
<dateModified>Mon, 14 Nov 2005 20:57:17 -0800</dateModified>
</head>
<body>
<outline type="rss" text="My Discussions" title="My Discussions"
xmlUrl="http://www.app.com/cal/discuss.rss" />
<outline type="rss" text="My Photos" title="My Photos"
xmlUrl="http://www.app.com/cal/photos.rss" />
</body>
</opml>
Offering an OPML feed is a very simple addition that can add a fair amount of convenience for your users for very little development effort. If you're offering multiple feeds and your users are likely to want to subscribe to several at once, then it can make sense to bundle them together into an OPML feed. 11.1.8. Feed AuthenticationFeeds are a great open format for public data, but it's quite possible you'll want to offer private data via data feeds at some point. Whether it's a view of a user's private data solely for that user or semi-private data for a group of users (such as all my friend's message board topics), you'll need some way to ensure the requesting user has permission to view the data. For pages within the web application, we typically use cookies. The authentication cookies are passed to the web server on every request, and we verify them and serve the private data to the user. Unfortunately, we can't usually do this with a feed reader. There's no mechanism to have the user log in to create their session cookies, so we have no way of finding out who the user is. We'll need to find a new way. The simplest way to achieve this from an implementation point of view is to store some kind of secret in the feed URL. This avoids the situation where we serve private data at guessable URLs and puts all of the security in the URL itself. While simple, this isn't a good general approach. Users aren't accustomed to having logic credentials as part of a URL and so are not trained to keep URLs private. If they share the URL of a feed, complete with secrets, to another user, that user will be able to view their private data. This isn't the end of the world, but neither is it a perfect situation. The next step up the technology ladder presents us with the use of HTTP basic authentication for feeds. Many feed readers support HTTP basic, prompting the user for her login credentials when she subscribes to the feed. While this isn't universally supported, the web-based reader Bloglines (http://www.bloglines.com) supports it and makes up a large portion of all feed subscriptions on the Web; desktop-based applications are following suit. There are problems with HTTP basic, however. Unless you give your users a special username and password for using feeds, then their primary authentication credentials will be passed across the network in something close to plain text. We can get around this limitation by serving our feeds over HTTPS, but this creates a new problem we haven't previously addressed. Supporting HTTPS on a large scale can be a difficult problem, as the key generation and crypto overhead tends to make machines CPU bound. A typical HTTPS setup using Apache with mod_ssl using openssl will be able to handle one-tenth the requests of the same server running regular HTTP. This also means that HTTPS is very vulnerable to DDoS attacks, as a few clients can easily overwhelm the CPU on a server. There are, of course, ways around this. By using an accelerator card to handle the crypto and stunnel (http://www.stunnel.org/) to avoid tying up Apache threads with slow clients and DDoS attempts, you can get a much better performance out of your existing hardware. This topic, however, can easily fill a book. Indeed, it's worth having a look at Ivan Ristic's Apache Security (O'Reilly) and the presentation "High Scalability for SSL and Apache" by Mark Cox and Geoff Thorpe (http://www.awe.com/mark/ora2000/). The Atom project recognized this problem for both fetching and posting data and so standardized on a scheme designed to overcome it. We don't need to send login credentials over the wire in plain text (or easily decrypted data) and we avoid replay attacks (in which somebody intercepts our message, changes some of the payload, and resends it). The scheme is called Web Services Security (WSSE) and uses one regular and one proprietary HTTP header. A WSSE-signed request looks something like this:
GET /feeds/my-private-data/ HTTP/1.0
Host: world-of-feeds.com
Authorization: WSSE profile="cal"
X-WSSE: UsernameToken Username="cal",
Created="2005-11-14T18:40:04-0800",
Nonce="bf59559401b2d9e14964823a37836a76",
PasswordDigest="WgUU6xmxOsGYqhNun9gJZ//C9ew="
The real meat happens in the X-WSSE header, in four parameterized parts. The Username is, fairly obviously, the username to authenticate. The Created parameter is the date at which the request was sent, in a very specific format. The Nonce (short for number used once) is a one-time pad used to make the request unique (to avoid replay attacks). Finally, the password digest contains a hash based on the value of the other parameters and the password, using the following formula: digest = base64( sha1( nonce . created . password ) ) We concatenate the nonce, created date, and password, calculate their SHA1 sum (SHA1 is the Secure Hash Algorithm) and then use the base64-encoded representation of this as our password digest. There are some problems with WSSE in practice. First, the specification was cloudy as to whether a binary or ASCII hexadecimal representation of the SHA1 sum was to be used, although the binary version seems to be the intention, hence the need for the base64 encoding to make the digest 7-bit safe. Different vendors have implemented their support using each of the two alternatives, creating mutually exclusive systems. Another problem is with using the date field as part of the digest. For this to provide any security whatsoever, the server must check that the date is recent. For this check to be meaningful, the client and server must agree upon a time. In practice, this means that the client first needs to make some other request for the resource (such as an HTTP HEAD request) to get in sync with the server's clock. The use of a nonce creates additional problems for server implementations. For the nonce to provide protection against replay attacks, we need to make sure that the nonce being passed has not recently been used by the client. For this, we'll need to keep track of all nonces used, for at least the acceptable divergence allowed in the creation date value. For high-volume applications, this can be a lot of data to track. All of these problems are solvable, but there's an additional problem with WSSE that, for some applications, is unfortunately unsolvable. When a server receives a password digest, the server needs to perform the same hashing function used by the client to generate a digest to compare against. All the components of the digest are sent along with the request, except the password itself, so to create the digest, we just need to pull the password from the user's account record and concatenate it with the other passed in parameters. The issue here, of course, is that we probably don't store the user's password in a format from which we can extract the required plain text version. Most applications with a hint of secure design will store user passwords in some kind of salted hash. When a user sends in a (plain text) password, we perform the same salted hashing function on the password and compare it to our stored version. Because of this, there's no way for many applications to verify a WSSE digest. A possible alternative, while a little ugly, is to use a different password for WSSE authentication. Either a separate user-generated password that we store in plain text or a hash based on other user data (such as the hashed password we store) could be used as long as we can get the plain-text version to build the digest on the server side. At the moment WSSE support in reader implementations is low, but this may change in the future as Atom becomes a more recognized standard. |