Again, we can use the principle behind low-interaction honeypots to learn more about threats in communication networks. We introduce in this section several possibilities to build low-interaction client honeypots. With the help of these tools, you can collect information about malicious attacks in several areas. Our first example will deal with malicious HTML files, but we can extend the basic principle to similar areas — for example, malicious images or other file formats.
The risk involved in running such a solution is rather low. We have a rather good control about what is happening with our low-interaction client honeypots, since we steer the progress of the tool. In addition, you can also safeguard your honeyclient with the help of mechanisms like chroot or Systrace, as outlined in Section 3.7.
Low-interaction client honeypots are likely to have a lower detection rate, since the attack must be known to the client honeypot. New attacks are likely to go unnoticed. However, low-interaction client honeypots, due to their lightweight nature, are easy to deploy and operate and also very speedy in interacting with servers.
In the next section, we present the general setup of a low-interaction honeyclient that can be used to detect malicious websites. We describe the individual building blocks in detail and identify possible caveats. At the end, we show how these building blocks can be linked together and how a possible extension to other areas can be derived.
If we want to find malicious websites, we need to proceed in two steps. In the first step, we try to find suspicious sites. There are a variety of options, some more promising than others. In the second step, we identify whether any of these sites is really malicious. Since we follow the low-interaction honeypot paradigm in this section, we use simple but efficient mechanisms to carry out this identification process. In Section 8.3 we will outline how a more powerful but slower mechanism can be realized with the help of high-interaction honeyclients.
As just mentioned, the first step of this methodology will be to find sites attacking web browsers. We have several options, and our experience shows that the most promising are the following:
Using search engines. Attackers try to boost the rank of their malcontent within search engines so that innocent users also access theses sites when they just use search engines. If we search for "interesting" keywords like warez, casino, or wallpaper, the odds are not bad that we actually find a malicious website. In addition, it would also be interesting to classify the results obtained by keyword to have some statistics about bad words afterward. Using search engines is easy, since many of them provide APIs than can be used to automate queries.
Blacklists. Several organization — for example, Bleeding Edge Threats (http://www.bleedingsnort.com/) — publish blacklists of suspect URLs and IP addresses that we can use as starting points for our search. Figure 8.2 provides several other blacklists you can use. (Thanks to Ali Ikinci for providing this collection!)
http://hostsfile.mine.nu.nyud.net:8080/Hosts.zip http://www.mvps.org/winhelp2002/hosts.txt http://www.hostsfile.org/BadHosts.tar.gz http://hphosts.mysteryfcm.co.uk/download/hosts.zip http://someonewhocares.org/hosts/hosts http://everythingisnt.com/hosts |
Using links found in spam or phishing messages. We can extract links found in spam or phishing e-mails by loking for URLs starting with http:// or similar heuristics. The websites associated with these scams often contain malicious content that we are interested in.
Using so-called typosquattered domains. Typosquatting, also called URL hijacking, is a form of cybersquatting that relies on common mistakes such as typographical errors made by Internet users when surfing the World Wide Web. Imagine that you want to reach http://honeyblog.org. If you type in http://honeynlog.org, you will not get the site you want. If an attacker registers such common "typo domains," he still has a good chance of receiving traffic on his site. An extensive documentation about typosquatting is available at http://research.microsoft.com/URLTracer/ and in a research paper by Wang et al. [108]. They also provide a tool with which you can check a domain for typosquatting attacks.
Using links found in newsgroups. There are pertinent newsgroups within the Usenet hierarchy that are worth monitoring for links that can then be further examinated.
Monitoring instant messaging or other chat tools. Popular instant messaging (IM) tools like AIM or ICQ are often used by malware to spread further. In addition, some pieces of malware propagate further via messages to users within IRC or other similar chat networks. Hence, we can find malicious URLs this way.
The first four options are the most promising and also the easiest to implement. With all approaches, you get a list of suspicious URLs. Of course, the associated website can also be recursively examined — that is, we start with the first URL of the results, download it to our hard disk, extract all links from it, and add those links to our list of suspicious URLs. This way we can crawl suspicious parts of the World Wide Web. In addition, we should use mechanisms to restrict the depth and breadth we crawl, or our focus may be too broad. As a best practice, it has proven to be better to crawl deeper than wider. This way, more domains are visited, and the chances of hitting a malicious site are higher.
For a crawling engine, we can use one of the many available in the Internet. One examples is crawl, which is available at http://monkey.org/~provos/crawl. This crawler is optimized to download JPEG images, but you can also use it to mirror other filetypes. Other popular crawlers include Heritrix (http://crawler.archive.org), the crawler from the Internet Archive, and Web-SPHINX, a multithreaded crawler written in Java. We can also use tools like wget or curl to download the URLs we have extracted from search engines or spam messages. In all cases you should make sure that the User-Agent is set to a value that imitates a legal browser.
The User-Agent field is an HTTP header field that can be used to distinguish a crawler from a human. Attackers often use it to differentiate which exploit is delivered. If the User-Agent points to a crawler, an innocent HTML page is delivered, and if the User-Agent points to a vulnerable version of Internet Explorer, the web page includes an exploit. For wget and curl, you can change it in the following way:
A powerful crawler is Heritrix, the crawler from the Internet Archive (http://www.archive.org/index.php). The goal of the Internet Archive is to build an "Internet library" — that is, a digital library that contains as many documents as possible from the Internet. They aim at offering permanent access for researchers, historians, and scholars to historical collections that exist in digital format. These formats include archived web pages, texts, audio, video, and even software. Since 1996 the people behind the Internet Archive have searched for ways to preserve this kind of data, and as a side project they have implemented the crawler Heritrix. This tool is specially designed for web archiving — that is, downloading a given location as complete as possible. And this is what we need for a low-interaction honeyclient. We have to examine a given location as thoroughly as possible to detect malicious content on these sites. For example, the attacker could embed his malcode in some obfuscated JavaScript within the HTML of the page. Or he could insert a link to a malicious image that triggers an overflow on the victim's machine. Thus, we also need to follow the links, and this is where Heritrix comes in. We will not go into details here, but if you can are interested, you can find more information about the crawler at http://crawler.archive.org.
At this point, we have a mechanism to automatically find and download websites that could be suspicious. We have only downloaded them to our local hard disk and no analysis has happened yet. Therefore, the second step is to analyze the downloaded content to find malicious content in it. A simple way to start such an analysis is checking all files with common antivirus engines. For example, the tool ClamAV even has support to detect malicious web pages that contain, for example, phishing scams or browser exploits, as the following listing shows:
$ /usr/bin/file *.html phish.html: HTML document text setslice-exploit.html HTML document text $ /usr/bin/clamscan *.html phish.html: HTML.Phishing.Bank-44 FOUND setslice-exploit.html: Exploit.CVE-2006-3730 FOUND ----------- SCAN SUMMARY ----------- Known viruses: 76054 Engine version: 0.88.5 Scanned directories: 0 Scanned files: 2 Infected files: 2 Data scanned: 0.03 MB Time: 1.910 sec (0 m 1 s) |
Besides scanning with antivirus engines, we can use more advanced methods like analyzing the content via intrusion detection systems like Snort or custom static analysis.
Figure 8.3 depicts the whole setup of such a low-interaction client honeypot. We have a crawling engine that downloads suspicious websites and other files from the Internet to our honeypot. The input for the crawler is a result of search engine queries with suspicious names (e.g., warez) or URLs extracted from spam messages. All downloaded data is then handed over to a checking engine. This engines analyzes the content two ways. First, we can use antivirus engines to check for known malware or other bad content. Second, we use our own database with malware signatures to search the downloaded files for malicious content. If the checking engine finds something malicious, it generates an alert and notifies the operator of the honeyclient. As you see, the whole design is rather simple, but it is sufficient.

One thing to note is the problem of a revisit policy — that is, how often we check a given suspicious website for new content. Attackers often change the file hosted at a certain location from time to time. This can, for example, be necessary from an attacker's point of view when certain antivirus engines start to detect the first binary. By changing the malware but retaining the original website, the attacker can seed new malware. As a best-practice value, suspicious websites should be crawled on a daily basis to detect such changes.
There are some other issues with crawlers that we will touch on briefly. Active and/or dynamic content like JavaScript, Flash, or similar content can pose a problem, since the crawler normally cannot execute or display this content. Therefore, it could be possible that we miss certain types of exploits. A similar problem can be encountered because we are not using a real browser but just a crawler. This simulation can be noticed by the attacker, and the exploit would then not be served to the honeyclient. An attacker can spot a crawler due to fingerprinting the requests and looking for suspicious signs or unusual timings.
HoneyC is an implementation of the low-interaction client honeypot concept. As just explained, these types of client honeypots do not use a fully functional operating system and web browser to analyze malicious content on the web but use a simulated client. Malicious servers can then be detected by statically examining the web server's response — for example, by searching for exploits with the help of different signatures.
HoneyC uses simulated clients that can solicit as much of a response from a server as necessary for analysis of malicious content. Due to the modular design, HoneyC is flexible and can be extended in many different ways. It can simulate different visitor clients, search via different methods for suspect websites, and analyze the collected data in various ways.
The initial HoneyC version (releases 1.2.x) concentrates on searching for malicious web servers based on Snort signatures. The initial version does not contain any malware signatures yet, but the author plans to add them in the near future. The official website of the tool is http://honeyc.sourceforge.net/, and you can reach a support forum at http://sourceforge.net/forum/?group_id=172208.
The schematic overview of HoneyC is depicted in Figure 8.4. The client honeypot consists of three different components: queuer, visitor, and analysis engine. These modules interact with each other, and the logical flow of information is shown in the figure. The queuer is the component responsible for creating a queue of suspicious servers that should be analyzed further. It can employ several different methods to create the queue of servers as outlined above. Version 1.0.0 of HoneyC contains a Yahoo search queuer that creates a list of servers by querying the Yahoo Search API. Yahoo Search API is a web service offered by Yahoo! that allows an easy access to the search results by this search engine. In version 1.1.2, a simple list queuer was added that lets you statically set a list of server requests to be inserted into the queue. Besides these two components, HoneyC does not offer additional queuers. However, extending the queuer to support additional crawling via other web services or link extraction from spam messages should not be too hard.
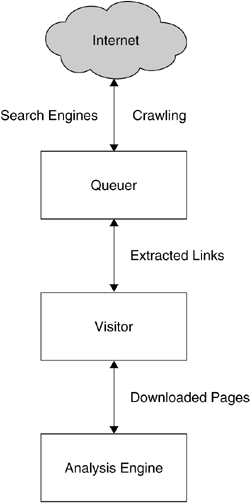
All collected information is handed over to the visitor. This component is responsible for the actual interaction with the suspicious web server. The visitor usually makes a request to the server, simulating a normal web browser. Afterward, it consumes and processes the response. Version 1.0.0 of HoneyC contains a web browser visitor component that allows you to visits web servers.
All information collected by the visitor is then handed over to the analysis engine. This component checks whether a security policy has been violated while the visitor interacted with the web server. This check is currently done via processing the response with the help of a given set of signatures based on Snort. The analysis process is rather easy: A given response from the visitor can be examined via regular expressions that match on either the content of the response or the URL. If one of these rules match, an alert is generated, and some additional information is shown to the user. Please note that version 1.2.0 does not perform an analysis for malicious content with the provided example rules. These check only simple heuristics, and you need to implement your own Snort rules to achieve informative results. The author plans to add more advanced rules in a future release. Several other analysis mechanisms could be incorporated into the tool — for example, checking the downloaded results with common antivirus engines or a behavior-based analysis.
All components let you use pluggable modules to suit specific needs. This is achieved by loosely coupling the components via a command redirection operator — that is, via pipes — and passing a serialized representation of the request and response objects via those pipes. Based on this modular design it is easy to implement a new component as just outlined and to flexible deploy HoneyC. For example, it is possible to extend the queuer component by implementing a web service query via Google's search API, or you could also implement a queuer component that crawls a given URL in Python. Second, a visitor component could simply use a scripted wget request to retrieve the files or an instrumented version of Firefox. Last, the analysis engine can use simple Snort rules to scan for suspect websites or use an emulated environment and study the behavior when accessing the file in that environment.
HoneyC is OS independent because it is written in the scripting language Ruby, which is interpreted. Our experience with the tool is based on running it in a Linux environment, and we strongly advise you to do likewise or on a Unix machine. Most malicious content you will find deals with vulnerabilities for Internet Explorer or other products for Windows. Therefore, you have a much higher risk of infecting your analysis machine if it runs on Windows instead of Linux.
Installation of HoneyC is very easy. In the first step, make sure that you have Ruby installed. Ruby is an object-oriented scripting language and free software distributed under an open source license. If you do not have Ruby installed, please use the package management solution from your Linux distribution — for example, by executing sudo aptitude install ruby on a machine running Debian/Linux. Then download the latest version of HoneyC from the official website and extract the ZIP file. Change into the extracted directory, and start the unit test, which will check whether your system meets all requirements. Please note that you need to have network connectivity and direct outgoing access on port 80 for the unit tests to succeed. The whole checking process can be started with the following command:
If no error occurs, you are ready to use HoneyC. However, if the unit test finds errors, please consult the Readme file for workarounds for common problems, or ask your question in the help forum.
Each of the three components has excellent built-in help, which you can access via the parameter --help in the files queuer/YahooSearch.rb, visitor/ WebBrowser, and analysisEngine/SnortRulesAnalysis Engine. rb, respectively. For example, the built-in help explains in detail the format of the analysis engine configuration, which we will later illustrate with a running example:
Code View: $ ruby analysisEngine/SnortRulesAnalysisEngine.rb --help
Usage: ruby -s analysisEngine/SnortRulesAnalysisEngine.rb
-c=[location of snort rules analysis engine configuration file]
Analyze http responses against snort rules and output a report.
Snort Rules Analysis Engine Configuration File Format
-----------------------------------------------------
<snortRulesAnalysisEngineConfiguration
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation=
"SnortRulesAnalysisEngineConfiguration_v1_0.xsd">
<rulesLocation>analysisEngine/example.rules</rulesLocation>
</snortRulesAnalysisEngineConfiguration>
The snort configuration file simply specifies the relative or absolute
location of the rules file.
Snort Rules File Format
-----------------------
alert tcp any any <> any any (msg: "rule1"; reference:url,http://rule1.com;
sid:1000001; rev:1; classtype:trojan-activity; pcre:"/rule1pcre/"; )
alert tcp any any <> any any (msg: "google"; reference:url,http://rule2.com;
sid:1000002; rev:2; classtype:attempted-dos; pcre:"/google/"; )
alert tcp any any <> any any (msg: "rule3"; reference:url,http://rule3.com;
sid:1000003; rev:1; classtype:trojan-activity; pcre:"/rule3pcre/"; )
The Snort rules file format adheres to the official Snort rules format
(see Snort manual on http//www.snort.org). Some restrictions apply within
the conext of HoneyC.
In addition to the official Snort rules format, HoneyC supports the
additional tag headercontent. It can be used to match on specific http
response header content. Matching can restrict the key value pair by
creating a match string in the following format: headercontent:"name="key">value<. In conjunction with this new tag a new pcre option H has been
implemented to support pcres on header content.
Report bugs to <http://sourceforge.net/tracker/?group_id=172208&atid=860868>
|
Now we take a look at the actual configuration process based on a longer example. Imagine that you are interested in learning more about Webattacker, a toolkit that allows an attacker to easily build a malicious website with diverse exploits for Internet Explorer. Moreover, Webattacker includes scripts that detect the Internet Explorer version of the attacked machine and spam-sending techniques to lure victims to the malicious websites. The toolkit has support for many vulnerabilities, including the following:
Microsoft Security Bulletin MS03-011
Microsoft Security Bulletin MS04-013
Microsoft Security Bulletin MS05-002
Microsoft Security Bulletin MS05-054
Microsoft Security Advisory (917077)
Mozilla Foundation Security Advisory 2005-50
Microsoft Security Bulletin MS06-006
As you can see, quite a few vulnerabilities from Internet Explorer can be exploited via this toolkit. The complete kit was also sold by an attacker for a small fee. Sophos reports that it costs about $15 on the black market. Usually the attacker installs some kind of Trojan Horse on the infected machine and thus gains complete control over the machine.
One way to learn more about this tool is to search for characteristic signatures of this exploit. One characteristic signature for Webattacker is the URL of the exploit itself, which is served as a CGI script. It usually contains the strings "ie" and ".cgi" with a number. This is a piece of information that we can use to detect Webattacker attacks. If we are also interested in attacks that use the tool r57shell, a PHP-based backdoor used in attacks against web applications, we simply use that string to detect suspicious sites.
Based on the information we want to collect, we can start to configure HoneyC. The main configuration file is in XML format, and we base our running example on the file HoneyCConfigurationExample.xml, which is included in the 1.2.0 release of HoneyC. This file specifies where the tool can find the configuration files for the three components:
Code View: <honeyCConfiguration xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="HoneyCConfiguration_v1_0.xsd">
<queuer>ruby -s queuer/YahooSearch.rb -c=queuer/YahooSearchConfiguration
Example.xml</queuer>
<visitor>ruby -s visitor/WebBrowser.rb -c=visitor/WebBrowserConfiguration
Example.xml</visitor>
<analysisEngine>ruby -s analysisEngine/SnortRulesAnalysisEngine.rb
-c=analysisEngine/SnortRulesAnalysisEngineConfigurationExample.xml
</analysisEngine>
</honeyCConfiguration>
|
For each component, we have to specify the path and possible arguments. These additional configuration files are then used to actually configure the behavior of HoneyC. For now, we simply use the defaults and change only the configuration of the different components.
The format of the queuer configuration file is simple. We specify the string we want to search for and the maximum number of results we want. This information is entered in the file queuer/YahooSearchConfigurationExample.xml and could look like the following example:
<yahooSearchConfiguration xmlns:xsi="http://www.w3.org/2001/
XMLSchema-instance"
xsi:noNamespaceSchemaLocation="YahooSearchConfiguration_v1_0.xsd"
applicationID="_HoneyC_">
<query results="100" format="html">ie0604.cgi</query>
</yahooSearchConfiguration> |
Based on this configuration, the queuer searches via the Yahoo Search API for suspicious websites that are returned when searching for the string "ie0604.cgi," a typical sign of Webattacker or other attacks. In the second steps, these suspicious sites are visited with the help of the visitor component, which can be configured via the file visitor/WebBrowser.rb. Again, we enter the details in XML format and specify the user agent, whether links should be followed, and how many threads the visitor component can use:
<webBrowserConfiguration xmlns:xsi="http://www.w3.org/2001/
XMLSchema-instance"
xsi:noNamespaceSchemaLocation="WebBrowserConfiguration_v1_0.xsd">
<userAgent>Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)
</userAgent>
<followALink>false</followALink>
<browserThreads>30</browserThreads>
</webBrowserConfiguration> |
In the running example, we configure the visitor component to behave like an Internet Explorer 6 instance running on Windows XP. HoneyC uses this configuration to investigate all queued URLs and then passes the results to the analysis engine. The configuration of this component specifies the path of the rules:
<snortRulesAnalysisEngineConfiguration xmlns:xsi="http://www.w3.org/2001/
XMLSchema-instance"
xsi:noNamespaceSchemaLocation="SnortRulesAnalysisEngineConfiguration_v1_0.
xsd">
<rulesLocation>analysisEngine/example.rules</rulesLocation>
</snortRulesAnalysisEngineConfiguration> |
The specified file contains the rules that should be checked for each URL found. In our running example, we use different rules to detect the PHP backdoor r57shell and two signs for Webattacker files. Moreover, we search for a common DDoS tool that contains the name r3v3ng4ns:
Code View: alert tcp any any <> any any (msg: "suspicious string 'PHP shell' found"; sid:1000001; rev:1; classtype:trojan-activity; pcre:"/r57shell/"; ) alert tcp any any <> any any (msg: "possible 'Web-Attacker' found"; sid:1000002; rev:1; classtype:trojan-activity; pcre:"/Web-Attacker Control panel/"; ) alert tcp any any <> any any (msg: "possible 'Web-Attacker' found"; sid:1000003; rev:1; classtype:trojan-activity; pcre:"/Err: this user is already attacked!/"; ) alert tcp any any <> any any (msg: "suspicious defacing tool found"; sid:1000002; rev:1; classtype:trojan-activity; pcre:"/r3v3ng4ns/"; ) |
These rules are all standard regular expressions. Since all components are now configured, we can start the actual HoneyC process via the following command:
Code View: $ ruby -s HoneyC.rb -c=HoneyCConfigurationExample.xml
01/19-04:10:15.000000 [**] [1:1000001:1] possible Web-Attacker found [**]
[Classification: A Network Trojan was detected] [Priority: 1] {TCP}
localhost -> http//img.secondsite2.com/cgi-bin/ie0604.cgi
[...]
Snort Rules Analysis Engine Statistics:
Analyzed 315 responses in 100.365605
Matches found 4
Average Analysis Time: 0.000812250793650794
HttpResponse Statistics:
All Count: 315
Average Size (200-OK): 3680
Error Code Count: [-403 - Forbidden 1--200 - OK 292--404 - Not Found 19--
408 - Timeout Error 2--501 - getaddrinfo: Name or service not known 1-]
Content Type Count: [-application/x-javascript; charset=utf8 2--text/plain 1
--image/png 17--text/html; charset=utf-8 3--application/x-javascript;
charset=utf-8 5
--application/x-javascript 22--image/jpeg 18--text/html; charset=iso-
8859-1 3 --image/gif 182-]
Content Type Length Averages: [-application/x-javascript; charset=utf8 278
--text/plain 9415--image/png 13666--text/html; charset=utf-8 4547
--application/x-javascript; charset=utf-8 4987--application/x-javascript
10684
--image/jpeg 17711--text/html; charset=iso-8859-1 287--image/gif 1313-]
|
The tool now runs and searches for websites that match the specified criteria. If your rules and search times have been carefully chosen, the chances are high that you will find an interesting page. In this example, HoneyC successfully identifies one page as infected, and a manual analysis can provide you with even more information about this kind of attack.
Due to the lack of real malware signatures, the current version of HoneyC is a bit limited. It can be usefull to find other instances of well-known attacks, but for detecting more stealthy attacks, it lacks signatures and more flexible components. Nevertheless, it could become a useful tool in the area of low-interaction client-side honeypots.