|
|
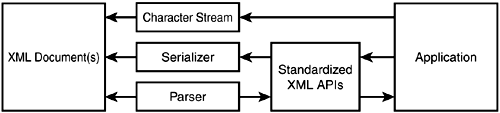
Processing XMLSo far, this chapter has introduced the key XML standards and explained how they are expressed in XML documents. The final section of the chapter focuses on processing XML with a quick tour of the specifications and APIs you need to know to be able to generate, parse, and process XML documents in your Java applications. Basic OperationsThe basic XML processing architecture shown in Figure 2.5 consists of three key layers. At far left are the XML documents an application needs to work with. At far right is the application. In the middle is the infrastructure layer for working with XML documents, which is the topic of this section. Figure 2.5. Basic XML processing architecture.
For an application to be able to work with an XML document, it must first be able to parse it. Parsing is a process that involves breaking up the text of an XML document into small identifiable pieces (nodes). Parsers will break documents into pieces such as start tags, end tags, attribute value pairs, chunks of text content, processing instructions, comments, and so on. These pieces are fed into the application using a well-defined API implementing a particular parsing model. Four parsing models are commonly in use:
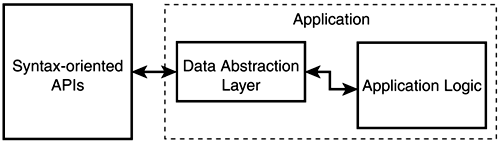
The reasons there are so many different models for parsing XML have to do with trade-offs between memory efficiency, computational efficiency, and ease of programming. Table 2.6 identifies some of the characteristics of the different parsing models. Control of parsing refers to who has to manage the step-by-step parsing process. Pull parsing requires that the application does that. In all other models, the parser will take care of this process. Control of context refers to who has to manage context information such as the level of nesting of elements and their location relative to one another. Both push and pull parsing delegate this control to the application. All other models build a tree of nodes that makes maintaining context much easier. This approach makes programming with DOM or JDOM generally easier than working with SAX. The price is memory and computational efficiency, because instantiating all these objects takes up both time and memory. Hybrid parsers attempt to offer the best of both worlds by presenting a tree view of the document but doing incremental parsing behind the scenes. In the Java world, a standardized API—Java API for XML Processing (JAXP) Although XML parsing addresses the problem of feeding data from XML documents into applications, XML output addresses the reverse problem—applications generating XML documents. At the most basic level, an application can directly output XML markup. In Figure 2.5, this is indicated by the application working with a character stream. This is not very difficult to do, but handling all the basic syntax rules (attributes quoting, special character escaping, and so on) can become cumbersome. In many cases, it might be easier for the application to construct a data structure (DOM or JDOM tree) describing the XML document that should be generated. Then, the application can use a serialization Data-Oriented XML ProcessingWhen you're thinking about applications working with XML, it is important to note that all the mechanisms for parsing and generating XML described so far are syntax-oriented. They force the application to work with concepts such as elements, attributes, and pieces of text. This is similar to applications that use text files for storage being forced to work with characters, lines, carriage returns (CR), and line feeds (LF). Typically, applications want a higher-level view of their data. They are not concerned with the physical structure of the data, be it characters and lines in the case of text files or elements and attributes in the case of XML documents. They want to abstract this away and expose the meaning or semantics of the data. In other words, applications do not want to work with syntax-oriented APIs, they want to work with data-oriented APIs. Therefore, typical data-oriented XML applications introduce a data abstraction layer between the syntax-oriented parsing and output APIs and application logic (see Figure 2.6). Figure 2.6. Data abstraction layer in XML applications.
When working with XML in a data-oriented manner, you'll typically use one of two approaches: operation-centric and data-centric. The operation-centric approach works in terms of custom-built APIs for certain operations on the XML document. The implementation of these APIs hides the details of XML processing. Only non-XML types are passed through the APIs. Consider for example, the task of SkatesTown trying to independently check the total amount on the invoices it is sending to its customers. From a Java application perspective, a good way to implement an operation like this would be through the interface shown in Listing 2.28. Listing 2.28 InvoiceChecker Interface
package com.skatestown.invoice;
import java.io.InputStream;
/**
* SkatesTown invoice checker
*/
public interface InvoiceChecker {
/**
* Check invoice totals.
*
* @param invoiceXML Invoice XML document
* @exception Exception Any exception returned during checking
*/
void checkInvoice(InputStream invoiceXML) throws Exception;
}
The actual implementation of checkInvoice will have to do the following:
The most important aspect to this approach is that any XML processing details will be hidden from the application. It can happily work with the InvoiceChecker interface, never knowing or caring about how checkInvoice does its work. An alternative is the data-centric approach. Data-centric XML computing reduces the problem of working with XML documents to that of mapping the XML to and from application data and then working with the data entirely independent of its XML origins. Application data covers the common datatypes developers work with every day: boolean values, numbers, strings, date-time values, arrays, associative arrays (dictionaries, maps, hash tables), database recordsets, and complex object types. Note that in this context, DOM tree objects will not be considered "true" application data because they are tied to XML syntax. The process of converting application data to XML is called serialization. The XML is a serialized representation of the application data. The process of generating application data from XML is called deserialization For example, the XML invoice markup could be mapped to the set of Java classes introduced in the schema section (see Listing 2.29). Listing 2.29 Java Classes Representing Invoice Data
class Address { ... }
class Item { ... }
class InvoiceItem extends Item { ... }
class Invoice
{
int id;
Date submitted;
Address billTo;
Address shipTo;
InvoiceItem order[];
float tax;
float shippingAndHandling;
float totalCost;
}
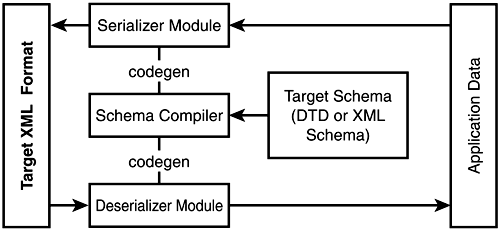
The traditional approach for generating XML from application data has been to sit down and custom-code how data values become elements, attributes, and element content. The traditional approach of working with XML to produce application data has been to parse it using a SAX or a DOM parser. Data structures are built from the SAX events or the DOM tree using custom code. There are, however, better ways to map data to and from XML using technologies specifically built for serializing and deserializing data to and from XML. Enter schema compilation tools. Schema compilers are tools that analyze XML schema and code-generate serialization and deserialization modules specific to the schema. These modules will work with data structures tuned to the schema. Figure 2.7 shows the basic process for working with schema compilers. The schema compiler needs to be invoked only once. Then the application can use the code-generated modules just like any other API. For example, a schema compiler working on the SkatesTown invoice schema could have generated the helper class shown in Listing 2.30 to wrap serialization and deserialization. Figure 2.7. Using a schema compiler.
Listing 2.30 Serialization/Deserialization Helper
class InvoiceXMLHelper
{
// All exception signatures removed for readability
public static InvoiceXMLHelper create();
public serialize(Invoice inv, OutputStream xml);
public Invoice deserialize(InputStream xml);
}
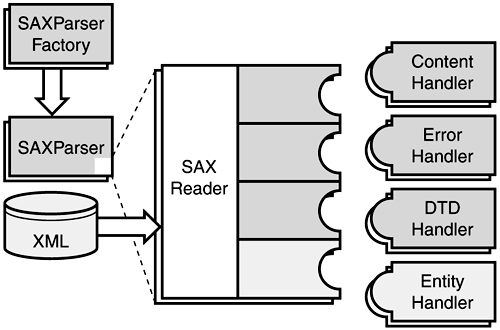
Chapters 3 ("Simple Object Access Protocol (SOAP)") and 4 ("Creating Web Services") will introduce some advanced data mapping concepts specific to Web services as well as some more sophisticated mechanisms for working with XML. The rest of this section will offer a taste of XML processing by implementing the checkInvoice() API described earlier using both a SAX and a DOM parser. SAX-based checkInvoiceThe basic architecture of the JAXP SAX parsing APIs is shown in Figure 2.8. It uses the common abstract factory design pattern. First, you must create an instance of SAXParserFactory that is used to create an instance of SAXParser. Internally, the parser wraps a SAXReader object that is defined by the SAX API. JAXP developers typically do not have to work directly with SAXReader. When the parser's parse() method is invoked, the reader starts firing events to the application by invoking certain registered callbacks. Figure 2.8. SAX parsing architecture.
Working with JAXP and SAX involves four important Java packages:
Here is a summary of the key SAX-related objects:
The following list contains the callback interfaces and some of their important methods:
SAX defines an event-based parsing model. A SAX parser will invoke the callbacks from these interfaces as it is working through the document. Consider the following sample document: <?xml version="1.0" encoding="UTF-8"?> <sampleDoc> <greeting>Hello, world!</greeting> </sampleDoc> An event-based parser will make the series of callbacks to the application as follows: start document start element: sampleDoc start element: greeting characters: Hello, world! end element: greeting end element: sampleDoc end document Because of the simplicity of the parsing model, the parser does not need to keep much state information in memory. This is why SAX-based parsers are very fast and highly efficient. The flip side to this benefit is that the application has to manage any context associated with the parsing process. For example, for the application to know that the string "Hello, world!" is associated with the greeting element, it needs to maintain a flag that is raised in the start element event for greeting and lowered in the end element event. More complex applications typically maintain a stack of elements that are in the process of being parsed. Here are the SAX events with an added context stack: start document () start element: sampleDoc (sampleDoc) start element: greeting (sampleDoc, greeting) characters: Hello, world! (sampleDoc, greeting) end element: greeting (sampleDoc, greeting) end element: sampleDoc (sampleDoc) end document () With this information in mind, building a class to check invoice totals becomes relatively simple (see Listing 2.31). Listing 2.31 SAX-based Invoice Checker (InvoiceCheckerSAX.java)
package com.skatestown.invoice;
import java.io.InputStream;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.helpers.DefaultHandler;
/**
* Check SkatesTown invoice totals using a SAX parser.
*/
public class InvoiceCheckerSAX
extends DefaultHandler
implements InvoiceChecker
{
// Class-level data
// invoice running total
double runningTotal = 0.0;
// invoice total
double total = 0.0;
// Utility data for extracting money amounts from content
boolean isMoneyContent = false;
double amount = 0.0;
/**
* Check invoice totals.
* @param invoiceXML Invoice XML document
* @exception Exception Any exception returned during checking
*/
public void checkInvoice(InputStream invoiceXML) throws Exception {
// Use the default (non-validating) parser
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser saxParser = factory.newSAXParser();
// Parse the input; we are the handler of SAX events
saxParser.parse(invoiceXML, this);
}
// SAX DocumentHandler methods
public void startDocument() throws SAXException {
runningTotal = 0.0;
total = 0.0;
isMoneyContent = false;
}
public void endDocument() throws SAXException {
// Use delta equality check to prevent cumulative
// binary arithmetic errors. In this case, the delta
// is one half of one cent
if (Math.abs(runningTotal - total) >= 0.005) {
throw new SAXException(
"Invoice error: total is " + Double.toString(total) +
" while our calculation shows a total of " +
Double.toString(Math.round(runningTotal * 100) / 100.0));
}
}
public void startElement(String namespaceURI,
String localName,
String qualifiedName,
Attributes attrs) throws SAXException {
if (localName.equals("item")) {
// Find item subtotal; add it to running total
runningTotal +=
Integer.valueOf(attrs.getValue(namespaceURI,
"quantity")).intValue() *
Double.valueOf(attrs.getValue(namespaceURI,
"unitPrice")).doubleValue();
} else if (localName.equals("tax") ||
localName.equals("shippingAndHandling") ||
localName.equals("totalCost")) {
// Prepare to extract money amount
isMoneyContent = true;
}
}
public void endElement(String namespaceURI,
String localName,
String qualifiedName) throws SAXException {
if (isMoneyContent) {
if (localName.equals("totalCost")) {
total = amount;
} else {
// It must be tax or shippingAndHandling
runningTotal += amount;
}
isMoneyContent = false;
}
}
public void characters(char buf[], int offset, int len)
throws SAXException {
if (isMoneyContent) {
String value = new String(buf, offset, len);
amount = Double.valueOf(value).doubleValue();
}
}
}
InvoiceCheckerSAX must implement the InvoiceChecker interface in order to provide the checkInvoice functionality. It also subclasses DefaultHandler to obtain default implementations for all SAX callbacks. In this way the implementation can focus on overriding only the relevant callbacks. The class members runningTotal and total maintain state information about the invoice during the parsing process. The class members isMoneyContent and amount are necessary in order to maintain parsing context. Because events about character data are independent of events about elements, we need a flag to indicate whether we should attempt to parse character data as a dollar amount for the tax, shippingAndHandling, and totalCost elements. This is what isMoneyContent does. After we parse the text into a dollar figure, we save it into the amount member variable and wait until the endElement() callback to determine what to do with it. The checkInvoice() method implementation shows how easy it is to use JAXP for XML parsing. Parsing an XML document with SAX only takes three lines of code. At the beginning of the document, we have to initialize all member variables. At the end of the document, we check whether there is a difference between the running total and the total cost listed on the invoice. If there is a problem, we throw an exception with a descriptive message. Note that we cannot use an equality check because no exact mapping exists between decimal numbers and their binary representation. During the many additions to runningTotal, a very tiny error will be introduced in the calculation. So, instead of checking for equality, we need to check whether the difference between the listed and the calculated totals is significant. Significant in this case would be any amount greater than half a cent, because a half-cent difference can affect the rounding of a final value to a cent. The parser pushes events about the new elements to the startElement() method. If the element we get a notification about is an item element, we can immediately extract the values of the quantity and unitPrice attributes from its attributes collection. Multiplying them together creates an item subtotal, which we add to the running total. Alternatively, if the element is one of tax, shippingAndHandling, or totalCost, we prepare to extract a money amount from its text content. All other elements are simply ignored. We only care to process end element notifications if we were expecting to extract a money amount from their content. Based on the name of the element, we decide whether to save the amount as the total cost of the invoice or whether to add it to the running total. When we process character data and we are expecting a dollar value, we extract the element content, convert it to a double value, and save it in the amount class member for use by the endElement() callback. Note that we could have skipped implementing endElement() altogether if we had also stored the element name as a string member of the class or used an enumerated value. Then, we would have decided how to use the dollar amount right inside characters(). That's all there is to it. Of course, this is a very simple example. A real application would have done at least two things differently:
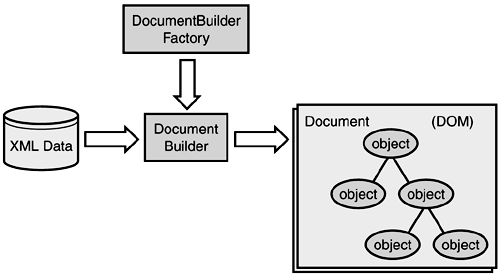
Unfortunately, these extensions fall outside the scope of this chapter. The rest of the book has several examples of building robust XML processing software. DOM-based checkInvoiceThe basic architecture of the JAXP DOM parsing APIs is shown in Figure 2.9. It uses the same factory design pattern as the SAX API. An application will use the javax.xml.parsers.DocumentBuilderFactory class to get a DocumentBuilder object instance, and use that to produce a document that conforms to the DOM specification. The value of the system property javax.xml.parsers.DocumentBuilderFactory determines which factory implementation will produce the builder. This is how JAXP enables applications to work with different DOM parsers. Figure 2.9. DOM parsing architecture.
The important packages for working with JAXP and DOM are as follows:
The DOM defines APIs that allow applications to navigate XML documents and to manipulate their content and structure. The DOM defines interfaces, not a particular implementation. These interfaces are specified using the Interface Description Language (IDL) so that any language can define bindings for them. Separate Java bindings are provided to make working with the DOM in Java very easy. The DOM has several levels and various facets within a level. In the fall of 1998, DOM Level 1 was released. It provided the basic functionality to navigate and manipulate XML and HTML documents. DOM Level 2 builds upon Level 1 with more and better-segmented functionality:
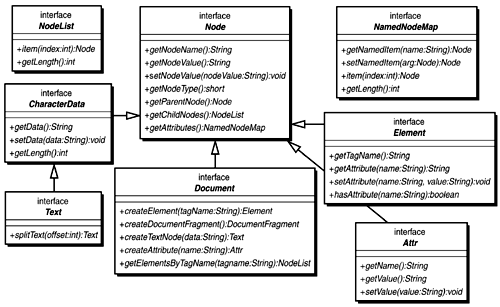
All interfaces apart from the core ones are optional. This is the main reason why most applications choose to rely entirely on the DOM Core. You can expect more of the DOM to be supported by parsers soon. In fact, the W3C is currently working on DOM Level 3. The DOM originated as an API for XML processing at a time when the majority of XML applications were document-centric. As a result, the interfaces in the DOM describe fairly low-level syntax constructs in XML documents. This makes working with the DOM for data-oriented applications somewhat cumbersome, and is one of the reasons the Java community is working on the JDOM APIs. To better understand the XML DOM, you need to understand the core interfaces and the most significant methods in them. Figure 2.10 shows a Universal Modeling Language (UML) diagram describing some of these. Figure 2.10. Key DOM interfaces and operations.
The root interface is Node. It contains methods for working with the node name (getNodeName()), type (getNodeType()), and attributes (getNodeAttributes()). Node types cover various possible XML syntax elements: document, element, attributes, character data, text node, comment, processing instruction, and so on. All of these are shown in subclass Node but not all are shown in Figure 2.10. To traverse the document hierarchy, nodes can access their parent (getParentNode()) as well as their children (getChildNodes()). Node also has several convenience methods for retrieving the first and last child as well as the previous and following sibling. The most important operations in Document involve creating nodes (at least one for every node type), assembling these nodes into the tree (not shown), and locating elements by name, regardless of their location in the DOM (getElementsByTagName()). This last API is very convenient because it can save you from having to traverse the tree to get to a particular node. The rest of the interfaces on the figure are very simple. Elements, attributes, and character data offer a few methods each for getting and setting their data members. NodeList and NamedNodeMap are convenience interfaces for dealing with collections of nodes and attributes, respectively. What Figure 2.10 does not show is that DOM Level 2 is fully namespace aware and all DOM APIs have versions that take in namespace URIs. Typically, their name is the same as the name of the original API with NS appended, such as Element's getAttributeNS(String nsURI, String localName). With this information in mind, building a class to check invoice totals becomes relatively simple. The DOM implementation of InvoiceChecker is shown in Listing 2.32. Listing 2.32 DOM-based Invoice Checker (InvoiceCheckerDOM.java)
package com.skatestown.invoice;
import java.io.InputStream;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.CharacterData;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
/**
* Check SkatesTown invoice totals using a DOM parser.
*/
public class InvoiceCheckerDOM implements InvoiceChecker {
/**
* Check invoice totals.
*
* @param invoiceXML Invoice XML document
* @exception Exception Any exception returned during checking
*/
public void checkInvoice(InputStream invoiceXML)
throws Exception
{
// Invoice running total
double runningTotal = 0.0;
// Obtain parser instance and parse the document
DocumentBuilderFactory factory =
DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document doc = builder.parse(invoiceXML);
// Calculate order subtotal
NodeList itemList = doc.getElementsByTagName("item");
for (int i = 0; i < itemList.getLength(); i++) {
// Extract quantity and price
Element item = (Element)itemList.item(i);
Integer qty = Integer.valueOf(
item.getAttribute("quantity"));
Double price = Double.valueOf(
item.getAttribute("unitPrice"));
// Add subtotal to running total
runningTotal += qty.intValue() * price.doubleValue();
}
// Add tax
Node nodeTax = doc.getElementsByTagName("tax").item(0);
runningTotal += doubleValue(nodeTax);
// Add shipping and handling
Node nodeShippingAndHandling =
doc.getElementsByTagName("shippingAndHandling").item(0);
runningTotal += doubleValue(nodeShippingAndHandling);
// Get invoice total
Node nodeTotalCost =
doc.getElementsByTagName("totalCost").item(0);
double total = doubleValue(nodeTotalCost);
// Use delta equality check to prevent cumulative
// binary arithmetic errors. In this case, the delta
// is one half of one cent
if (Math.abs(runningTotal - total) >= 0.005)
{
throw new Exception(
"Invoice error: total is " + Double.toString(total) +
" while our calculation shows a total of " +
Double.toString(Math.round(runningTotal * 100) / 100.0));
}
}
/**
* Extract a double from the text content of a DOM node.
*
* @param node A DOM node with character content.
* @return The double representation of the node's content.
* @exception Exception Could be the result of either a node
* that does not have text content being passed in
* or a node whose text content is not a number.
*/
private double doubleValue(Node node) throws Exception {
// Get the character data from the node and parse it
String value = ((CharacterData)node.getFirstChild()).getData();
return Double.valueOf(value).doubleValue();
}
}
InvoiceCheckerDOM must implement the InvoiceChecker interface in order to provide the checkInvoice functionality. Apart from this, it is a standalone class. Also, note that the class has no member data, because there is no need to maintain parsing context. The context is implicit in the hierarchy of the DOM tree that will be the result of the parsing process. The factory pattern used here to parse the invoice is the same as the one from the SAX implementation; it just uses DocumentBuilderFactory and DocumentBuilder instead. Although the SAX parse method returns no data (it starts firing events instead), the DOM parse() method returns a Document object that holds the complete parse tree of the invoice document. Within the parse tree, the call to getElementsByTagName("item") retrieves a node list of all order items. The loop iterates over the list, extracting the quantity and unitPrice attributes for every item, obtaining an item subtotal, and adding this to the running total. The same getElementsByTagName() API combined with the utility function doubleValue() extracts the amounts of tax, the shipping and handling, and the invoice total cost. Just as in the SAX example, the code has to use a difference check instead of a direct equality check to guard against inexact decimal-to-binary conversions. The class also defines a convenient utility function that takes in a DOM node that should have only character content and returns the numeric representation of that content as a double. Any non-trivial DOM processing will typically require these types of utility functions. It goes to prove that the DOM is very syntax-oriented and not at all concerned about data. That's all there is to it. Of course, this is a very simple example and, just as in the SAX example, a real application would have done at least three things differently:
These changes are not complex, but they would have increased the size and complexity of the example beyond its goals as a basic introduction to DOM processing. Testing the CodeRather than forcing you to set up the Java Runtime Environment (JRE), modify CLASSPATH environment variables, and run examples from the command line, this book has taken a novel, Web-centric approach. All examples are accessible from the book's example Web site. The actual example code is written using Java Server Pages (JSP). JSP allows Java code to be mixed in with HTML for building Web applications. JSP builds on top of the Java servlet standard for building Web components. Java application servers compile JSPs down to servlets. The example code that drives InvoiceCheckerSAX and InvoiceCheckerDOM appears in Listing 2.33. Listing 2.33 JSP Page for Checking Invoices (/ch2/ex1/index.jsp)
<%@ page import="java.io.*,bws.BookUtil,com.skatestown.invoice.*" %>
<HTML>
<HEAD><TITLE>Invoice Checker</TITLE></HEAD>
<h1>Invoice Checker</h1>
<p>This example implements a web form driver for SkatesTowns's invoice
checker. You can modify the invoice on the form if you wish (the
default one is from Chapter 2), select a DOM or SAX parser and perform
a check on the invoice total.</p>
<FORM action="index.jsp" method="POST">
<%
String xml = request.getParameter("xml");
if (xml == null) {
xml = BookUtil.readResource(application,
"/resources/sampleInvoice.xml");
}
%>
<TEXTAREA NAME="xml" ROWS="20" COLS="90"><%= xml%></TEXTAREA>
<P></P>
Select parser type:
<INPUT type="RADIO" name="parserType" value="SAX" CHECKED> SAX
<INPUT type="RADIO" name="parserType" value="DOM"> DOM
<P></P>
<INPUT type="SUBMIT" value=" Check Invoice">
</FORM>
<%
// Check for form submission
if (request.getParameter("xml") != null) {
out.println("<HR>");
// Instantiate appropriate parser type
InvoiceChecker ic;
if (request.getParameter("parserType").equals("SAX")) {
out.print("Using SAX parser...<br>");
ic = new InvoiceCheckerSAX();
} else {
out.print("Using DOM parser...<br>");
ic = new InvoiceCheckerDOM();
}
// Check the invoice
try {
ic.checkInvoice(new StringBufferInputStream(xml));
out.print("Invoice checks OK.");
} catch(Exception e) {
out.print(e.getMessage());
}
}
%>
</BODY>
</HTML>
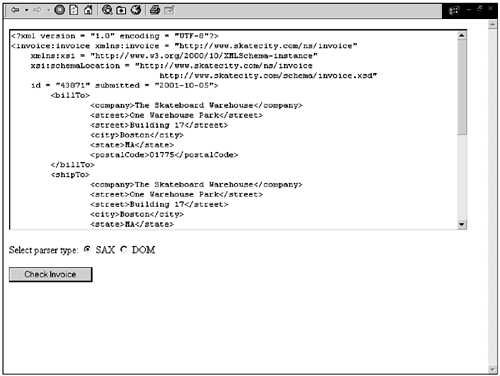
JSP uses the <%@ ... %> syntax for compile-time directives. The page import="..." directive accomplishes the equivalent of a Java import statement. The HTML code sets up a simple Web form that will post back to the same page. The form contains a text area with the name xml that will contain the XML of the invoice to be validated. In JSP, you can use the construct <% ... %> to surround arbitrary Java code embedded in the JSP page. The request object is an implicit object on the page associated with the Web request. Implicit objects in JSP are set up by the JSP compiler. They can be used without requiring any type of declaration or setup. One of the most useful methods of the request object is getParameter(), which retrieves the value of a parameter passed from the Web such as a form field or returns null if this parameter did not come with the request. The code uses getParameter("xml") to check whether the form is being displayed (return is null) versus submitted (return is non-null). If the form is displayed for the first time, the page loads the invoice XML from a sample file in /resources/sampleInvoice.xml. The rest of the Java code runs only if the form has been submitted. It uses the implicit out object to send output to the resulting Web page. It uses the value of the parserType field in the Web page to determine whether to instantiate a SAX or a DOM parser. It then checks the invoice by passing the value of the xml text area on the page to the checkInvoice() method. If the call is successful, the invoice checks OK, and an appropriate message is displayed. If an exception is thrown by checkInvoice(), an invoice total discrepancy (or an XML processing error) has been detected, which will be output to the browser. That's all there is to creating a Web test client for the invoice checker. Figure 2.11 shows the Web page ready for submission. Figure 2.11. Invoice checker Web page.
|
|
|