|
|
XML SchemasXML provides a flexible set of structures that can represent many different types of document- and data-oriented information. As part of XML 1.0, DTDs offered the basic mechanism for defining a vocabulary specifying the structure of XML documents in an attempt to establish a contract (how an XML document will be structured) between multiple parties working with the same type of XML. DTDs came into existence because people and applications wanted to be able to treat XML at a higher level than a collection of elements and attributes. Well-designed DTDs attach semantics (meaning) to the XML syntax in documents. At the same time, DTDs fail to address the common needs of namespace integration, modular vocabulary design, flexible content models, and tight integration with data-oriented applications. This failure comes as a direct result of XML's SGML origins and the predominantly document-centric nature of SGML applications. To address these issues, the XML community, under the leadership of the W3C, took up the task of creating a meta-language for describing both the structure of XML document and the mapping of XML syntax to data types. After long deliberation, the effort produced the final version of the XML Schema specification in March, 2001. In a nutshell, XML Schema can be described as powerful but complex. It is powerful because it allows for much more expressive and precise specification of the content of XML documents. It is complex for the same reason. The specification is broken into three parts:
Part 0 is meant for general consumption, whereas Parts 1 and 2 are deeply technical and require a skilled and determined reader. The rest of this section will attempt to provide an introduction to XML Schema that is very much biased towards schema usage in data-oriented applications. You should be able to gain sufficient understanding of structure and datatype specifications to comprehend and use common Web service schemas. Still, because XML Schema is fundamental to Web services, we highly recommend that you go through the primer document of the XML Schema specification. XML Schema BasicsListing 2.10 shows the basic structure of the SkatesTown purchase order schema. Listing 2.10 Basic XML Schema Structure
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns="http://www.skatestown.com/ns/po"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.skatestown.com/ns/po">
<xsd:annotation>
<xsd:documentation xml:lang="en">
Purchase order schema for SkatesTown.
</xsd:documentation>
</xsd:annotation>
...
</xsd:schema>
The most striking difference between schemas (that is how the book will informally refer to XML Schemas) and DTDs is that schemas are expressed in XML. This was done to eliminate the need for XML parsers to know another syntax (that of DTDs) and also to gain the power of expressive XML syntax. Of course, the XML Schema vocabulary is itself defined using schema as an ultimate proof of the power of the schema meta-language. The second very important feature of schema is that they are designed with namespaces in mind from the ground up. In this particular schema document, all elements belonging to the schema specification are prefixed with xsd:. The prefix's name is not important, but xsd: (which comes from XML Schema Definition) is the convention. The prefix is associated with the http://www.w3.org/2001/XMLSchema namespace that identifies the W3C Recommendation of the XML Schema specification. The default namespace of the document is set to be http://www.skatestown.com/ns/po, the namespace of the SkatesTown purchase order. The schema document needs both namespaces to distinguish between XML elements that belong to the schema specification versus XML elements that belong to purchase orders. Finally, the targetNamespace attribute of the schema element identifies the namespace of the documents that will conform to this schema. This is set to the purchase order schema namespace. The schema is enclosed by the xsd:schema element. The content of this element will be other schema elements that are used for element, attribute, and datatype definitions. The annotation and documentation elements can be used liberally to attach auxiliary information to the schema. Associating Schemas with DocumentsSchemas do not have to be associated with XML documents. For example, applications can be pre-configured to use a particular schema when processing documents. Alternatively, there is a powerful mechanism for associating schemas with documents. Listing 2.11 shows how to associate the previous schema with a purchase order document. Listing 2.11 Associating Schema with Documents
<?xml version="1.0" encoding="UTF-8"?>
<po:po xmlns:po="http://www.skatestown.com/ns/po"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.skatestown.com/ns/po
http://www.skatestown.com/schema/po.xsd"
id="43871" submitted="2001-10-05">
...
</po:po>
First, because the purchase order schema identified a target namespace, purchase order documents are required to use namespaces to identify their elements. The purchase order document uses the po prefix for this task. Next, the document uses another namespace—http://www.w3.org/2001/XMLSchema-instance—that has a special meaning. It defines a number of attributes that are part of the schema specification. These attributes can be applied to elements in instance documents to provide additional information to a schema-aware XML processor. By convention, most documents use the namespace prefix xsi: (for XML Schema: Instance). The binding between the purchase order document and its schema is established via the xsi:schemaLocation attribute. This attribute contains a pair of values. The first value is the namespace identifier whose schema's location is identified by the second value. Typically, the second value will be a URL, but specialized applications can use other types of values, such as an identifier in a schema repository or a well-known schema name. If the document used more than one namespace, the xsi:schemaLocation attribute would contain multiple pairs of values. Simple TypesOne of the biggest problems of DTDs is that they have no notion of datatypes, even for simple values such as the character data content of an element or an attribute value. Because of this, prior to the arrival of XML schema, XML applications included a large amount of validation code. For example, even a simple purchase order requires the following validation rules that are outside the scope of DTDs:
XML schemas address these issues in two ways. First, the specification comes with a large set of pre-defined basic datatypes such as string, positive integer, and date. These can be used directly. For custom data types, such as the values of the sku attribute, the specification defines a powerful mechanism for defining new types. Table 2.2 shows some of the commonly used pre-defined schema types with some examples of their use.
A note on ID/IDREF attributes: An XML processor is required to generate an error if a document contains two ID attributes with the same value or an IDREF with a value that has no matching ID value. This makes ID/IDREF attributes perfect for handling attributes such as the id/href ones in SkatesTown's purchase order address element. The process for creating new simple datatypes is straightforward. The new type must be derived from a base type: a pre-defined schema type or another already defined simple type. The base type is restricted along a number of facets to obtain the new type. The facets identify various characteristics of the types such as:
Of course, not all facets apply to all types. For example, the notion of fraction digits makes no sense for a date or a name. Tables 2.3 and 2.4 cross-link the pre-defined types and the facets that are applicable for them. The facets listed in Table 2.4 apply only to simple types that have an implicit order. The syntax for creating new types is simple. For example, the schema snippet in Listing 2.12 defines a simple type for purchase order SKUs. The name of the type is skuType. It is based on a string and it restricts it to have the pattern of three digits followed by dash followed by two uppercase letters. Listing 2.12 Using Patterns to Define String Format
<xsd:simpleType name="skuType">
<xsd:restriction base="xsd:string">
<xsd:pattern value="\d{ 3} -[A-Z]{ 2} "/>
</xsd:restriction>
</xsd:simpleType>
Listing 2.13 shows how to force purchase order ids to be greater than 10,000 but less than 100,000 and define an enumeration of all U.S. states. Listing 2.13 Using Ranges and Enumerations
<xsd:simpleType name="poIdType">
<xsd:restriction base="xsd:integer">
<xsd:minExclusive value="10000"/>
<xsd:maxExclusive value="100000"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="stateType">
<xsd:restriction base="xsd:string">
<xsd:enumeration value="AK"/>
<xsd:enumeration value="AL"/>
<xsd:enumeration value="AR"/>
...
</xsd:restriction>
</xsd:simpleType>
Complex typesIn XML Schema, simple types define the valid choices for character-based content such as attribute values and elements with character content. Complex types, on the other hand, define complex content models, such as those of elements that can have attributes and nested children. Complex type definitions do address both the sequencing and multiplicity of child elements as well as the names of associated attributes and whether they are required or optional. The main difference with respect to DTDs is that the schema syntax is much more expressive and the schema capabilities are much more powerful. The syntax for defining complex types is straightforward:
<xsd:complexType name="typeName">
<xsd:someTopLevelModelGroup>
<!-- Sequencing and multiplicity constraints for
child elements defined using xsd:element -->
</xsd:someTopLevelModelGroup>
<!-- Attribute declarations using xsd:attribute -->
</xsd:complexType>
The element xsd:complexType identifies the type definition. There are many different ways to specify the model group of the complex type. The most commonly used top-level model group elements you will see are:
These could be further nested to create more complex model groups. The xsd:group model group element is covered later in this chapter in the section "Content Model Groups." Inside the model group specification, child elements are defined using xsd:element. The model group specification is followed by any number of attribute definitions using xsd:attribute. For example, one possible way to define the content model of the purchase order address used in the billTo and shipTo elements is shown in Listing 2.14. The name of the complex type is addressType. Using xsd:sequence and xsd:element, it defines a sequence of the elements name, company, street, city, state, postalCode, and country. Listing 2.14 Schema Fragment for the Address Complex Type
<xsd:complexType name="addressType">
<xsd:sequence>
<xsd:element name="name" type="xsd:string" minOccurs="0"/>
<xsd:element name="company" type="xsd:string" minOccurs="0"/>
<xsd:element name="street" type="xsd:string"
maxOccurs="unbounded"/>
<xsd:element name="city" type="xsd:string"/>
<xsd:element name="state" type="xsd:string" minOccurs="0"/>
<xsd:element name="postalCode" type="xsd:string"
minOccurs="0"/>
<xsd:element name="country" type="xsd:string" minOccurs="0"/>
</xsd:sequence>
<xsd:attribute name="id" type="xsd:ID"/>
<xsd:attribute name="href" type="xsd:IDREF"/>
</xsd:complexType>
The multiplicities of these elements' occurrences are defined using the minOccurs and maxOccurs attributes of xsd:element. The value of zero for minOccurs renders an element's presence optional ("?" in the document structure diagrams). The default value for minOccurs is 1. The special value for maxOccurs of "unbounded" is used for the street element to indicate that there must be at least one present ("+" in the document structure diagrams). Every element is associated with a type using the type attribute xsd:element. In this example, all elements have simple character content of type string, identified by the xsd:string type. It might seem unusual to you that the namespace prefix is used inside an attribute value. It is true, the XML Namespaces specification does not explicitly address this use of namespace prefixes. However, the idea is simple. A schema can define any number of types. Some of them are built into the specification, and others are user-defined. The only way to know for sure which type is being referred to is to associate the type name with the namespace from which it is coming. What better way to do this than to prefix all references to the type with a namespace prefix? After the model group definition come the attribute definitions. In this example, xsd:attribute is used to define attributes id and href of types ID and IDREF, respectively. Both attributes are optional by default. Now, consider a slightly more complex example of a complex type definition—the po element's type (see Listing 2.15). Listing 2.15 Schema Fragment for the Purchase Order Complex Type
<xsd:complexType name="poType">
<xsd:sequence>
<xsd:element name="billTo" type="addressType"/>
<xsd:element name="shipTo" type="addressType"/>
<xsd:element name="order">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="item" type="itemType"
maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
<xsd:attribute name="id" use="required"
type="xsd:positiveInteger"/>
<xsd:attribute name="submitted" use="required"
type="xsd:date"/>
</xsd:complexType>
The poType introduces three interesting aspects of schema:
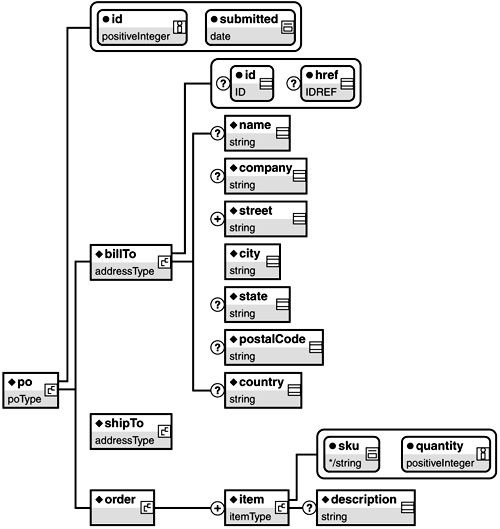
The Purchase Order SchemaWith the information gathered so far, we can completely define the SkatesTown purchase order schema. The document structure tree in Figure 2.4 looks very similar to that from the section on DTDs. The main difference is the presence of more detailed datatype information. Listing 2.16 shows the complete schema. Figure 2.4. Document structure defined by purchase order schema.
Listing 2.16 The Complete SkatesTown Purchase Order Schema (po.xsd)
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns="http://www.skatestown.com/ns/po"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.skatestown.com/ns/po">
<xsd:annotation>
<xsd:documentation xml:lang="en">
Purchase order schema for SkatesTown.
</xsd:documentation>
</xsd:annotation>
<xsd:element name="po" type="poType"/>
<xsd:complexType name="poType">
<xsd:sequence>
<xsd:element name="billTo" type="addressType"/>
<xsd:element name="shipTo" type="addressType"/>
<xsd:element name="order">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="item" type="itemType"
maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
<xsd:attribute name="id" use="required"
type="xsd:positiveInteger"/>
<xsd:attribute name="submitted" use="required"
type="xsd:date"/>
</xsd:complexType>
<xsd:complexType name="addressType">
<xsd:sequence>
<xsd:element name="name" type="xsd:string" minOccurs="0"/>
<xsd:element name="company" type="xsd:string" minOccurs="0"/>
<xsd:element name="street" type="xsd:string"
maxOccurs="unbounded"/>
<xsd:element name="city" type="xsd:string"/>
<xsd:element name="state" type="xsd:string" minOccurs="0"/>
<xsd:element name="postalCode" type="xsd:string"
minOccurs="0"/>
<xsd:element name="country" type="xsd:string" minOccurs="0"/>
</xsd:sequence>
<xsd:attribute name="id" type="xsd:ID"/>
<xsd:attribute name="href" type="xsd:IDREF"/>
</xsd:complexType>
<xsd:complexType name="itemType">
<xsd:sequence>
<xsd:element name="description" type="xsd:string"
minOccurs="0"/>
</xsd:sequence>
<xsd:attribute name="sku" use="required">
<xsd:simpleType>
<xsd:restriction base="xsd:string">
<xsd:pattern value="\d{ 3} -[A-Z]{ 2} "/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
<xsd:attribute name="quantity" use="required"
type="xsd:positiveInteger"/>
</xsd:complexType>
</xsd:schema>
Everything should look familiar except perhaps for the standalone definition of the po element right after the schema annotation. This brings us to the important topic of local versus global elements and attributes. Any element or attribute defined inside a complex type definition is considered local to that definition. Conversely, any element or attribute defined at the top level (as a child of xsd:schema) is considered global. All global elements can be document roots. That is the main reason why most schemas define a single global element. In the case of the SkatesTown purchase order, the po element must be the root of the purchase order document and is hence defined as a global element. The notion of global attributes might not make much sense at first, but they are very convenient. You can use global attributes (in namespace-prefixed form) on any element in a document that allows them. The item priority attribute discussed in the section "XML Namespaces" can be defined with the short schema in Listing 2.17. Listing 2.17 Defining the Priority Global Attribute Using Schema
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns="http://www.skatestown.com/ns/priority"
targetNamespace="http://www.skatestown.com/ns/priority"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<xsd:attribute name="priority" use="optional" default="medium">
<xsd:simpleType>
<xsd:restriction base="xsd:string">
<xsd:enumeration value="low"/>
<xsd:enumeration value="medium"/>
<xsd:enumeration value="high"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
</xsd:schema>
Basic Schema ReusabilityThe concept of reusability is important for XML Schema. Reusability deals with the question of how to best leverage any already created assets in new projects. In schema, the assets include element and attribute definitions, content model definitions, simple and complex datatypes, and whole schemas. We can roughly break down reusability mechanisms into two kinds: basic and advanced. The basic reusability mechanisms address the problems of using existing assets in multiple places. Advanced reusability mechanisms address the problems of modifying existing assets to serve needs that are perhaps different from what they were originally designed for. This section will address the following basic reusability mechanisms:
Element ReferencesIn XML Schema, you can define elements using a name and a type. Alternatively, element declarations can refer to pre-existing elements using the ref attribute of xsd:element as follows, where a globally defined comment element is being reused for both a person and a task complex type:
<xsd:element name="comment" type="xsd:string"/>
<xsd:complexType name="personType">
<xsd:sequence>
<xsd:element name="name" type="xsd:string"/>
<xsd:element ref="comment" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>
<xsd:complexType name="taskType">
<xsd:sequence>
<xsd:element name="toDo" type="xsd:string"/>
<xsd:element ref="comment" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>
Content Model GroupsElement references are perfect for reusing the definition of a single element. However, if your goal is to reuse whole or part of a content model, then element groups are the way to go. Element groups are defined using xsd:group and are referred to using the same mechanism used for elements. The following schema fragment illustrates the concept. It extends the previous example so that instead of a single comment element, public and private comment elements are reused as a group: <xsd:group name="comments"> <xsd:sequence> <xsd:element name="publicComment" type="xsd:string" minOccurs="0"/> <xsd:element name="privateComment" type="xsd:string" minOccurs="0"/> </xsd:sequence> </xsd:group> <xsd:complexType name="personType"> <xsd:sequence> <xsd:element name="name" type="xsd:string"/> <xsd:group ref="comments"/> </xsd:sequence> </xsd:complexType> <xsd:complexType name="taskType"> <xsd:sequence> <xsd:element name="toDo" type="xsd:string"/> <xsd:group ref="comments"/> </xsd:sequence> </xsd:complexType> Attribute GroupsThe same reusability mechanism can be applied to commonly used attribute groups. The following example defines the ID/IDREF combination of an id and href attribute as a referenceable attribute group. It is then applied to both the person and the task type: <xsd:attributeGroup name="referenceable"> <xsd:attribute name="id" type="xsd:ID"/> <xsd:attribute name="href" type="xsd:IDREF"/> </xsd:attributeGroup> <xsd:complexType name="personType"> <xsd:sequence> <xsd:element name="name" type="xsd:string"/> </xsd:sequence> <xsd:attributeGroup ref="referenceable"/> </xsd:complexType> <xsd:complexType name="taskType"> <xsd:sequence> <xsd:element name="toDo" type="xsd:string"/> </xsd:sequence> <xsd:attributeGroup ref="referenceable"/> </xsd:complexType> Schema Includes and ImportsElement references and groups as well as attribute groups provide reusability within the same schema document. However, when you're dealing with very complex schema or trying to achieve maximum reusability, you'll often need to split a schema into several documents. The schema include and import mechanisms allow these documents to reference one another. Consider the scenario where SkatesTown is intent on reusing the schema definition for its address type for a mailing list schema. SkatesTown must solve three small problems:
Pulling the address definition into its own schema is as easy as a simple cut-and-paste operation (see Listing 2.18). Even though this is a different document than the main purchase order schema, they both define portions of the SkatesTown purchase order namespace. The binding between schema documents and the namespaces they define is not one-to-one. It is explicitly identified by the targetNamespace attribute of the xsd:schema element. Listing 2.18 Standalone Address Type Schema
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns="http://www.skatestown.com/ns/po"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.skatestown.com/ns/po">
<xsd:annotation>
<xsd:documentation xml:lang="en">
Address type schema for SkatesTown.
</xsd:documentation>
</xsd:annotation>
<xsd:complexType name="addressType">
<xsd:sequence>
<xsd:element name="name" type="xsd:string" minOccurs="0"/>
<xsd:element name="company" type="xsd:string" minOccurs="0"/>
<xsd:element name="street" type="xsd:string"
maxOccurs="unbounded"/>
<xsd:element name="city" type="xsd:string"/>
<xsd:element name="state" type="xsd:string" minOccurs="0"/>
<xsd:element name="postalCode" type="xsd:string"
minOccurs="0"/>
<xsd:element name="country" type="xsd:string" minOccurs="0"/>
</xsd:sequence>
<xsd:attribute name="id" type="xsd:ID"/>
<xsd:attribute name="href" type="xsd:IDREF"/>
</xsd:complexType>
</xsd:schema>
Referring to this schema is also very easy. Instead of having the address type definition inline, the purchase order schema needs to include the address schema using the xsd:include element. During the processing of the purchase order schema, the address schema will be retrieved and the address type definition will become available (see Listing 2.19). Listing 2.19 Referring to the Address Type Schema
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns="http://www.skatestown.com/ns/po"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.skatestown.com/ns/po">
<xsd:include
schemaLocation="http://www.skatestown.com/schema/address.xsd"/>
...
</xsd:schema>
The mailing list schema is very simple. It defines a single mailingList element that contains any number of contact elements whose type is address. Being an altogether different schema than purchase orders, the mailing list schema uses a new namespace, http://www.skatestown.com/ns/mailingList. Listing 2.20 shows one possible way to define this schema. Listing 2.20 Mailing List Schema
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns="http://www.skatestown.com/ns/po"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.skatestown.com/ns/mailingList">
<xsd:include
schemaLocation="http://www.skatestown.com/schema/address.xsd"/>
<xsd:annotation>
<xsd:documentation xml:lang="en">
Mailing list schema for SkatesTown.
</xsd:documentation>
</xsd:annotation>
<xsd:element name="mailingList">
<xsd:sequence>
<xsd:element name="contact" type="addressType"
minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:element>
</xsd:schema>
This example uses xsd:include to bring in the schema fragment defining the address type. There is no problem with that approach. However, there might be a problem with authoring mailing list documents. The root of the problem is that the mailingList and contact elements are defined in one namespace (http://www.skatestown.com/ns/mailingList), whereas the elements belonging to the address type—name, company, street, city, state, postalCode, country—are defined in another (http://www.skatestown.com/ns/po). Therefore, the mailing list document must reference both namespaces (see Listing 2.21). Listing 2.21 Mailing List that References Two Namespaces
<?xml version="1.0" encoding="UTF-8"?>
<list:mailingList xmlns:list="http://www.skatestown.com/ns/mailingList"
xmlns:addr="http://www.skatestown.com/ns/po"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.skatestown.com/ns/mailingList
http://www.skatestown.com/schema/mailingList.xsd
http://www.skatestown.com/ns/po
http://www.skatestown.com/schema/address.xsd">
<contact>
<addr:company>The Skateboard Warehouse</addr:company>
<addr:street>One Warehouse Park</addr:street>
<addr:street>Building 17</addr:street>
<addr:city>Boston</addr:city>
<addr:state>MA</addr:state>
<addr:postalCode>01775</addr:postalCode>
</contact>
</list:mailingList>
Ideally, when reusing the address type definition in the mailing list schema, we want to hide the fact that it originates from a different namespace and treat it as a true part of the mailing list schema. Therefore, the xsd:include mechanism is not the right one to use, because it makes no namespace changes. The reuse mechanism that will allow the merging of schema fragments from multiple namespaces into a single schema is the import mechanism. Listing 2.22 shows the new mailing list schema. Listing 2.22 Importing Rather Than Including the Address Type Schema
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns="http://www.skatestown.com/ns/po"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:addr="http://www.skatestown.com/ns/po"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.skatestown.com/ns/po
http://www.skatestown.com/schema/address.xsd"
targetNamespace="http://www.skatestown.com/ns/mailingList">
<xsd:import namespace="http://www.skatestown.com/ns/po"/>
<xsd:annotation>
<xsd:documentation xml:lang="en">
Mailing list schema for SkatesTown.
</xsd:documentation>
</xsd:annotation>
<xsd:element name="mailingList">
<xsd:sequence>
<xsd:element name="contact" type="addr:addressType"
minOccurs="0" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:element>
</xsd:schema>
Although the mechanism is simple to describe, it takes several steps to execute:
The net result is that the mailing list instance document has been simplified (see Listing 2.23). Listing 2.23 Simplified Instance Document that Requires a Single Namespace
<?xml version="1.0" encoding="UTF-8"?>
<list:mailingList xmlns:list="http://www.skatestown.com/ns/mailingList"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.skatestown.com/ns/mailingList
http://www.skatestown.com/schema/mailingList.xsd">
<contact>
<company>The Skateboard Warehouse</company>
<street>One Warehouse Park</street>
<street>Building 17</street>
<city>Boston</city>
<state>MA</state>
<postalCode>01775</postalCode>
</contact>
</list:mailingList>
Advanced Schema ReusabilityThe previous section demonstrated how you can reuse types and elements "as is" from the same or a different namespace. This capability can go a long way in some cases, but many real-world scenarios require more sophisticated reuse capabilities. Consider, for example, the format of the invoice that SkatesTown will send to The Skateboard Warehouse based on its purchase order (see Listing 2.24). Listing 2.24 SkatesTown Invoice Document
<?xml version="1.0" encoding="UTF-8"?>
<invoice:invoice xmlns:invoice="http://www.skatestown.com/ns/invoice"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.skatestown.com/ns/invoice
http://www.skatestown.com/schema/invoice.xsd"
id="43871" submitted="2001-10-05">
<billTo id="addr-1">
<company>The Skateboard Warehouse</company>
<street>One Warehouse Park</street>
<street>Building 17</street>
<city>Boston</city>
<state>MA</state>
<postalCode>01775</postalCode>
</billTo>
<shipTo href="addr-1"/>
<order>
<item sku="318-BP" quantity="5" unitPrice="49.95">
<description>Skateboard backpack; five pockets</description>
</item>
<item sku="947-TI" quantity="12" unitPrice="129.00">
<description>Street-style titanium skateboard.</description>
</item>
<item sku="008-PR" quantity="1000" unitPrice="0.00">
<description>Promotional: SkatesTown stickers</description>
</item>
</order>
<tax>89.89</tax>
<shippingAndHandling>200</shippingAndHandling>
<totalCost>2087.64</totalCost>
</invoice:invoice>
The invoice document has many of the features of a purchase order document, with a few important changes:
How can we leverage the work done to define the purchase order schema in defining the invoice schema? This section will introduce the advanced schema reusability mechanisms that make this possible. Design PrinciplesImagine that purchase orders, addresses, and items were represented as classes in an object-oriented programming language such as Java. We could create an invoice object by sub-classing item to invoiceItem (which adds unitPrice) and po to invoice (which adds tax, shippingAndHandling, and totalCost). The benefit of this approach is that any changes to related classes such as address will be automatically picked up by both purchase orders and invoices. Further, any changes in base types such as item will be automatically picked up by derived types such as invoiceItem. The following pseudo-code shows how this approach might work:
class Address { ... }
class Item
{
String sku;
int quantity;
}
class InvoiceItem extends Item
{
float unitPrice;
}
class PO
{
int id;
Date submitted;
Address billTo;
Address shipTo;
Item order[];
}
class Invoice extends PO
{
float tax;
float shippingAndHandling;
float totalCost;
}
Everything looks good except for one important detail. You might have noticed that Invoice probably shouldn't subclass PO. The reason is that the order array inside an invoice object must hold InvoiceItems and not just Item. The subclassing relationship will force you to work with Items instead of InvoiceItems. Doing so will weaken static type-checking and will require constant downcasting, which is generally a bad thing in well-designed object-oriented systems. A better design for the Invoice class, unfortunately, requires some duplication of PO's data members:
class Invoice
{
int id;
Date submitted;
Address billTo;
Address shipTo;
InvoiceItem order[];
float tax;
float shippingAndHandling;
float totalCost;
}
Note that subclassing Item to get InvoiceItem is a good decision because InvoiceItem is a pure extension of Item. It adds new data members; it does not in any way require modifications to Item's data members, nor does it change the way they are used. Extensions and RestrictionsThe analysis from object-oriented systems can be directly applied to the design of SkatesTown's invoice schema. The schema will define the invoice element in terms of pre-existing types such as addressType, and the invoice's item type will reuse the already defined purchase order item type via extension (see Listing 2.25). Listing 2.25 SkatesTown Invoice Schema
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns="http://www.skatestown.com/ns/invoice"
targetNamespace="http://www.skatestown.com/ns/invoice"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:po="http://www.skatestown.com/ns/po">
<xsd:import namespace="http://www.skatestown.com/ns/po"
schemaLocation="http://www.skatestown.cm/schema/po.xsd"/>
<xsd:annotation>
<xsd:documentation xml:lang="en">
Invoice schema for SkatesTown.
</xsd:documentation>
</xsd:annotation>
<xsd:element name="invoice" type="invoiceType"/>
<xsd:complexType name="invoiceType">
<xsd:sequence>
<xsd:element name="billTo" type="po:addressType"/>
<xsd:element name="shipTo" type="po:addressType"/>
<xsd:element name="order">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="item" type="itemType"
maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name="tax" type="priceType"/>
<xsd:element name="shippingAndHandling" type="priceType"/>
<xsd:element name="totalCost" type="priceType"/>
</xsd:sequence>
<xsd:attribute name="id" use="required"
type="xsd:positiveInteger"/>
<xsd:attribute name="submitted" use="required" type="xsd:date"/>
</xsd:complexType>
<xsd:complexType name="itemType">
<xsd:complexContent>
<xsd:extension base="po:itemType">
<xsd:attribute name="unitPrice" use="required"
type="priceType"/>
</xsd:extension>
</xsd:complexContent>
</xsd:complexType>
<xsd:simpleType name="priceType">
<xsd:restriction base="xsd:decimal">
<xsd:minInclusive value="0"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:schema>
By now the schema mechanics should be familiar. The beginning of the schema declares the purchase order and invoice namespaces. The purchase order schema has to be imported because it does not reside in the same namespace as the invoice schema. The invoiceType schema address type is defined in terms of po:addressType, but the order element's content is of type itemType and not po:itemType. That's because the invoice's itemType needs to extend po:itemType and add the unitPrice attribute. This happens at the next complex type definition. In general, the schema extension syntax, although somewhat verbose, is easy to use:
<xsd:complexType name="...">
<xsd:complexContent>
<xsd:extension base="...">
<!-- Optional extension content model -->
<!-- Optional extension attributes -->
</xsd:extension>
</xsd:complexContent>
</xsd:complexType>
The content model of extended types contains all the child elements of the base type plus any additional elements added by the extension. Any attributes in the extension are added to the attribute set of the base type. Last but not least, the invoice schema defines a simple price type as a non-negative decimal number. The definition happens via restriction of the lower bound of the decimal type using the same mechanism introduced in the section on simple types. The restriction mechanism in schema applies not only to simple types but also to complex types. The syntax is similar to that of extension:
<xsd:complexType name="...">
<xsd:complexContent>
<xsd:restriction base="...">
<!-- Content model and attributes -->
</xsd:restriction>
</xsd:complexContent>
</xsd:complexType>
The concept of restriction has a very precise meaning in XML Schema. The declarations of the type derived by restriction are very close to those of the base type but more limited. There are several possible types of restrictions:
For example, you can extend the address type by restriction to create a corporate address that does not include a name:
<xsd:complexType name="corporateAddressType">
<xsd:complexContent>
<xsd:restriction base="addressType">
<xsd:sequence>
<!-- Add maxOccurs="0" to delete optional name element -->
<xsd:element name="name" type="xsd:string"
minOccurs="0" maxOccurs="0"/>
<!-- The rest is the same as in addressType -->
<xsd:element name="company" type="xsd:string"
minOccurs="0"/>
<xsd:element name="street" type="xsd:string"
maxOccurs="unbounded"/>
<xsd:element name="city" type="xsd:string"/>
<xsd:element name="state" type="xsd:string"
minOccurs="0"/>
<xsd:element name="postalCode" type="xsd:string"
minOccurs="0"/>
<xsd:element name="country" type="xsd:string"
minOccurs="0"/>
</xsd:sequence>
<xsd:attribute name="id" type="xsd:ID"/>
<xsd:attribute name="href" type="xsd:IDREF"/>
</xsd:restriction>
</xsd:complexContent>
</xsd:complexType>
The Importance of xsi:typeThe nature of restriction is such that an application that is prepared to deal with the base type can certainly accept the derived type. In other words, you can use a corporate address type directly inside the billTo and shipTo elements of purchase orders and invoices without a problem. There are times, however, when it might be convenient to identify the actual schema type that is used in an instance document. XML Schema allows this through the use of the global xsi:type attribute. This attribute can be applied to any element to signal its actual schema type, as Listing 2.26 shows. Listing 2.26 Using xsi:type
<?xml version="1.0" encoding="UTF-8"?>
<po:po xmlns:po="http://www.skatestown.com/ns/po"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.skatestown.com/ns/po
http://www.skatestown.com/schema/po.xsd"
id="43871" submitted="2001-10-05">
<billTo xsi:type="po:corporateAddressType">
<company>The Skateboard Warehouse</company>
<street>One Warehouse Park</street>
<street>Building 17</street>
<city>Boston</city>
<state>MA</state>
<postalCode>01775</postalCode>
</billTo>
...
</po:po>
Although derivation by restriction does not require the use of xsi:type, derivation by extension often does. The reason is that an application prepared for the base schema type is unlikely to be able to process the derived type (it adds information) without a hint. But, why would such a scenario ever occur? Why would an instance document contain data from a type derived by extension in a place where a base type is expected by the schema? One reason is that XML Schema allows derivation by extension to be used in cases where it really should not be used, as in the case of the invoice and purchase order datatypes. In these cases, xsi:type must be used in the instance document to ensure successful validation. Consider a scenario where the invoice type was derived by extension from the purchase order type:
<xsd:complexType name="invoiceType">
<xsd:complexContent>
<xsd:extension base="po:poType">
<xsd:element name="tax" type="priceType"/>
<xsd:element name="shippingAndHandling" type="priceType"/>
<xsd:element name="totalCost" type="priceType"/>
</xsd:extension>
</xsd:complexContent>
</xsd:complexType>
Remember, extension does not change the content model of the base type; it can only add to it. Therefore, this definition will make the item element inside invoices of type po:itemType, not invoice:itemType. The use of xsi:type (see Listing 2.27) is the only way to add unit prices to items without violating the validity constraints of the document imposed by the schema. An imperfect analogy from programming languages is that xsi:type provides the true type to downcast to when you are holding a reference to a base type. Listing 2.27 Using xsi:type to Correctly Identify Invoice Item Elements
<order>
<item sku="318-BP" quantity="5" unitPrice="49.95"
xsi:type="invoice:itemType">
<description>Skateboard backpack; five pockets</description>
</item>
<item sku="947-TI" quantity="12" unitPrice="129.00"
xsi:type="invoice:itemType">
<description>Street-style titanium skateboard.</description>
</item>
<item sku="008-PR" quantity="1000" unitPrice="0.00"
xsi:type="invoice:itemType">
<description>Promotional: SkatesTown stickers</description>
</item>
</order>
This example shows a use of xsi:type that comes as a result of poor schema design. If, instead of extending purchase order, the invoice type is defined on its own, the need for xsi:type disappears. However, sometimes even good schema design does not prevent the need to identify actual types in instance documents. Imagine that, due to constant typos in shipping and billing address postal codes, SkatesTown decides to become more restrictive in its document validation. The company defines three types of addresses that can be used in purchase orders and schema. The types have the following constraints:
To get the best possible validation, SkatesTown's applications need to know the exact type of address that is being used in a document. Without using xsi:type, the purchase order and invoice schema will each have to define nine (three squared) possible combinations of billTo and shipTo elements: billTo/shipTo, billTo/shipToUS, billTo/shipToUK, billToUS/shipTo, and so on. It is better to stick with billTo and shipTo and use xsi:type to get exact schema type information. There's MoreThis completes the whirlwind tour of XML Schema. Fortunately or unfortunately, much material useful for data-oriented applications falls outside the scope of what can be addressed in this chapter. Some further material will be introduced throughout the rest of the book as needed. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|