We can also use the concept of high-interaction honeypots to learn more about attacks against client programs. As you remember, a high-interaction honeypot gives the adversary the ability to interact with a real system and not with a simulation. In contrast to low-interaction honeypots, the risk involved is higher, but we can also learn more about the actual attack. The interesting aspect about high-interaction honeypots is that they can also be used to detect zero-day exploits. A zero-day exploit is an exploit for a vulnerability that is unknown at that point — that is, a new and unreleased vulnerability. Consequently, there is usually no patch available for a zero-day vulnerability. This kind of attack is a severe threat, since this new attack vector cannot be mitigated efficiently. However, since the state of the system is monitored to make an attack assessment, high-interaction client honeypots are usually rather slow. Further, this detection mechanism is prone to detection evasion. For example, an attack could delay the exploit from immediately triggering (time bombs), or an attack could trigger upon user action (e.g., once the mouse hovers over an image). Since no immediate state change occurred, the client honeypot is likely to incorrectly classify the server as safe, although it actually did perform an attack on the client. Finally, high-interaction client honeypots are expensive because an entire system is needed to operate them.
Similar to low-interaction client honeypots, we also have to give up some restrictions posed by "classical" high-interaction honeypots. The high-interaction honeypots we introduced in Chapter 2 are designed to supply more information about the tools, tactics, and motives of attacks against server and system software. The basic idea is to deploy an information system resource (e.g., a normal computer or a router) and add some additional logging capabilities. This system has no conventional task in the network, and therefore all traffic coming from and going to it is, by definition, suspicious. The honeypot is then connected to the Internet, and by observing the network traffic and additional logfiles, we can learn more about the activities of an adversary. This completely passive approach is not viable for attacks against client applications. The attacker cannot interact with the web browser installed on the honeypot, since the web browser does not initiate a connection. Thus, we need to give up the passive approach of "classical" honeypots if we want to design a high-interaction client honeypot. In the following sections, we introduce the general setup of such a solution. In addition, we present several implementations of this approach and show how you can use them on your own. Finally, we highlight preliminary results obtained with the help of high-interaction client honeypots.
As just noted, we give up the passive approach when we design high-interaction honeypots. Instead of just idling and waiting for an adversary to attack our system, we are going to actively search for malicious content in the Internet. The general approach is similar to low-interaction client honeypots: We must presort which parts of the Internet we want to examine and then access these sites. But in contrast to the low-interaction methodology, we are not pattern-based nor do we rely on the output of antivirus engines. Instead, we telecommand a real client application and access suspicious parts of the Internet with it. Simultaneously, we closely monitor the honeyclient and detect changes of the system. This indicates that something malicious could have happened. If we just browse the web, no additional process should be created and no binary should be downloaded to the machine without the consent of the user. However, we have to be careful to avoid false positives. For example, a website could create a cookie on our system to store some information related to our visit. Thus, there are cases in which the website creates files upon visits and we have to use some kind of whitelist to exclude false positives.
As noted, this new methodology can be roughly divided into two parts: (1) searching for websites that have malicious content with a probability that is higher than the average and (2) accessing the website and doing an integrity check of the whole system to determine whether our system has been compromised. The first phase is the same as for low-interaction client honeypots. We can simply use a query mechanism as just introduced and use the returned URLs to feed the second phase.
The second phase is different. Here, we use a real system. Following the high interaction approach, we use a client application and telecommand it to access the URLs we have determined in the first phase. Since we focus on web-based threats for now, we need an additional tool that automatically navigates Microsoft's Internet Explorer or another web browser to certain websites. Such a tool can be implemented with the help of OLE automation, and we introduce a high-interaction honeypot tool in the following sections. You can use this tool to start building your own honeypot or as a basic building block for another project.
With the help of such an additional tool, we can now automatically access the URLs from the first phase and autonomously navigate through suspicious web pages. Eventually, we will hit a web page that is malicious and tries to exploit a vulnerability in our browser. For example, we could find a website that embeds a malicious WMF file that triggers the vulnerability described in Microsoft's security bulletin MS06-001. If the exploit is successful, it will presumably download a bot or another kind of malware to the honeypot. And this is something we can easily detect. Suddenly a new binary is downloaded and executed at the honeypot. Therefore, the honeyclient has to perform an integrity check of the whole system when it accesses a website. This has to be done during and after interacting with a specific website to determine if the system has been compromised. Only with the help of such a check, can we identify whether we indeed found a malicious website that tried to exploit a vulnerability in our web browser. This is again the principle of honeypots: We heavily monitor our system (presumably with special software that helps us in postincident computer and network forensics) and try to detect whether we have been attacked. But instead of waiting for an attack, we actively search for a malicious website.
For the integrity check, we need to monitor several things. The following enumeration is presumably not complete, but it should give a first insight into whether a system has been compromised:
Monitoring of filesystem activity: Are there new files, or were some files deleted? Are there some files that were modified since the last check? We can base our check on SHA-512, MD5 and other cryptographic checksums.
Monitoring of registry entries: Are there new registry or deleted registry keys? Can we detect modifications of registry keys?
Monitoring of processes: Can we detect changes in the listing of running processes? Are there new ones or stopped some processes? Can we do the same on the level of threads?
Monitoring of network connections: Have there been modifications in the number and endpoints of network connections? If there are new connections, are they suspicious?
Monitoring of memory: Can we detect suspicious changes in memory? This is the ultimate integrity check, since malware could also stay only in memory. Presumably, however, such a tracking is hard to implement.
These integrity checks should help us to get an overview of whether a web page has changed something on our system. This can give us hints about whether the web page is malicious and if we should examine it further. The check can be done periodically — that is, each time we have successfully accessed a web page. This has the drawback that it is slow and a bit unreliable. Before accessing the next page, we would have to wait until the integrity check is finished, and this can take some time (in the order of minutes). In addition, such a check is unreliable, since the installed malware could also install a rootkit that subsequently hides other malware instances and thus makes it hard to detect changes. Therefore, the integrity check is preferably done in real-time. This can, for example, be achieved with API hooking — that is, the interception of API calls that can then be used to change the execution flow. This is a technique borrowed from the attacker community, who normally uses this feature within rootkits. Again, this is an example of the dual use principle of IT security: We can use the techniques of attackers and vice versa.
A problem is the delay between initial infection and complete compromise. Imagine that a web page successfully exploits a vulnerability on our honeypot. It then starts a download process to install some additional malware on our system. The download process will take some time, and in the meantime, we have already accessed another web page. To correctly flag the correct page, we therefore have to carefully check which page actually triggered and started the compromise. We need to keep a list of recent web pages the honeyclient has accessed (several minutes of backlog have been proven to be enough) and need to verify them separately.
Another pitfall is dialog boxes. If such a dialog pops up, a normal user usually has the choice between two options: OK or Cancel. According to the selection, the web page might react differently. Therefore, we also have to simulate the user interaction on dialog boxes. Preferably we visit such a website as often as we have different choices — twice in the previous example. This way, we can detect whether a web page behaves differently according to user clicking.
Bigger obstacles are HTML forms that the user is supposed to fill out or dialog boxes in which additional user input is required ("Please type OK and click on 'Accept' to proceed"). We can try to defeat these with heuristics obtained from the areas of machine learning and pattern recognition, but it is not possible to derive a generic, automated solution to this problem. Hence, we will not have a complete coverage without human interaction, but we can try to automate things as much as possible.
Note that all these tests should be performed for a combination of multiple versions of Microsoft Windows and Internet Explorer, since this operating system and this web browser are currently the privileged target of attackers. The attacker can test which web browser accesses the malicious web page and respond differently, so different setups can also yield different results. For example, the following JavaScript code is used by some malicious web pages to detect the version of Java Virtual Machine and Internet Explorer. Based on the value of the variables, a different exploit is served to the victim later on.
function GetVersion(CLSID) {
if (oClientCaps.isComponentInstalled(CLSID,"Component ID")) {
return oClientCaps.getComponentVersion(CLSID,"ComponentID ").split(",");
}
else {
return Array(0,0,0,0);
}
}
var JVM_vers = GetVersion("{08B0E5C0-4FCB-11CF-AAA5-00401C608500}");
var IE_vers = GetVersion("{89820200-ECBD-11CF-8B85-00AA005B4383}"); |
However, the general design outlined in the preceding code can also be used to implement the concept of high-interaction client honeypots on other operating systems and with other flavors of browsers.
In a schematic overview, this concept is depicted in Figure 8.5. Clienthp.dll takes care of all the actions just outlined: navigating the web browser, integrity check of the system, handling of dialog boxes, and more. Via a configuration frontend, the user can adjust various parameters, like the keywords used to search for web pages with search engines, the depth and breadth of crawling, or the number of URLs after which the honeyclient stops its execution.
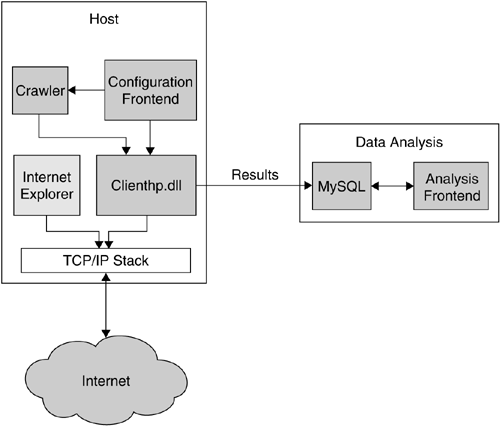
All logfiles are stored in a remote database to enable centralized logging. Honeyclients operating in different networks can report their findings to a central sites that can also correlate the data. The analysis frontend enables all data analysis tasks and helps the operator to keep track of information collected.
Just a side note: You can run the honeyclient in a virtual environment like VMware. After a compromise, this facilitates a quick way to reset the complete system and start from scratch. Again, the idea of virtualization and virtual honeypots makes our live easier. The only problem with this approach are the malware binaries that detect the presence of this virtual machine. We take a closer look at how this can be done in Chapter 9.
Kathy Wang was the first to publish an actual program that implements the idea of high-interaction client honeypots. She published a tool called honeyclient, which is available at http://honeyclient.org. The actual project moved to http://www.honeyclient.org/trac/ and is now the MITRE HoneyClient.
Basically it works with the same principles we have just outlined. The HoneyClient architecture is a Perl-based client/server architecture. The HoneyClient is a virtual machine, designed to instrument (or drive) a locally running, target application to one or more remote resources. This is typically Internet Explorer, but other programs can also be instrumented this way. The purpose of this operation is to verify whether the fetched content from each remote resource is malicious in nature, such that the honeyclient becomes compromised as a result of target application processing any of the content.
Honeyclient is state-based and detects attacks on clients by monitoring that all files and directories in the Windows OS file system are checked — except for files and directories in certain whitelists. Moreover, certain registry hives in the Windows OS (e.g., HKEY CURRENT USER and HKEY LOCAL MACHINE) are checked, and, again, a whitelist excludes certain keys. These integrity checks are used to detect an infection via a malicious web page.
In this architecture, normal honeyclients consist of the following components:
VMware virtual machine as base system
Running a variant of the Microsoft Windows operating system, since this is the common target of attacks
Configured to automatically login as system administrator upon boot such that a malicious website can compromise the whole system
Upon login, automatically execute the HoneyClient agent daemon inside a Cygwin environment, which takes care of the actual visiting of websites
More information about HoneyClient can be found at the project's website. You can also download a version of HoneyClient at that website and find detailed installation instructions at http://www.honeyclient.org/trac/wiki/UserGuide.
There is also a variation of Wang's HoneyClient available. Aidan Lynch and Daragh Murray from Dublin City University have modified the original honeyclient implementation so it can deal with e-mail messages, thus forming a e-mail honeyclient. The implementation opens e-mails within Outlook and does an integrity check afterward to see whether the e-mail has compromised the system. Moreover, it replies to each mail with the message Please unsubscribe me! to test whether this attracts even more spam. Moreover, the tool can grab URLs from e-mail messages and send them back to the honeyclient. This is an automated way to extract new URLs from spam messages. Our experience shows that these URLs have a higher probability of being malicious, so the success rate should be higher now. In addition, this extension also keeps track of newly spawned processes during the integrity check. This improves the ability to detect a system compromise for the honeyclient. You can get this extension at http://www.synacklabs.net/honeyclient/email-honeyclient.zip.
Since some Microsoft Outlook security patches and Windows Service Packs have restricted the automation of certain OLE application features, it is necessary to install an additional tool to execute the e-mail honeyclient. With the help of Outlook Redemption (available at http://www.dimastr.com/redemption/) it is still possible to navigate Outlook. The tool is free for noncommercial use and can be downloaded from the given website. After the download has finished, extract the ZIP file and execute Install.exe to install Redemption.dll. Moreover, you need to configure your installation of Outlook to be able to send and receive e-mails from a given account.
Afterward, you can install and use the e-mail honeyclient itself. Extract the given ZIP file and change with your shell to this directory. Then execute the command perl mailScript.pl, and your honeyclient will start working. The output looks like the following listing:
Searching files... Searching Registry... Initializing... 42 number of messages 1 start just before integrity check just after integrity check 2 start just before integrity check just after integrity check 3 start just before integrity check Integrity file has changed, or you didn't delete a changefile from a previous run. See changes.txt for a list of what integrity checks failed. Please contact me asap just after integrity check 4 start [...] |
At the beginning of the run, the honeyclient does the normal initialization and prints out the number of messages to be processed. For each message, it opens the message, waits five seconds (to give a malicious message some time to infect the machine), extracts the URLs, replies to the e-mail, and then starts the integrity check. If the honeyclient does not detect a compromise, the e-mail message is moved to the folder Processed and the next message is examined. However, if the integrity check detects changes on the system, the subject of the e-mail is printed out, and it is moved to the folder Suspect.
A file called urls.txt is created in the current directory that contains all URLs extracted from the e-mail messages. This file can be used as input for the web-based honeyclient. All logfiles created by the web-based honeyclient (as just described) are also created and have the same meaning. In addition, there are two files called processList.txt and suspectProcessList.txt that contain a clean process listing and the names of suspect processes, respectively.
Another tool in the area of high-interaction client-side honeypots is Capture-HPC. The basic idea of this tool is to identify malicious servers by communicating with suspicious servers using dedicated virtual machines and observing their system state changes. Such a change can be any of the changes just outlined, most commonly a new process or additional network activity. If a system state change is detected, this is a clear sign that Capture-HPC interacted with a malicious server, so the processed URL is flagged as virulent. The website of the project is at http://capture-hpc.sourceforge.net/, where you can find more information about the project.
A schematic overview of Capture-HPC is given in Figure 8.6. The system is based on a client/server architecture: One Capture-HPC server can control many Capture-HPC clients, which can be executed on either the local host or even a remote location. Thus, the complete project is scalable, and more machines can be added on demand. Server and clients communicate via a simple network connection on Capture-HPC server port 7070. The server can start and stop clients and send them information about the next to be crawled URL. On the other hand, the clients send via this connection status information and classification based on their interaction with malicious servers on the Web.
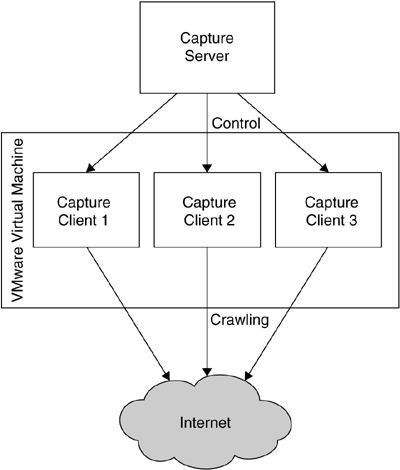
The clients have the ability to monitor changes to the filesystem and process list of the system. This allows an easy way to detect a compromise of the system. When a new process is created, it could be caused by a spyware infection. Since some events occur during normal operation (e.g., writing certain files to the web browser cache), exclusion lists make it possible to ignore certain type of events. The clients can automatically control Internet Explorer to visit a website. This enables an automated crawling with high-interaction honeypots. Once a malicious website has been identified, Capture-HPC is able to reset the virtual machine of the specific client to a clean state. Afterward, this virtual machine can be used again to search for additional malicious websites. All information about such an incident is sent to the Capture-HPC server, which can — via these centralized logs — keep track of which links have not been visited yet. Moreover, the central server collects information about server classifications and states changes incurred by visiting malicious servers.
Capture-HPC is free software released under the terms of the GNU General Public License (GPL). So you can download the tool from its web page and install it on your machine. Detailed installation instructions are available at http://capture-hpc.sourceforge.net/index.php?n=Main.Installation. The setup procedure is a bit more complex, but the installation instructions are very helpful. We won't describe the installation process here because Capture-HPC is currently in an early release state (version 0.1 is available at the time of this writing), and thus the installation will presumably change during the next releases.
Another project in this area is the Strider HoneyMonkey Exploit Detection project by Microsoft (http://research.microsoft.com/HoneyMonkey/). It is a research project that tries to detect and analyze websites that exploit vulnerabilities in Microsoft's Internet Explorer. As we have seen in the introduction of this chapter, this is currently the majority of vulnerable client applications. The system is named HoneyMonkey after the usage of monkey programs, which are defined as "an automation-enabled program such as the Internet Explorer browser allows programmatic access to most of the operations that can be invoked by a user. A 'monkey program' is a program that drives the browser in a way that mimics a human user's operation" [107].
The system consists of three different basic blocks that form a three-stage pipeline of virtual machines. As mentioned previously, the usage of virtual machines has the advantage of enabling an easy way to revert a compromised system. In addition, several virtual machines can be executed concurrently to enhance the performance and throughput of the whole system. The three different stages differ in their sophistication and complexity:
Stage 1 uses scalable HoneyMonkey exploit detection with unpatched virtual machines without redirection analysis. This is the simplest case in which only one page is examined at a time. The web browser in the monkey program does not open other links, so no redirection takes place. But this is still useful to detect simple attack pages that exploit known vulnerabilities.
Stage 3 also uses the redirection analysis and additionally uses (nearly) fully patched virtual machine to detect the latest threats. Imagine that a fully patched virtual machine is exploited during the analysis process. This means that the research has found a new vulnerability in an existing program — in this case, a zero-day exploit!
For this project, several machines are deployed within a network. Each machine is different from the others in regard to the patch level so each machine represents one specific configuration. Each website is accessed by all of these machines to detect whether only certain configurations are vulnerable. Again, an integrity check of each system is necessary. This project was the first who announced that it found an actual unknown vulnerability in the wild with the help of client honeypots. So it has proven that this approach is viable and that honeypots are a valuable tool to learn about attacks in communication networks.
More background information is available in a research paper by Wang et al. entitled "Automated Web Patrol with Strider HoneyMonkeys: Finding Web Sites That Exploit Browser Vulnerabilities" [107]. Unfortunately, the whole project is closed source, and thus it is not possible to install it on your machine. However, with honeyclient and Capture-HPC, you can collect alike results as with HoneyMonkey.