8.1. Identifying BottlenecksNot all bottlenecks are created equal. Some are going to be trivial fixes, while others will take architectural changes, hardware purchases, and large data and code migration to fix. Before spending any time on attempting to fix the speed problems within our application, we're going to want to take a look at everything that could possibly be slowing us down and get a good sense of what we should direct our time toward. We want to avoid getting into a situation where we spend a long time working on a fix that gives us a 1 percent performance boost, while we could have gotten a 10 percent boost in half the time by modifying another component. When we say we want to find bottlenecks, what we really mean is that we want to find the areas of the application in which the most time is spent. The time between a request coming into the outer edge of our network and the response leaving (as well as any cleanup from the operation such as writing to disk, freeing memory, etc.) is the time we're looking at. If we're spending 80 percent of that time reading files from disk, then that's our bottleneck. If we're spending 70 percent of our time waiting for database calls to respond, then our bottleneck lies somewhere inside the database system. In the case where our request response cycle is already very, very fast, we want to look at where we start to spend our time as the service is used more often. In many cases, the bottlenecks will move as we increase the load on the application. The reason for this discrepancy is fairly simple; the time spent performing certain operations is not always directly proportional to the rate of concurrency. Imagine we have a fairly simple software message dispatcher that runs as a core component of our system. With low to medium traffic, events are dispatched within 20 ms. When the load gets high, the average time for events reaches 200 ms. While our bottleneck during low traffic may have been disk I/O, it becomes message dispatch as the system becomes loaded, as shown in Figure 8-1. Figure 8-1. Watching response time increase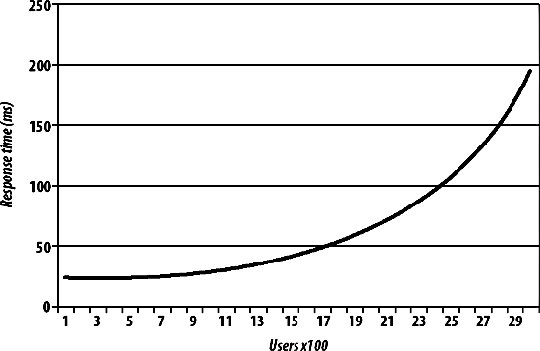 This ties in nicely to Chapter 9, where we'll look at scaling, but identifying bottlenecks is an important step before (and during) the scale out of your hardware platform. If your application can support 1,000 concurrent users per server, but it would take a couple of weeks' work to bump it up to 2,000, then it's going to be much cheaper to work on bottlenecks first. Adding hardware to support growth is not only expensive but isn't usually available instantly (depending on your vendor). To squeeze the most out of your existing hardware or to at least get reasonable performance out of it, you'll need to optimize the trivial parts of your application and infrastructure. The best way to approach this is by carefully identifying all of your bottlenecks and then working to fix the lowest hanging fruit with the highest estimated gains. The corollary to this is that you don't want to spend too much time on optimization. Unless a single component in your hardware platform has hundreds or thousands of nodes, then taking lots of developer time to gain tiny performance boosts does not make sense. The calculation is fairly simple, although determining the values to use is tricky. If the cost of the developer time required to get the performance gain is more than the TCO of the additional hardware needed to get the same boost, then you should buy the hardware. Of course, the tricky part is figuring out how much developer time it will take (you often need to double how much it will cost, since you're not only spending developer time on it, but losing developers that could be working on other aspects of the application) and how much performance boost you'll get from the work. Even once you've factored those in, you might need to think about the cost in the futurewhen your application is 10 times the size, will the cost of 10 times the extra hardware be worth skipping the development now? If that is the case, is it worth doing the development work now, or planning for it in the near future? This all assumes you already have a horizontally scalable architecture and that adding more hardware is an option. The next chapter will deal with this in detail. Before we can start fixing anything, we're going to need to find out where we're spending our time. We can do this first by examining the different areas of our application where we can possibly be spending too much time. Once we've identified where our time is going, we can look into that particular component closely and identify the different areas within it that can act as bottlenecks. At this point, we tend to get down to the hardware/OS level and see what's going on outside of our user space code. 8.1.1. Application Areas by Software ComponentThe most logical way to break down our applications tends to be into logical components . A logical component is a conceptual piece of the puzzle, in contrast to the physical components , which consist of tangible hardware. Before you start any work on optimizing components of your application, take a few minutes to create a logical diagram of how the components fit together. Figure 8-2 shows a portion of the Flickr bottleneck map to give you a rough idea of a suitable level of details. Figure 8-2. Flickr's bottleneck map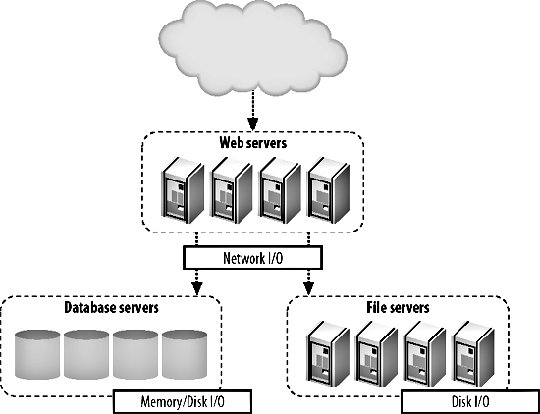 The first and most obvious component is dynamic web serving. This component includes the software you're using to receive HTTP requests (typically Apache) and to service those requests (such as PHP or mod_perl). If this layer of your architecture sits closer to the user, any delays in layers underneath are going to be visible in this layer. The dynamic serving layer appears to take up the entire time between request and response, but we know that underneath it's dispatching to other components in our system to service the request. The portion of time that we spend actually within the dynamic web serving layer can be bound by CPU, I/O, and context switching. Next to dynamic web serving comes its much easier cousin, static web serving. For smaller applications, you'll typically bundle these activities together, using a single web server to serve both static and dynamic content. The serving of static content is very rarely CPU bound, but is often I/O bound (and sometimes incurs context-switching overhead). The other large component of any dynamic web application is the data store layer, usually an RDBMS. In our examples we're talking about MySQL, but other database systems are equally valid, including simple key value systems such as Berkeley DB. In general, the bottleneck in these systems is I/O of some kind, although given enough I/O bandwidth, you'll start to see CPU-bound processes or memory limits, depending on the size of your working set. Running out of memory, as we'll discuss shortly, usually manifests itself as an I/O problem as we start to swapbut let's not get ahead of ourselves. If we're storing large chunks of data or data that needs to be served as static content, then our application may well be reading and writing to files on disk. File I/O is an application component in and of itself and presents its own issues. Unsurprisingly, file I/O operations are usually I/O bound. If your application contains any custom-built components (or any components not usually found within a web application), then these can create their own problems. If your application contains a graph-server component for storing the relationships between users, then it might be bound by CPU, memory, or I/O, depending on your design. For components you design yourself, you need to think carefully about what your limiting factors will be from the outset and design accordingly. If you can design your components from the start to allow horizontal scalability, then expansion later becomes simple, instead of requiring a rewrite every time you need to increase capacity 10-fold. The other major component of web applications is the external resource: elements that lie outside the boundaries of your system. These components are to a certain extent beyond your control, but nonetheless need to figure into your identification of system resource usage. Beyond finding the limitations of the actual resource, you'll want to consider the bottlenecks caused by the communication with these components. Network communication may by network I/O bound at the simplest level, but can also be disk I/O bound (for large replies) or CPU bound (for replies that require a lot of complex parsing to use). 8.1.2. Application Areas by Hardware ComponentOnce we've identified each of our logical components, we're in a position to examine each of them in detail and see how the time within each component is being spent. This tends to identify the execution path right down at the hardware level. When a database call is taking a long time, we could be spending time on CPU cycles, memory I/O, disk I/O, or network I/O, each of which must be addressed differently, but have the same macroeffectincreasing the time spent inside our logical component (the database in this example). As you examine each logical component and translate it to the physical component its operations are bound by, you can annotate your logical diagram (you did create one, right?) with the limiting factors at each point in the system. Using some of the tools we'll discuss in this chapter, you can estimate how much more capacity you can squeeze out of each component in the system before the bottlenecks start to really hurt you. This is useful information to document and then monitor for. We'll be looking at application monitoring in Chapter 10. When we talk about CPU usage as a bottleneck, we mean the time spent executing instructions inside the processor. This typically includes executing machine code instructions, manipulating data inside the processor, and moving data around in the processor caches. To the naive observer, CPU time is the main bottleneck in every application. In practice you'll find that this is very rarely the case. The real culprit for application performance tends to be I/O, in all its various forms. Disk I/O bites us as we move data between disk and memory and is the cause of a lot of problems. When we already have data in memory and need to move it into processor cache to process it, memory I/O starts to bottleneck us. When we have data ready to send off to another component in our system, network I/O starts to limit our operations. I/O is the general catch-all category for moving data around, which is essentially all that we're doing inside an application. The flow of data between memory and disk is a function of the amount of data we need to work with compared to the amount of memory we have in the machine. Once we run out of memory and start to swap, our previously fast memory I/O and CPU-bound operations become disk I/O bound. Although running out of memory manifests itself as a disk I/O problem (assuming you have swap enabled), it can be useful to treat it as a separate problem. Deciding carefully what data to keep in memory can drastically reduce your memory usage and swapping. As with the logical components, the physical components can also include external services not built as part of your application, including pieces of software running on your own hardware, hardware black boxes, and remote services you don't control. In any of these cases, messing with the guts of the component is not usually possible or desirable. Knowing the limits of these components is still an important piece of understanding the limitations of your system as a whole and should not be ignored. A slow external service can have cascading effects on the parts of the system you do control and planning accordingly is important. There can be other limiting physical components not considered here, especially if you're performing some special task beyond the vanilla web server and database combination. For physical tasks such as printing products or burning disks, you'll have immoveable bottlenecks. While you can't necessarily do anything to speed up the burning of a DVD, it's still important to add this to your logical bottleneck map. Now that we have a full map of the different components in our system, we can start to look at each in turn and determine where the major bottlenecks lie, how to identify and measure them, and take some first steps for reducing them. 8.1.3. CPU UsageCPU processing speed, contrary to popular belief, is almost never a bottleneck in web applications. If you find that your main bottleneck is CPU speed, then it's quite likely you have a problem with your basic design. There are a few exceptions to this rule, but they are fairly easily identified as CPU-intensive tasks. Processing image, audio, or video data, especially the transcoding of data, can be very CPU intensive. Even so, depending on the size of the files being processed, the I/O and context-switching overhead can often exceed the time taken to perform the complex processing. Advanced cryptography can also chew up lots of CPU time, but if you're encrypting large chunks of data, then you're more likely to block on I/O moving the data around than you are actual CPU time. To get an overview of what's eating your CPU time, you can run top on Unix machines. A typical top output might look like this: top - 22:12:38 up 28 days, 2:02, 1 user, load average: 7.32, 7.15, 7.26 Tasks: 358 total, 3 running, 353 sleeping, 0 stopped, 2 zombie Cpu(s): 35.3% us, 12.9% sy, 0.2% ni, 21.8% id, 23.5% wa, 0.6% hi, 5.8% si Mem: 16359928k total, 16346352k used, 13576k free, 97296k buffers Swap: 8387240k total, 80352k used, 8306888k free, 1176420k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 31206 mysql 16 0 14.2g 14g 2904 S 25.2 90.7 0:04.36 mysqld 26393 mysql 16 0 14.2g 14g 2904 S 19.8 90.7 0:13.33 mysqld 24415 mysql 16 0 14.2g 14g 2904 S 7.2 90.7 0:12.61 mysqld 25839 mysql 15 0 14.2g 14g 2904 S 7.2 90.7 0:13.39 mysqld 18740 mysql 16 0 14.2g 14g 2904 S 5.4 90.7 0:24.32 mysqld 30218 mysql 16 0 14.2g 14g 2904 S 5.4 90.7 0:06.52 mysqld 32277 mysql 16 0 14.2g 14g 2904 S 5.4 90.7 0:01.20 mysqld 772 calh 16 0 6408 1124 680 R 5.4 0.0 0:00.04 top 2376 root 16 0 2888 1972 600 R 3.6 0.0 2487:00 rrd-network Depending on your particular operating system, version of top, and settings, the columns shown will vary, but a couple of important statistics are nearly always available. The %CPU column tells us how much CPU time each process is using. By default, the process list is sorted with the most CPU-intensive task at the top. The load average statistic is a very good quick indicator of the general state of the machine. The three figures shown represent the load average over the last 1, 5, and 15 minutes. The load average is calculated by counting the number of threads in the running or runnable states at any one time. The running state means that the process is currently executing on a processor, while the runnable state means the process is ready to run and is waiting for a processor time slice. The load average is averaged out using samples of the queue length taken every five seconds (on Linux), averaged, and damped over the three time periods. The load average is never an indication of how many processes are trying to run at any one moment. A load average of zero indicates that no processes are trying to run. When the load average exceeds the number of processors in a box, there are processes in the queue waiting to run. In this way, the load average is less an indicator of current load and more of an indicator of how much work is queued up, waiting to run. A high-load average will make a box appear unresponsive or slow, as each request has to wait in the queue to get serviced. When the load average for a box is less that its number of processors, there are free CPU cycles to go around. The exact correlation between the load average and the responsiveness of the machine depends on the processes you have waiting. Not all processes are created equal: different priorities are assigned to different jobs. If you have a single high-priority process that's in a running state 80 percent of the time and a pile of lower-priority processes that can eat as much processor time as they can get, then your load average will be high. Despite the number of processes in the run queue, the process we care about (the high-priority one) will always get the execution time it needs, so the box will not appear slow. If we have a 20 processes that all try to claim processor time simultaneously for 30 seconds but remain idle for the next 30 seconds, the load average will be 10 (a run queue of 20 for 50 percent of the time, while 0 for the other 50 percent), although the processor may have been idle for half of the time. The best way to find out what load average is acceptable to your particular application setup is to load-test your hardware and software and note the point at which perceived performance starts to drop. With the exception of the few tasks that rightfully cause CPU bottlenecks, the best way to avoid CPU bottlenecks is to stop doing dumb things. This is hopefully self-evident. If you find that you're spending CPU time inside your own application components, then you'll need to drill down to the next level and figure out exactly where within your code the time is being spent. The best way to find these places in your application is by using a code profiler; let's have a look at what that means. 8.1.4. Code ProfilingCode profiling involves capturing runtime information about the processing of your code for later analysis. By running a profiler against your code, you can identify the points in your software where the most time is being spent. Common outputs from profilers include the lines of code executed the most times, the lines of code that took the longest amount of time to run, the functions and methods that were executed the most, and the functions and methods that the most time was spent in. By looking at both the cumulative time spent inside each function as well as the average time per call for each function, you can quickly identify which parts of your code can be optimized to receive the most immediate benefit. For example, if you have two functions, func_a( ) and func_b( ), you might find that func_a( ) took around 50 ms, while func_b( ) took an average of 5 ms to execute. This data is already fairly obtainable by storing the time either side of a function call and looking at the difference, although it's much easier to run a profiler as your source code doesn't need to be modified. With only this information, we would be sensible to choose to speed up func_a( ) since we're spending 45 ms longer inside it. But of course, that's not the whole picture. What a code profiler provides for us is a way to look at the cumulative effects of running pieces of code in the wider context of your application. While func_b( ) might be 10 times faster than func_a( ), we might find that we're executing it 20 times as often. In this case, a percentage speedup in func_b( ) will improve our overall speed more than the same percentage speedup in func_a( ). For PHP programmers, the open source Xdebug suite of tools (http://xdebug.org/) includes a powerful code profiler. After installing the Xdebug extension, you can call the xdebug_start_profiling( ) function to start profiling the running script. Once you reach the end of your script, you can call xdebug_dump_function_trace( ) to dump out a table of profiling data in HTML (assuming you're running from within mod_php). The dump looks a little like this: Function Summary Profile (sorted by total execution time) ----------------------------------------------------------------------------------- Total Time Taken Avg. Time Taken Number of Calls Function Name ----------------------------------------------------------------------------------- 0.0011480325 0.0011480325 1 *test3 0.0008310004 0.0004155002 2 *test2 0.0006590472 0.0001647618 4 *test1 0.0001198993 0.0000299748 4 rand 0.0001020202 0.0001020202 1 *my_class::my_method 0.0000939792 0.0000939792 1 *my_class->my_method 0.0000349618 0.0000174809 2 explode 0.0000179582 0.0000044896 4 urldecode 0.0000168881 0.0000042220 4 nl2br 0.0000140202 0.0000046734 3 urlencode ----------------------------------------------------------------------------------- Opcode Compiling: 0.0006710291 Function Execution: 0.0028340796 Ambient Code Execution: 0.0010519048 Total Execution: 0.0038859844 ----------------------------------------------------------------------------------- Total Processing: 0.0045570135 ----------------------------------------------------------------------------------- Actually modifying your code to stick profiling hooks in it is a bit cumbersomewhat would be nice is if there was some way we could just profile code as it's being used without touching the code itself. Luckily, Xdebug makes this very easy. By adding a couple of lines to our php.ini or .htaccess files, we can enable transparent profiling. Every time a script on the server is executed, the code is profiled and the results are saved to disk. Profiling code slows down the execution substantially and isn't something you'll want to enable on all of your production web servers. However, if you have a load-balanced pool of web servers, then you can run a small portion of your production traffic through the profiler. Assuming your application can be served on less than all of your web servers, you can disable one of them in the balancer VIP and enable profiling. Most balancers will then let you add the machine back into the VIP with a low weighting so that it receives a less-than-equal share of the traffic. The users who get served pages from the profiling server will get slow pages, but you'll get invaluable profile data from the real production execution of your code. If you're really worried about degrading the user experience for even a minute or so, then you can simulate production traffic on an isolated profiling machine. You simply need to capture the HTTP request sequence sent to a real production server and replay it on the profiling machine. Of course, whenever we say simply we're usually glossing over a very tricky topic and this example is no different. We can probably capture the incoming request stream fine, but if it altered any data on the site, then the next time we replay the sequence, different code will be run. This is especially the case in applications where users are writing rather than just reading. If your application is read-oriented (information retrieval, searches, etc.) then simulating real traffic for profiling is a lot easier. If you're using Perl, then you'll want to take a look at the Devel::DProf module, which is distributed as part of the core module set. It performs all the hard work of profiling and outputs its data in a fairly unreadable format, so you'll also want to pick up a copy of dprofpp and the Devel::DProfPP module to turn the data into something usable. The Apache::DProf module allows you to hook the profiler into Apache running mod_perl to capture profiling data from scripts as they run in production. As with the Xdebug extension, you need only add a single line to your httpd.conf, restart Apache, and you'll be collecting profiling data immediately. Code profiling can be useful for spotting easy fixes to push a little more out of your hardware. At some point, the amount of time saved by code optimization starts to become much less than the time spent on tasks outside of raw code execution. This is often the case from the startthe actual execution time of the code is negligible compared to the other elements of the request-response cycle, specifically the data store access. The profiling data should make this very clear immediatelyif most of your execution time is spent in the mysql_query( ) function, then you know that you're waiting on responses from the database. Code profiling is a good first step in identifying where you're spending time inside the system as a whole. 8.1.5. Opcode CachingIn the example code profiling output, there was a line item for Opcode Compiling which ate up 6.7 ms of our time. What exactly is this opcode complication? If you're using mod_php with Apache, then the start of the request-response cycle looks like this:
Step 4 is the one we're interested in here. Once the source has been read from disk (or more likely, from disk cache), PHP needs to compile the source into something it can execute. Perl, in CGI mode, works in a similar way. Each time a request for a script comes in, PHP needs to load and compile the source again. For a script that's accessed a million times between changes, we'll be performing 999,999 more compile steps than we need to. PHP doesn't have any built-in method for saving the compiled version of a script, so we need extra tools to accomplish this. These tools are called opcode caches because they compile the source code down to opcodes (virtual code that the PHP runtime engine can execute) and cache the opcode version of the script. Upon subsequent requests, they can check the modified time of the file and use the cached compiled version if it hasn't been modified. For applications that have large source code files and a high request rate, opcode caching can make quite a large difference. A time of 6.7 ms per request may not sound like a lot, but for a script 10 times as big, 67 ms is quite a chunk of time. If you're aiming for a 200 ms page serving time (a fairly standard time guideline for applications), then you're spending a third of that time for each request on compilation. The Zend Platform (http://www.zend.com/) is a commercial product from the company founded by the two core engineers for PHP 4 and includes opcode caching. There are a couple of open source alternatives if you don't want to spend any money and they work well in production. Turck MMCache (http://turck-mmcache.sourceforge.net/) is a fairly mature open source opcode cache and optimizer for PHP 4, although it hasn't been in active development for the last couple of years. APC (Alternative PHP Cache) is part of the PECL repository (the C-extension cousin of PEAR, at http://pecl.php.net). It's pretty easy to install and start using, and as such is a good first port of call when you want to add opcode caching to your application. 8.1.6. Speeding Up TemplatesUsing Smarty templates, the template sequence is similar to that for opcode caching. The first time a template is requested, Smarty compiles the template into PHP source before running it. By default, for subsequent requests it checks the modified time on the source files, recompiling it when necessary. If your application has a lot of templates, the initial hit of compiling them can be large. Each time you deploy a changed template, that template will need to be recompiled. If you have several users hit the template at once, it will be rebuilt by each of them in parallel. If you have several web servers, this can result in a template being rebuilt as a many as 100 times when you deploy a change to a popular template. Similar to the opcode compilation, repeating the same compilation process multiple times is a waste of server resources. We can get around this in a similar way to opcode caching by always precompiling our templates before we deploy them out. In Smarty, the following code snippet will compile all the templates in the "templates" folder:
$dh = opendir('./templates/');
while (($file = readdir($dh)) !== false) {
if (preg_match('!\.txt!', $file)){
$smarty->fetch($file);
}
}
closedir($dh);
The code assumes you've already created your Smarty object and called it $smarty. This code will compile all templates that need compiling. Once complete, every one of your templates will be compiled. The process for your production servers is like so: when a request comes in, Smarty looks at the modification time of the file, and compares it to the modification time (mtime) of the compiled version. Since the compiled version is newer, it uses that, skipping the compilation phase. Nice. But we still hunger for more speed! We can cut out the modified time check on production, since we know for sure that our templates are up-to-datewe explicitly compiled them before deploy. We can achieve this simply by modifying the way we create our main Smarty object: $smarty = new Smarty; $smarty->compile_check = 0; We've now told Smarty to never bother checking if the compiled version is up-to-date. We have no compilation phase and no mtime checks. Smarty is smart enough to do the right thing if a compiled version of a template doesn't exist, so the only thing we need to worry about is checking that we've compiled the latest version of the template before deploying it. If you're still concerned about speed and you want to shave a few more milliseconds off your response times, you can perform an extra prebaking step. If your templates are built in nice reusable chunks, then your average page probably has at least a couple of {include} statements in it. To speed up the loading of the compiled template files, we can replace each include statement (assuming it refers to a static template name) with the contents of the included file. This saves PHP from loading each of the included scripts individually. The same technique can be used to compile regular PHP source into a single file, although that requires a little syntactical trickery. An include in this format:
include('library.php');
needs to be replaced with the contents of the included file, but also the start and end PHP tags:
?>{contents-of_file}<?php
Ultimately this won't be much of a win, especially if you're using an opcode cache, since you don't incur the overhead of opening multiple files for each request. It does still avoid a modified time check for each include, so for include-heavy code, it can be a small win for a little cost at deploy time. Of course, we need to be wary of circular references lest we get tied up forever. 8.1.7. General SolutionsCPU time is not often a problem with web applications. Much more often, a problem with disk, network, or memory I/O appears as a processor issue as the processor spins waiting for some other resource. Profiling your code gives important clues as to where the bottlenecks really lie within a system. If you really do need more CPU capacity, you simply need to buy more servers or more powerful processors. Scaling horizontally, which we'll talk about in depth in Chapter 9, is preferential but requires an architecture designed to scale in this way. If you have chunks of code that need to execute in tight loops or perform heavy calculation, then your best bet for performance is going to be to write it in C (or even assembler, for the masochists). PHP has a fairly easy API for writing native code extensions in C, but that's a little outside the scope of this book. The PECL repository has some good examples. For Perl users, writing your tight code in C and then integrating it using XS is also fairly straightforward. perldoc perlxs and perldoc perlxstut will give you enough information to hit the ground running. 8.1.8. I/OI/O is a very broad term, covering the moving of data in and out of everything. Since all we're really ever doing inside our machines is moving data around, we need to break down I/O into the three big sections and address each separately. We'll look at how to measure disk, network, and memory I/O impact within your application and outline some possible solutions. 8.1.9. Disk I/ODisk I/O covers the time spent reading and writing data from disk, or at least the time your application waits for data to be read or written. Caches mean that you don't always have to wait for the physical operation. With a noncached disk, a (very simplified) read request has to seek to find the data, read the data from the disk platter, and move the data from disk into memory. To write data to disk, we get almost the same sequence: the disk first seeks to the write position and then we copy data from memory and write it to the platter. Under Unix environments, we can very easily measure disk I/O using the iostat utility. iostat has two main modes, which measure CPU and device I/O utilization separately. The CPU usage report is invoked by running iostat -c and outputs the following data:
[calh@tulip ~] $ iostat -c
Linux 2.6.9-5.ELsmp (tulip.iamcal.com) 11/05/2005
avg-cpu: %user %nice %sys %iowait %idle
0.88 0.06 3.06 5.46 90.54
Each column gives us a percentage of CPU time allocated to the particular task. The user and nice columns give us the time spent performing user space tasks (in regular and "nice" mode, respectively), while the sys column tells us how much time is being spent on kernel operations. The idle column tells us how much of our time is spent with our processor lying idle. If we see some nonnegligible value here, then we know we're not CPU bound. The column that should interest us is the iowait value, which tells us how much time the processor has spent being idle while waiting for an I/O operation to complete. When we run the same command on a machine which is more I/O bound, we get a very different result:
[calh@db1 ~] $ iostat -c
Linux 2.6.9-5.ELsmp (db1.flickr) 11/05/2005
avg-cpu: %user %nice %sys %iowait %idle
35.27 0.17 19.24 43.49 1.83
Here we're spending almost half of our CPU time doing nothing while we wait for I/O operations. The device report gives us a lot more detail about what kind of I/O we're performing. We invoke it with the extra -x option (Linux 2.5 kernel or higher) to get extended information: [calh@db1 ~] $ iostat -dx Linux 2.6.9-5.ELsmp (db1.flickr) 11/05/2005 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s hdc 0.03 7.72 0.94 2.71 28.12 83.62 14.06 41.81 cciss/c0d0 0.03 432.37 188.30 78.55 1626.32 547.39 813.16 273.70 Device: avgrq-sz avgqu-sz await svctm %util hdc 30.57 0.15 40.04 5.07 1.85 cciss/c0d0 8.15 0.61 2.27 2.75 73.43 The columns are many and complex and are best explained by the manpage, but we'll look at a couple of the pertinent ones here. r/s and w/s are read and write operations per second respectively, while the rkB/s and wkB/s columns show the volume of data read and written in kilobytes per second. The %util column tells us how much of the machine's CPU time was spent working with the particular device. When the number reaches 100 percent, the device is totally saturated and the machine cannot perform any additional processing. The avgqu-sz statistic gives us the average number of I/O jobs in the queue when new jobs were submitted. By graphing this value over time (we'll examine how in Chapter 10), we can see points at which the device becomes saturated and jobs start to queue. Identifying issues as they happen is not a great long-term strategy. Instead of constantly working to put out fires, it's much less stressful and time-consuming to plan ahead and deal with I/O issues before they start to degrade system performance. Given your specific set of hardware and I/O requirements, running some intensive benchmarks to measure performance can give you a good idea of how much more you can realistically squeeze out of your setup before you'll need to scale out. The programs Bonnie (http://www.textuality.com/bonnie/) and Bonnie++ (http://www.coker.com.au/bonnie++/) provide a suite of benchmarking tools for putting your disks through their paces. They both perform sequential input and output tests and random seeking tests to see how much data you can move around before the device becomes pegged. Bonnie++ goes further and allows you to benchmark different regions of the physical disk, create millions of small files in different directory configurations (to test file table seek times across different file systems), and work with huge files (up to 16 TB). The IOzone tool (http://www.iozone.org/) allows you to perform a similar suite of tests and automatically output them as Excel spreadsheets with graphs. The main limiting factor for disk I/O is the speed of the disk, by which we mean the speed that the disk actually spins at. While the disk in your desktop machine might be spinning at 5,400 rpm, a database server might have 15,000 rpm disks to get a higher data throughput rate. If the head needs to seek to the opposite side of the disk then that operation will take 5.5 ms on a 5,400 rpm disk, but only 2 ms on a 15,000 rpm disk. The faster the disk, the better the I/O throughput. Upgrading the speed of your disks tends to be a lot cheaper than buying more disks or more machines, at least up to a certain speed/price sweet spot. You don't want to be paying twice as much for a five percent speed increase, although it's important to remember it's not just the cost of the disks themselves, but also the controller, enclosure, space, power, and maintenance. An important, often overlooked aspect of disk performance is that different regions of the same disk have very different performance characteristics. This comes about because on a single spinning disk, the outside spins faster than the inside, or to put it another way, more distance is covered at the outer edge than the inner edge as the disk spins. Compact disks use a system called Constant Linear Velocity (CLV), which means that each sector, within a track, whether on the inside or outside of the disk, uses the same amount of space. The trade-off is that the disk needs to be spun faster as the inner edges of the disk are being read to allow the head to move over the disk at a constant rate. On modern hard disks, a system called Zoned Constant Angular Velocity (ZCAV) is used, in which the disk platter is split into several zones, each of which stores data at a different density to allow the disk to spin at a constant rate. The performance of a zoned disk looks a lot like Figure 8-3. Figure 8-3. Performance using a ZCAV disk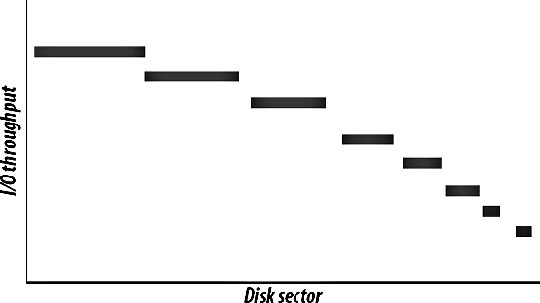 The lower-numbered sectors are (usually) stored on the faster outer edges of the disk (although this is sometimes backward), which gives a much higher performance. The performance for each "zone" of the disk is different, with I/O rates trailing off as we move towards the center of the disk. For this reason, you can maximize disk I/O throughput by using only the outer portion of each disk. Using the outer third of three disks will gain you a lot higher throughput than using the whole of a single disk, ignoring the fact that the I/O is now parallelizable. With modern disks and RAID controllers, read and write operations aren't always going to disk. Controllers and the disks themselves will often have read and write caches (the ratio is sometimes configurable) to buffer data going to and from the physical disks. Read caches work in tandem with your operating system's disk cache, helping to keep often-accessed files in memory. Write caches are used to collect together a group of write operations before committing them to disk, allowing the disk to perform bursts of sequential reads and writes, which improves performance, as shown in Figure 8-4. Figure 8-4. Caching structures for improved performance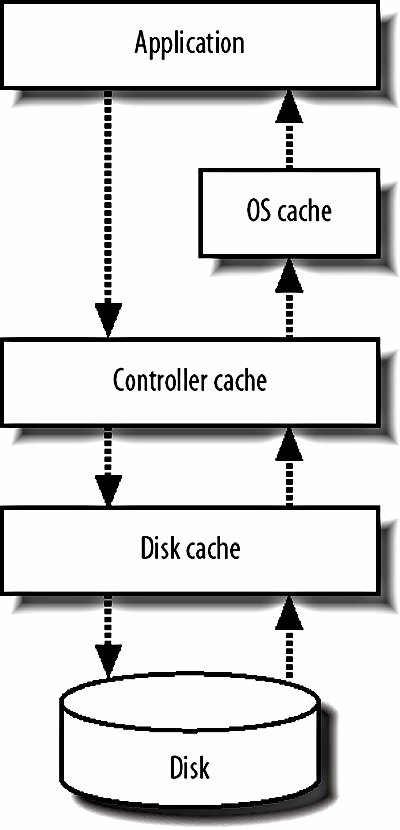 There is a danger with write caches, however. If a machine goes down hard, data that the software believes had been written to disk might still be in the write cache. If this data is lost, the data on disk will be in an inconsistent state (data can be written from the cache in a different order to the requests from the software), and the machine may have to be rebuilt. There's nothing the software can do about this, as it believes the data has been committed to disk (the caching is transparent). Many disk caches have a battery backup. This allows the contents of the write cache to be saved in case of a disaster and applied once power is restored. Using a write cache without battery backup on a critical system is extremely dangerous and should be avoided at all costs. The exception to this rule might be if the operation of restoring the data from another machine is trivial, but this still tends to require far more effort than getting battery backup in place. In the case where a whole data center loses power, all your copies of the data could become corrupt without a battery backup. It's also important to check that write caching on the disk itself is disabled if not battery backed. While the disk controller might have a battery-backed write cache, it's not going to help if the disk has an additional unprotected write cache. In Chapter 9 when we look at scaling our disk I/O systems, we'll examine the different bus technologies and talk about RAID in depth. It's good to know where you'll be going in the future and how we can scale out the disk I/O portions of our hardware platform, but first it's important to get an understanding of where the limits within the existing system are, what causes them, and what we can do to reduce or work around them without buying more hardware. The bottom line with scaling disk I/O, after we've applied all of the caching and zoning optimizations we have at our disposal, is to simply add more spindles. For every disk you add, the read and write performance of the system increases. In Chapter 9 we'll look at ways to increase the number of disks using RAID, as well as at the different I/O bus systems and what each one offers. 8.1.10. Network I/OWhen we talk about network I/O as a bottleneck, we're usually referring to the rate of data we can push between two hosts. The bandwidth we can achieve on a network is gated by both the speed of the slowest device in a chain and by any events along the way. Events can include local issues with either the sender or receiver (such as not having enough memory to buffer the request or response, context-switching mid-transmission, CPU bottlenecking, etc.), issues with devices mid-chain (such as a congested switch plane), or issues with the medium itself. So how can we find out what's going on at the network level? The best frontline tool in an engineer's toolbox is the netstat utility. Netstat can return lots of useful information about the state of interfaces, open sockets, routing interfaces, and protocol-level information for layers three and four. There's plenty of information on the netstat manpage, but a useful way to fetch general interface statistics is via the -i switch: [calh@netmon ~] $ netstat -i Kernel Interface table Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg eth0 1500 0 4174722041 113 85 0 518666800 0 0 0 BMRU lo 16436 0 16794176 0 0 0 16794176 0 0 0 LRU For each interface we see the number of frames sent and received OK, failed, and dropped. For a more detailed view, we just need to include the interface name and the extended output switch:
[calh@netmon ~] $ netstat -ieth0 -e
Kernel Interface table
eth0 Link encap:Ethernet HWaddr 00:12:3F:20:25:0E
inet addr:70.143.213.60 Bcast:70.143.213.255 Mask:255.255.255.0
inet6 addr: ff80::200:2fef:ff12:20e0/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:4174769641 errors:113 dropped:85 overruns:0 frame:15
TX packets:518697987 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1529648717 (1.4 GiB) TX bytes:793133912 (756.3 MiB)
Base address:0xecc0 Memory:dfde0000-dfe00000
We can then use the statistics switch to show protocol-level detail for all interfaces. There's more information here than we'll ever need, but it's good to know where to look to check packets are being sent and received correctly:
[calh@netmon ~] $ netstat -s
Ip:
4096506179 total packets received
0 forwarded
0 incoming packets discarded
673357441 incoming packets delivered
529958063 requests sent out
144 dropped because of missing route
82 fragments dropped after timeout
2317086 reassemblies required
397469 packets reassembled ok
203 packet reassembles failed
130967 fragments received ok
...
I'm personally a big fan of slurm (http://www.wormulon.net/projects/slurm), which graphs the incoming and outgoing bandwidth usage on a single network interface in real time:
-= slurm 0.3.3 on petal.iamcal.com =-
x
x x x
x x x x x
x x x x x x
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
xx
xx
x
x
Active Interface: eth0 Interface Speed: 125 MB/s
Current RX Speed: 9.82 KB/s Current TX Speed: 21.10 KB/s
Graph Top RX Speed: 46.65 KB/s Graph Top TX Speed: 244.49 KB/s
Overall Top RX Speed: 46.65 KB/s Overall Top TX Speed: 244.49 KB/s
Received Packets: 1205721060 Transmitted Packets: 1083353266
GBytes Received: 3.392 GB GBytes Transmitted: 2.698 GB
Errors on Receiving: 0 Errors on Transmission: 0
By having a real-time visualization of traffic, we can poke and tune things and get immediate feedback about how they affect network performance. Network I/O should rarely become an issue in production systems unless something has been misconfigured, you're serving a huge amount of traffic, or you have some very special application requirements. The baseline technology for networks between machines tends to be 1000-baseT (at the time of this writing, 10 GbE isn't really catching on and hasn't yet been ratified as an ISO standardit's currently the supplementary standard IEEE 802.3ae). One thousand megabits is a lot of bandwidth, so under normal circumstances, you shouldn't be filling a pipe that wide. However, some traffic patterns can cause contention, and due to the design of Ethernet, you'll never actually reach the full 1,000 Mb theoretical cap. But before we talk about really reaching the limits of our hardware, we need to address the common problem of misconfiguration. Modern NICs, switches, and routers tend to be autosensing, allowing them to automatically switch between 100/1000 or 10/100/1000. Plugging two of these ports together, as often happens, can sometimes cause them to "negotiate" a lower rate than they both allow. Couple this with the autosensing of full versus half duplex and instead of 1,000 Mb in each direction, you'll get 5 instead. And a 5 Mb limit is a lot easier to hit. When using autosensing ports, you should either be check to make sure they've selected the correct speed or, if possible, set the speed manually. This needs only to be done at one end of the connection and is easily done as part of the machine setup and configuration phase. We said earlier that the nature of Ethernet causes us problems, but it's not always evident why this is the case. If we connect two machines directly together in full duplex, then we'll see optimal performance, but any more than this and performance starts to degrade. The reason is because of the way the Ethernet protocol works. Each Ethernet network segment can be thought of as a large corridor, along which each host on the segment has an office. When one host has a message to send to another, it simply shouts the message down the corridor and the message is received by the target host. This is all very well until two hosts need to send messages simultaneously. They both shout down the corridor at the same time, and neither message gets received. Both hosts then wait a random amount of time and shout again, hoping not to collide with another sender. This technique is used by Ethernet for sending frames (the sequences of data that contain, typically, IP packets) over the medium and this can cause collisions . The protocol underlying Ethernet is known as Carrier Sense Multiple Access with Collision Detection (CSMA/CD) and is built to detect collisions and resend collided frames. In such a system, collisions cause a cascading effectwhen we try to resend a collided frame over a busy network, it's likely to collide again with a fresh frame. Each frame that collides is also failing another frame (the one it collided with), so as traffic density increases, the overall throughput on the segment drops toward zero. On a network segment where enough hosts are trying constantly to send frames, the throughput of successful messages will be zero. A network segments in which frames can collide is called a collision domain. We now tend to use switches, which create a collision domain per port, rather than the single large collision domain of hubs. Related to collision domains are broadcast domains, which are also important to understand when designing for network traffic. There are a few important protocols other than multicasting in general that need to broadcast a message to multiple hosts. The most important for Ethernet is ARP, the Address Resolution Protocol. We won't explain it in detail here, but the ARP protocol is used for translating IP addresses into MAC addresses (Media Access Control, not Apple) for delivery. This requires certain messages to be broadcast to all hosts on a network. The more hosts we have within a broadcast domain, the more hosts we have that can send simultaneous broadcasts. Because of the nature of the messages being broadcast, they need to transcend collision domains to work, so a switch typically has a single broadcast domain (and chaining many switches together just creates one huge broadcast domain). When broadcast traffic overwhelms a network, regular traffic won't be able to get through as the frames start to collide. You can also get into situations where a broadcast from one host causes a broadcast from another, which multiplies until the network is saturated. Both of these situations are known as broadcast storms. To avoid or mitigate broadcast storms, we need to split our network into multiple broadcast domains. We can do this by using layer 3 devices (or higher) such as routers. When a router receives, for instance, an ARP request for an IP on a different interface, instead of forwarding the broadcast across to its other interface, it responds directly, keeping the broadcast on one side of it. For a fuller explanation of how this works, you can read RFC 826, which defines ARP. When an application's hardware platform has easily identifiable multiple network usages, then splitting these networks up into completely separate subnets can be advantageous. Most rack-mounted servers come with twin onboard NICs, with a PCI slot to add more (one PCI slot can provide up to four ports, given the right NIC). We can thus create multiple subnets and connect a single machine to more than one of them, a process called multihoming . In a simple web server and database server setup, we can separate web and database traffic by creating two subnets, as shown in Figure 8-5. Figure 8-5. Using subnets to separate traffic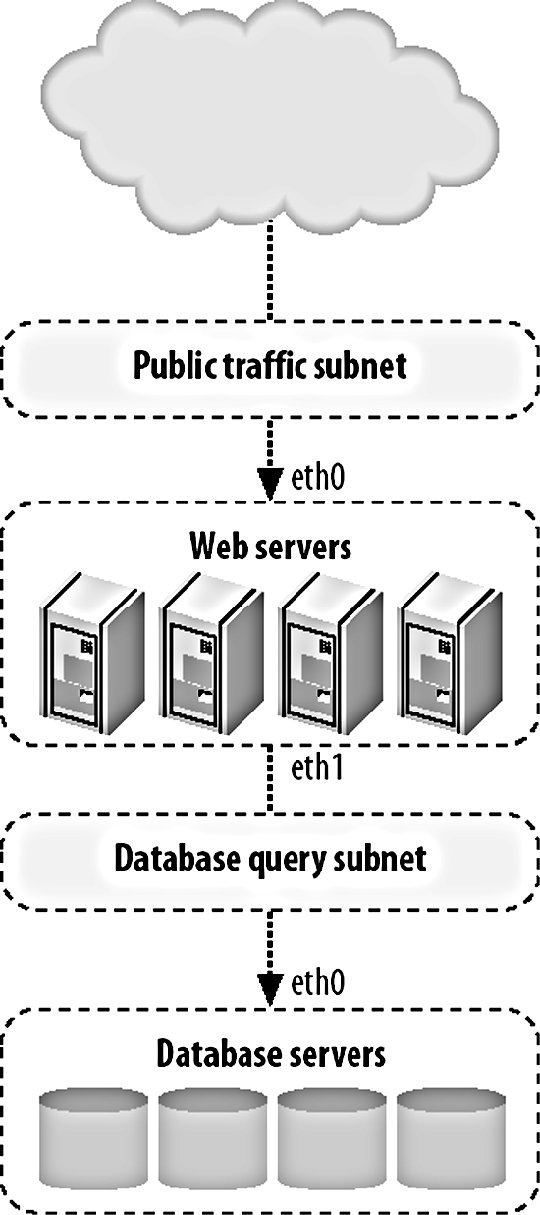 If we're also using database replication (which we'll talk about in Chapter 9) then we might want to separate that out to protect it from our other traffic. We can then create a third subnet, as shown in Figure 8-6, to contain only replication traffic. Figure 8-6. Adding a subnet for data replication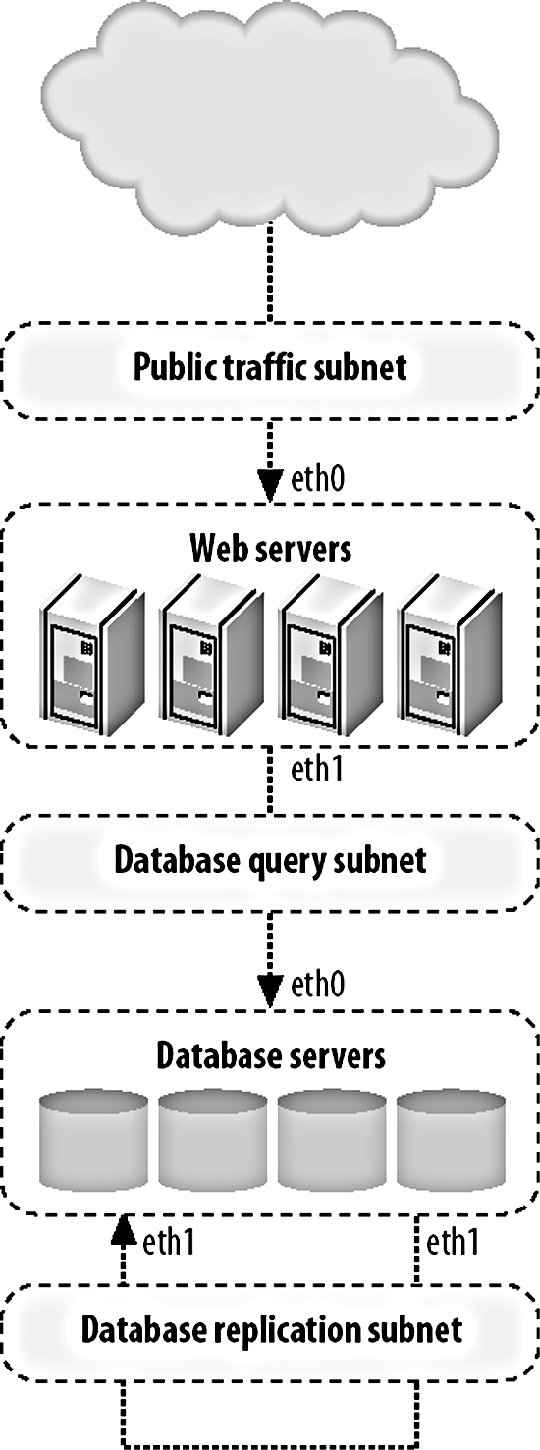 The basic rule of thumb is simple: the fewer hosts and traffic types on a single collision or broadcast domain, the higher (or more predictable) the throughput. If you start to reach a point where collisions are high and throughput is affected, you can start to think about how to split up your traffic into logical and physical segments. 8.1.11. Memory I/OMemory I/O is a little discussed aspect of current hardware architectures. When moving data between disk and memory, the rate is limited by the speed of the disk, since it's the much slower component of the two. When data moves between memory and processor cache, as needs to happen for it to be processed, the memory becomes the bottleneck. Memory I/O is the combined effect of the limits of the read speed of the memory, the write speed of the processor cache, and the bandwidth between the two. Memory I/O is not something that can be easily increased, so these limits can usually be treated as a hard limit. The best way to increase memory throughput is then to add more boxes. Adding an additional machine will double our memory bandwidth, adding a third will give us half as much again, and so on. Because the addition of a machine doesn't impact any existing machines, at least in so far as memory bandwidth is concerned, memory bandwidth scales linearly, which makes it very easy to plan for. In some cases, memory I/O can be enough of a core bottleneck that adding boxes becomes expensive, both in the hardware sense but also as a total cost of ownership (TCO), including power and maintenance. If you're using a standard Intel x86 architecture, then switching to AMD64 can give you a big boost. The AMD64 architecture provides a separate bus between each memory DIMM and each processor, allowing a much more parallel transfer of data from memory. Of course, there are disadvantages to using AMD64you'll need a different kernel, different hardware drivers, and completely different hardware. But it can still be worth bearing in mind, especially since it allows you to easily jump the 2 GB memory limit of 32-bit architectures. 8.1.12. Memory and SwapFinding out how much memory you're using is fairly straightforward; you've probably already seen it as part of the output from top: Mem: 16359928k total, 16346352k used, 13576k free, 97296k buffers Swap: 8387240k total, 80352k used, 8306888k free, 1176420k cached We get a very similar output, though easier to parse, from free, which can return sizes in bytes, kilobytes, megabytes, or gigabytes:
[calh@db9 ~] $ free -m
total used free shared buffers cached
Mem: 15976 15963 13 0 108 2465
-/+ buffers/cache: 13388 2587
Swap: 8190 101 8089
Swap is one of several names given to the virtual memory subsystem. Swap comprises one or more files on disk (called swap files or page files). When the operating system is asked to allocate memory and doesn't have enough free physical memory, it swaps a page of memory (hence swap files and page files) onto disk to free up more physical memory. The next time the page that was swapped out is needed, it gets swapped back into physical memory and something else gets swapped to disk. Because disk I/O tends to be much slower than memory I/O, memory that gets swapped out to disk is very slow to access. We can find out a little more detail about what's going on inside the guts of the memory manager using vmstat. vmstat has several modes, all of which are useful for finding bottlenecksindeed, that's what it was designed for. Virtual memory mode gives statistics about physical and virtual memory, disk mode gives useful statistics about disk I/O (similar to iostat), partition mode breaks down disk I/O by partition, and slab mode give information about various cache usage. The default mode is VM (virtual memory), which displays basic physical and virtual memory usage and some general system statistics. When we invoke vmstat with the -S M flag to report sizes in megabytes, we get the following output: [calh@db7 ~] $ vmstat -S M procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 6 4 73 15 108 2423 2 4 4072 1233 8 2 26 6 32 37 The memory section tells us that 73 MB of swap is allocated, 15 MB of memory is idle, 108 MB is being used for buffering, and 2,423 MB for caching. The rest of the (unshown) memory has been allocated to processes. The swap columns show us the amount of memory swapped in from disk (si) and swapped out to disk (so). If you see a lot of swapping, you'll want to find out what processes are chewing up memory. The previously mentioned top is a good first step, listing processes in order of memory used. The ps utility, with its incomprehensible list of command-line arguments, allows you to get a good idea of what processes are running. A useful set of options are a to select all users' processes, x to select processes without ttys, and l to display output in the "long" format. The result looks a little like this: [calh@db10 /proc] $ ps axl F UID PID PPID PRI NI VSZ RSS STAT TIME COMMAND 4 0 1 0 16 0 4744 468 S 0:07 init [3] 1 0 2 1 -100 - 0 0 S 0:01 [migration/0] 1 0 3 1 34 19 0 0 SN 0:00 [ksoftirqd/0] ... 4 0 11058 1 17 0 43988 1088 S 0:00 /bin/sh /usr/bin/mysqld_safe 4 6899 11090 11058 15 0 13597616 13398132 S 0:11 /usr/sbin/mysqld The RSS column shows the resident set size in kilobytes. The resident set is the portion of the process that is currently in main memory (not swapped out), which differs from the working set that describes the total memory used by the process both swapped in and out. The size of the working set for each process is shown in the VSZ (virtual size) column. It's worth noting that the resident and working set sizes apply to the process tree, not the individual process, so some applications (such as MySQL) will report the total amount of memory used for every process. The pstree command can help you understand which processes own which other processes:
[calh@db14 ~] $ pstree -G
init---acpid
+-agetty
+-atd
+-crond
+-events/0---aio/0
| +-aio/1
| +-kacpid
| +-kblockd/0
| +-kblockd/1
| +-khelper
| +-2*[pdflush]
+-events/1---ata/0
| +-ata/1
...
+-mysqld_safe---mysqld---mysqld---17*[mysqld]
Debian's memstat utility is also worth a look if your system has it. It summarizes all virtual memory allocated, organized by the process or shared object that it's been allocated to. This can be very useful for tracking down which shared libraries are stealing away your memory. If we had a machine with 1 GB of RAM and two running processes that allocated 800 MB, then every time we switched between the applications, we would need to swap out most of the data in physical memory, and then swap it all back when we next change context. If the two processes are frequently switched between, we end up spending all of our time swapping data in and out of memory, rather than doing anything with it. This situation is known as thrashing and should be avoided at all coststhe machine is I/O bound and wasting CPU time. With some specific applications, you should be especially careful not to allow them to swap. MySQL allocates large pools of memory (if configured in the usual manor) that buffers table space data and indexes. If you get into a situation in which MySQL's buffers start to swap, then a read query will read from disk into memory, get swapped out to disk, into memory again, and then finally used. The same is true for Squid, where the memory is used for manually caching objects on disk (assuming you're not using the null filesystem). In any application where the software is explicitly loading data from disk and keeping it in memory (rather than using the OS disk cache), swapping will massively degrade the performance as every piece of data gets read from and written to disk twice. There are two clear routes to reducing swap within an application: either provide more memory or allocate less of it. Allocating less is sometimes all you need to do. If you're running MySQL and it's requesting 900 MB of your 1 GB of RAM, and the OS takes 100 MB, then reducing your MySQL allocation down to 850 MB will avoid obvious swapping (although MySQL is a little flexible about how much memory it'll really allocatethe best method is trial and error). If reducing your memory usage isn't an option, or doesn't get you the performance you need, then adding more memory will help. Plain vanilla 32-bit Linux will support processes up to 2 GB, with a 64 GB hard limit on total memory. With the Physical Address Extension (PAE) kernel patch, 32-bit Linux can support up to 4 GB per process. This is all very well, but sometimes you need a little more room for growth. The 64-bit AMD64 architecture (particularly the Opteron server processor series) allows up to 256 TB of memory per machine, although 32 GB is the current reasonable limit since motherboards with more than 8 slots and DIMMs of more than 4 GBs are hard to come by. By the time you read this, these limitations will probably be less of a factor. This certainly gives a lot more breathing space above and beyond the 32-bit limits, but there's still a ceiling we'll eventually hit. The answer is simple to give but harder to implement: we'll need to split the function out onto multiple machines, each using less memory. We'll talk more about federated architectures in the next chapter. |