9.7. MySQL Cluster ReplicationPrior to MySQL 5.1.6, asynchronous replication, more usually referred to simply as "replication," was not available when using MySQL Cluster. MySQL 5.1.6 introduces master-slave replication of this type for MySQL Cluster databases. This section explains how to set up and manage a configuration wherein one group of computers operating as a MySQL Cluster replicates to a second computer or group of computers. We assume some familiarity on the part of the reader with standard MySQL replication as discussed elsewhere in this manual. (See Chapter 5, "Replication.") Normal (non-clustered) replication involves a "master" server and a "slave" server, the master being the source of the operations and data to be replicated and the slave being the recipient of these. In MySQL Cluster, replication is conceptually very similar but can be more complex in practice, because it may be extended to cover a number of different configurations including replicating between two complete clusters. Although a MySQL Cluster itself depends on the NDB Cluster storage engine for clustering functionality, it is not necessary to use the Cluster storage engine on the slave. However, for maximum availability, it is possible to replicate from one MySQL Cluster to another, and it is this type of configuration that we discuss, as shown in Figure 9.5. Figure 9.5. MySQL Cluster-to-Cluster replication layout.
In this scenario, the replication process is one in which successive states of a master cluster are logged and saved to a slave cluster. This process is accomplished by a special thread known as the NDB binlog injector thread, which runs on each MySQL server and produces a binary log (binlog). This thread ensures that all changes in the cluster producing the binary logand not just those changes that are effected via the MySQL Serverare inserted into the binary log with the correct serialization order. We refer to the MySQL replication master and replication slave servers as "replication servers" or "replication nodes," and the data flow or line of communication between them as a "replication channel." 9.7.1. Abbreviations and SymbolsThroughout this section, we use the following abbreviations or symbols for referring to the master and slave clusters, and to processes and commands run on the clusters or cluster nodes:
9.7.2. Assumptions and General RequirementsA replication channel requires two MySQL servers acting as replication servers (one each for the master and slave). For example, this means that in the case of a replication setup with two replication channels (to provide an extra channel for redundancy), there will be a total of four replication nodes, two per cluster. Each MySQL server used for replication in either cluster must be uniquely identified among all the MySQL replication servers participating in either cluster (you cannot have replication servers on both the master and slave clusters sharing the same ID). This can be done by starting each SQL node using the --server-id=id option, where id is a unique integer. Although it is not strictly necessary, we will assume for purposes of this discussion that all MySQL installations are the same version. In any event, servers involved in replication must be compatible with one another with respect to both the version of the replication protocol used and the SQL feature sets they support; the simplest and easiest way to assure that this is the case is to use the same MySQL version for all servers involved. Note that in many cases it is not possible to replicate to a slave running a version of MySQL with a lower version number than that of the mastersee Section 5.6, "Replication Compatibility Between MySQL Versions," for details. We assume that the slave server or cluster is dedicated to replication of the master, and that no other data is being stored on it. 9.7.3. Known IssuesThe following are known problems or issues when using replication with MySQL Cluster in MySQL 5.1:
See Section 9.7.9.2, "Initiating Discovery of Schema Changes," for more information about the first two items listed above, as well as some examples illustrating how to handle applicable situations. 9.7.4. Replication Schema and TablesReplication in MySQL Cluster makes use of a number of dedicated tables in a separate cluster_replication database on each MySQL Server instance acting as an SQL node in both the cluster being replicated and the replication slave (whether the slave is a single server or a cluster). This database, which is created during the MySQL installation process by the mysql_install_db script, contains a table for storing the binary log's indexing data. Because the binlog_index table is local to each MySQL server and does not participate in clustering, it uses the MyISAM storage engine, and so must be created separately on each mysqld participating in the master cluster. This table is defined as follows:
CREATE TABLE `binlog_index` (
`Position` BIGINT(20) UNSIGNED NOT NULL,
`File` VARCHAR(255) NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
`inserts` BIGINT(20) UNSIGNED NOT NULL,
`updates` BIGINT(20) UNSIGNED NOT NULL,
`deletes` BIGINT(20) UNSIGNED NOT NULL,
`schemaops` BIGNINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (`epoch`)
) ENGINE=MYISAM DEFAULT CHARSET=latin1;
Figure 9.6 shows the relationship of the MySQL Cluster replication master server, its binlog injector thread, and the cluster_replication.binlog_index table. Figure 9.6. The replication master cluster, the binlog-injector thread, and the binlog_index table.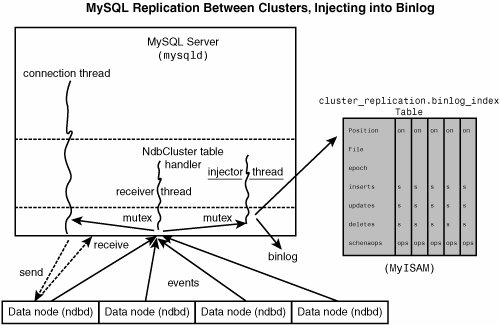
An additional table, named apply_status, is used to keep a record of the operations that have been replicated from the master to the slave. Unlike the case with binlog_index, the data in this table is not specific to any one SQL node in the (slave) cluster, and so apply_status can use the NDB Cluster storage engine, as shown here: CREATE TABLE `apply_status` (
`server_id` INT(10) UNSIGNED NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY USING HASH (`server_id`)
) ENGINE=NDBCLUSTER DEFAULT CHARSET=latin1;
The binlog_index and apply_status tables are created in a separate database because they should not be replicated. No user intervention is normally required to create or maintain either of them. Both the binlog_index and the apply_status tables are maintained by the NDB injector thread. This keeps the master mysqld process updated to changes performed by the NDB storage engine. The NDB binlog injector thread receives events directly from the NDB storage engine. The NDB injector is responsible for capturing all the data events within the cluster, and ensures that all events changing, inserting, or deleting data are recorded in the binlog_index table. The slave I/O thread will transfer the from the master's binary log to the slave's relay log. However, it is advisable to check for the existence and integrity of these tables as an initial step in preparing a MySQL Cluster for replication. It is possible to view event data recorded in the binary log by querying the cluster_replication.binlog_index table directly on the master. This can be also be accomplished using the SHOW BINLOG EVENTS statement on either the replication master or slave MySQL servers. 9.7.5. Preparing the Cluster for ReplicationPreparing the MySQL Cluster for replication consists of the following steps:
9.7.6. Starting Replication (Single Replication Channel)This section outlines the procedure for starting MySQL CLuster replication using a single replication channel.
It is also possible to use two replication channels, in a manner similar to the procedure described in the next section; the differences between this and using a single replication channel are covered in Section 9.7.7, "Using Two Replication Channels." 9.7.7. Using Two Replication ChannelsIn a more complete example scenario, we envision two replication channels to provide redundancy and thereby guard against possible failure of a single replication channel. This requires a total of four replication servers, two masters for the master cluster and two slave servers for the slave cluster. For purposes of the discussion that follows, we assume that unique identifiers are assigned as shown here:
Setting up replication with two channels is not radically different from setting up a single replication channel. First, the mysqld processes for the primary and secondary replication masters must be started, followed by those for the primary and secondary slaves. Then the replication processes may be initiated by issuing the START SLAVE statement on each of the slaves. The commands and the order in which they need to be issued are shown here:
As mentioned previously, it is not necessary to enable binary logging on replication slaves. 9.7.8. Implementing Failover with MySQL ClusterIn the event that the primary Cluster replication process fails, it is possible to switch over to the secondary replication channel. The following procedure describes the steps required to accomplish this:
Once the secondary replication channel is active, you can investigate the failure of the primary and effect repairs. The precise actions required to do this will depend upon the reasons for which the primary channel failed. If the failure is limited to a single server, it should (in theory) be possible to replicate from M to S', or from M' to S; however, this has not yet been tested. 9.7.9. MySQL Cluster Backups with ReplicationThis discussion discusses making backups and restoring from them using MySQL Cluster replication. We assume that the replication servers have already been configured as covered previously (see Section 9.7.5, "Preparing the Cluster for Replication," and the sections immediately following). This having been done, the procedure for making a backup and then restoring from it is as follows:
To perform a backup and restore on a second replication channel, it is necessary only to repeat these steps, substituting the hostnames and IDs of the secondary master and slave for those of the primary master and slave replication servers where appropriate, and running the preceding statements on them. For additional information on performing Cluster backups and restoring Cluster from backups, see Section 9.6.5, "Online Backup of MySQL Cluster." 9.7.9.1. Automating Synchronization of the Slave to the Master BinlogIt is possible to automate much of the process described in the previous section (see Section 9.7.9, "MySQL Cluster Backups with Replication"). The following Perl script reset-slave.pl serves as an example of how you can do this. #!/user/bin/perl -w
# file: reset-slave.pl
# Copyright ©2005 MySQL AB
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to:
# Free Software Foundation, Inc.
# 59 Temple Place, Suite 330
# Boston, MA 02111-1307 USA
#
# Version 1.1
######################## Includes ###############################
use DBI;
######################## Globals ################################
my $m_host='';
my $m_port='';
my $m_user='';
my $m_pass='';
my $s_host='';
my $s_port='';
my $s_user='';
my $s_pass='';
my $dbhM='';
my $dbhS='';
####################### Sub Prototypes ##########################
sub CollectCommandPromptInfo;
sub ConnectToDatabases;
sub DisconnectFromDatabases;
sub GetSlaveEpoch;
sub GetMasterInfo;
sub UpdateSlave;
######################## Program Main ###########################
CollectCommandPromptInfo;
ConnectToDatabases;
GetSlaveEpoch;
GetMasterInfo;
UpdateSlave;
DisconnectFromDatabases;
################## Collect Command Prompt Info ##################
sub CollectCommandPromptInfo
{
### Check that user has supplied correct number of command line args
die "Usage:\n
reset-slave >master MySQL host< >master MySQL port< \n
>master user< >master pass< >slave MySQL host< \n
>slave MySQL port< >slave user< >slave pass< \n
All 8 arguments must be passed. Use BLANK for NULL passwords\n"
unless @ARGV == 8;
$m_host = $ARGV[0];
$m_port = $ARGV[1];
$m_user = $ARGV[2];
$m_pass = $ARGV[3];
$s_host = $ARGV[4];
$s_port = $ARGV[5];
$s_user = $ARGV[6];
$s_pass = $ARGV[7];
if ($m_pass eq "BLANK") { $m_pass = '';}
if ($s_pass eq "BLANK") { $s_pass = '';}
}
############### Make connections to both databases #############
sub ConnectToDatabases
{
### Connect to both master and slave cluster databases
### Connect to master
$dbhM
= DBI->connect(
"dbi:mysql:database=cluster_replication;host=$m_host;port=$m_port",
"$m_user", "$m_pass")
or die "Can't connect to Master Cluster MySQL process!
Error: $DBI::errstr\n";
### Connect to slave
$dbhS
= DBI->connect(
"dbi:mysql:database=cluster_replication;host=$s_host",
"$s_user", "$s_pass")
or die "Can't connect to Slave Cluster MySQL process!
Error: $DBI::errstr\n";
}
################ Disconnect from both databases ################
sub DisconnectFromDatabases
{
### Disconnect from master
$dbhM->disconnect
or warn "Disconnection failed: $DBI::errstr\n";
### Disconnect from slave
$dbhS->disconnect
or warn "Disconnection failed: $DBI::errstr\n";
}
###################### Find the last good GCI ###################
sub GetSlaveEpoch
{
$sth = $dbhS->prepare("SELECT MAX(epoch)
FROM cluster_replication.apply_status;")
or die "Error while preparing to select epoch from slave: ",
$dbhS->errstr;
$sth->execute
or die "Selecting epoch from slave error: ", $sth->errstr;
$sth->bind_col (1, \$epoch);
$sth->fetch;
print "\tSlave Epoch = $epoch\n";
$sth->finish;
}
####### Find the position of the last GCI in the binlog ########
sub GetMasterInfo
{
$sth = $dbhM->prepare("SELECT
SUBSTRING_INDEX(File, '/', -1), Position
FROM cluster_replication.binlog_index
WHERE epoch > $epoch
ORDER BY epoch ASC LIMIT 1;")
or die "Prepare to select from master error: ", $dbhM->errstr;
$sth->execute
or die "Selecting from master error: ", $sth->errstr;
$sth->bind_col (1, \$binlog);
$sth->bind_col (2, \$binpos);
$sth->fetch;
print "\tMaster bin log = $binlog\n";
print "\tMaster Bin Log position = $binpos\n";
$sth->finish;
}
########## Set the slave to process from that location #########
sub UpdateSlave
{
$sth = $dbhS->prepare("CHANGE MASTER TO
MASTER_LOG_FILE='$binlog',
MASTER_LOG_POS=$binpos;")
or die "Prepare to CHANGE MASTER error: ", $dbhS->errstr;
$sth->execute
or die "CHNAGE MASTER on slave error: ", $sth->errstr;
$sth->finish;
print "\tSlave has been updated. You may now start the slave.\n";
}
# end reset-slave.pl
9.7.9.2. Initiating Discovery of Schema ChangesThe NDB Cluster storage engine does not at present automatically detect structural changes in databases or tables. When a database or table is created or dropped, or when a table is altered using ALTER TABLE, the cluster must be made aware of the change. When a database is created or dropped, the appropriate CREATE SCHEMA or DROP SCHEMA statement should be issued on each storage node in the cluster to induce discovery of the change, that is: mysqlS*> CREATE SCHEMA db_name; mysqlS*> DROP SCHEMA db_name; Dropping TablesWhen dropping a table that uses the NDB Cluster storage engine, it is necessary to allow any unfinished transactions to be completed and then not to begin any new transactions before performing the DROP operation:
All of the MySQL slave servers can now "see" that the table has been dropped from the database. Creating TablesWhen creating a new table, you should perform the following steps:
Altering TablesWhen altering tables, you should perform the following steps in the order shown:
Note that when you create a new NDB Cluster table on the master cluster, if you do so using the mysqld that acts as the replication master, you must execute a SHOW TABLES, also on the master mysqld, to initiate discovery properly. Otherwise, the new table and any data it contains cannot be seen by the replication master mysqld, nor by the slave (that is, neither the new table nor its data is replicated). If the table is created on a mysqld that is not acting as the replication master, it does not matter which mysqld issues the SHOW TABLES. It is also possible to force discovery by issuing a "dummy" SELECT statement using the new or altered table in the statement's FROM clause. Although the statement fails, it causes the change to be recognized by the cluster. However, issuing a SHOW TABLES is the preferred method. We are working to implement automatic discovery of schema changes in a future MySQL Cluster release. For more information about this and other Cluster issues, see Section 9.9, "Known Limitations of MySQL Cluster." |